 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库26年7月2日,全球AI资讯约15条:Loop世界模型论文登顶Hugging Face、a16z领投Probook3400万美元A轮押注家政调度AI等

昨日,AI领域发生了多项重要事件和进展,共计约15条汇总如下。
AI应用进展和演化
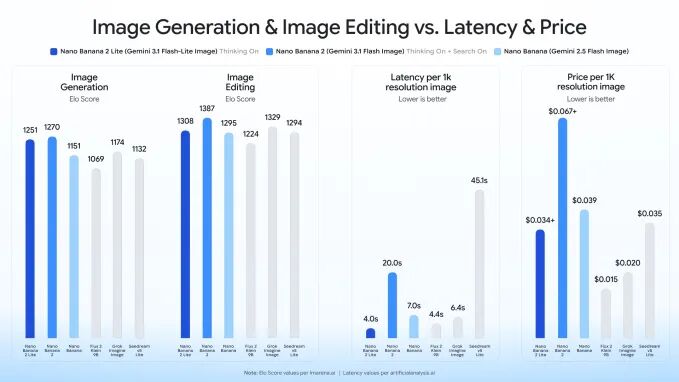
1-1. 谷歌推出 AI 生图模型 Nano Banana 2 Lite:4 秒出图,比标准版更快更便宜
谷歌近日推出轻量级AI图像生成模型“Nano Banana 2 Lite”,主打“快、省、多产”:仅需4秒即可生成一张1024×1024高清图,单图成本低至0.034美元,仅消耗1120个token。相比去年夏季发布的初代Nano Banana和今年2月升级的Nano Banana 2,Lite版专为高频、批量内容生产优化,已全面上线Gemini API等平台,并正式取代初代模型。
与此同时,谷歌扩大了视频生成能力——Gemini Omni Flash现向更多开发者开放,生成视频按秒计费(约0.68元/秒),并配套推出演示工具Omni Product Studio,可将静态图一键转为“电影级”电商短视频。简言之,谷歌正以“图像+视频”双引擎组合,为中小开发者与内容团队提供低成本、高效率的端到端多媒体生成方案。https://www.1ai.net/54399.html
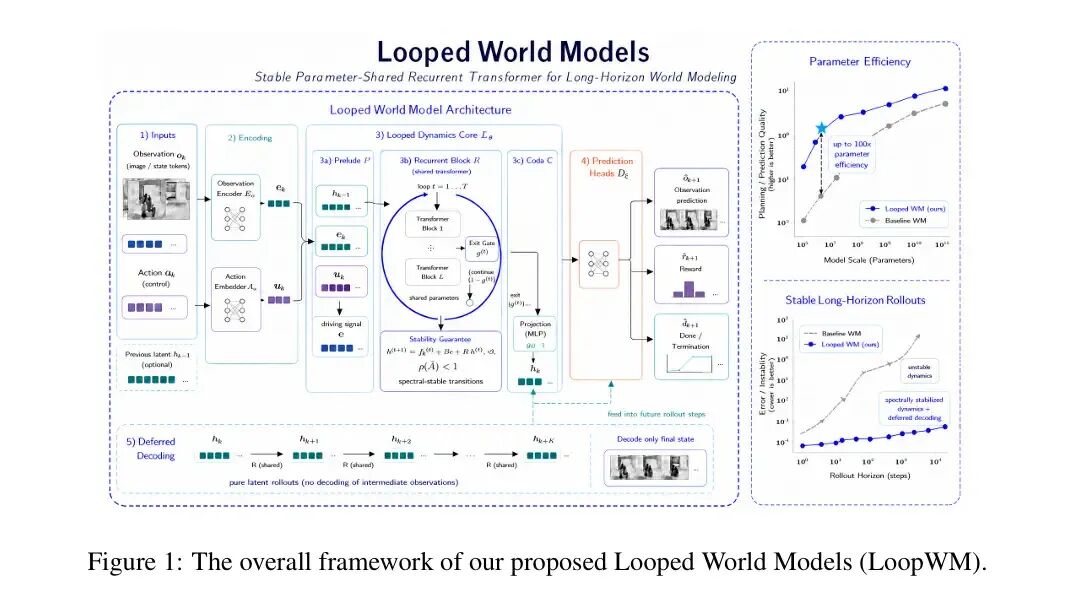
1-2. Loop世界模型论文登顶Hugging Face,来自中国一家初创,周鸿祎陆奇都投了
Looped World Models(LoopWM,循环世界模型),由中国初创公司“脸谱心智”(FaceMind)研发,论文登顶Hugging Face当日论文榜第一。它不是简单优化大模型,而是重构AI“理解世界”的方式:不再靠一次前向推理猜全状态,而是让模型反复迭代细化同一潜空间表示,像人类一样“边想边修正”。
关键数据很亮眼:参数效率提升最高100倍,简单任务单步计算量减少25倍,长时序模拟总计算量节省达两个数量级;在ScienceWorld测试中,性能媲美参数量高100倍的竞品模型。背后是95后博士陆弘远团队提出的“迭代潜空间深度”新扩展维度,兼顾推理精度、成本与稳定性。这项工作标志着AI正从“会执行”迈向“真理解”。https://www.qbitai.com/2026/07/441225.html
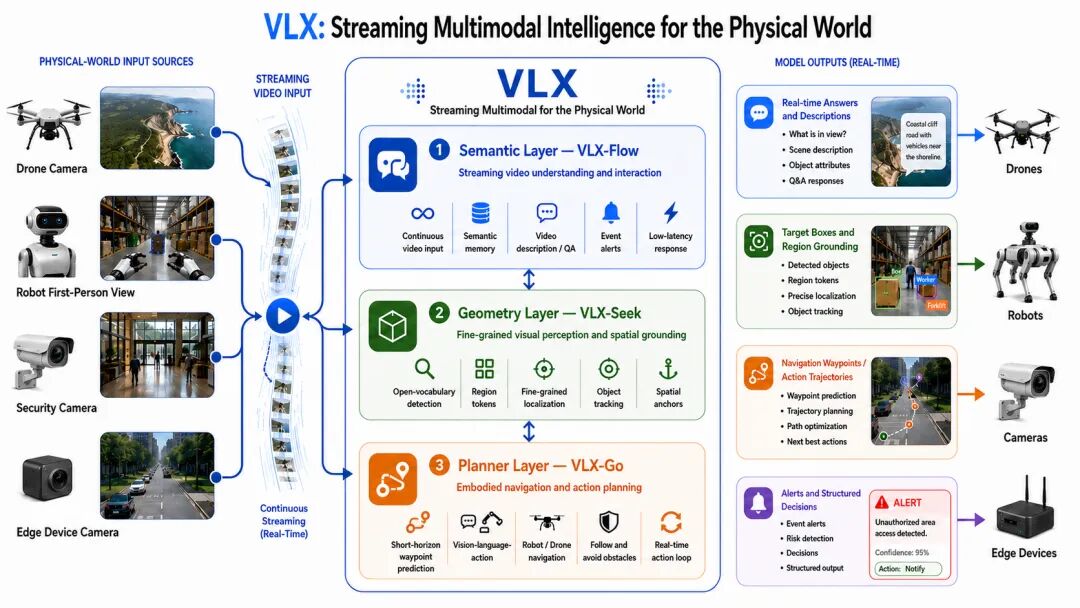
1-3. Om AI联汇发布VLX:全球首个面向物理世界的端侧流式多模态模型
Om AI联汇近日发布VLX系列——全球首个面向物理世界的端侧流式多模态模型,标志着AI从“看图答题”迈向“边看边干”的新阶段。传统模型需将视频切帧后离线处理,而VLX采用“流式编码+增量推理”,实现毫秒级实时响应。该系列包含三款协同模型:VLX-Flow持续感知环境、VLX-Seek以区域检索方式精准定位、VLX-Go直接输出机器人可执行的航点与轨迹,打通“感知→定位→行动”闭环。
模型专为端侧设计,覆盖0.6B至10B参数量,兼顾轻量与能力。它不依赖云端压缩,而是从架构源头适配终端算力受限、环境动态、时间连续的物理世界需求。简单说:VLX让手机、机器人等设备真正“看得清、反应快、动得准”,为具身智能和物理AGI铺下关键基石。https://www.qbitai.com/2026/07/441124.html
1-4. 顶刊生物实验难复现?统一操作话术来了!编译通过率98.6%
过去,AI虽能读论文、设计实验,却卡在“说不清、做不准”上——比如“加5毫升试剂”“37℃培养一段时间”,人类懂,机器懵。结果就是:顶刊论文复现率低,实验室经验难传承,自动化难落地。
中国公司恩和科技破局而出,推出生物学协议语言BPL,让实验步骤变成可编译、可仿真、可验证的“代码”。配套工具BPL-COGEN能自动把自然语言指令(如“做PCR”)转成精准实验代码,并经编译器三轮自动纠错——30篇《Nature Protocols》经典方案测试中,编译通过率达98.6%,98.3%的重复生成结果完全一致。更关键的是,它已落地为全球首个生物制造Physical AI平台SAION AI,单项目日均完成30万组实验,远超人工年均500组。https://www.qbitai.com/2026/06/440630.html
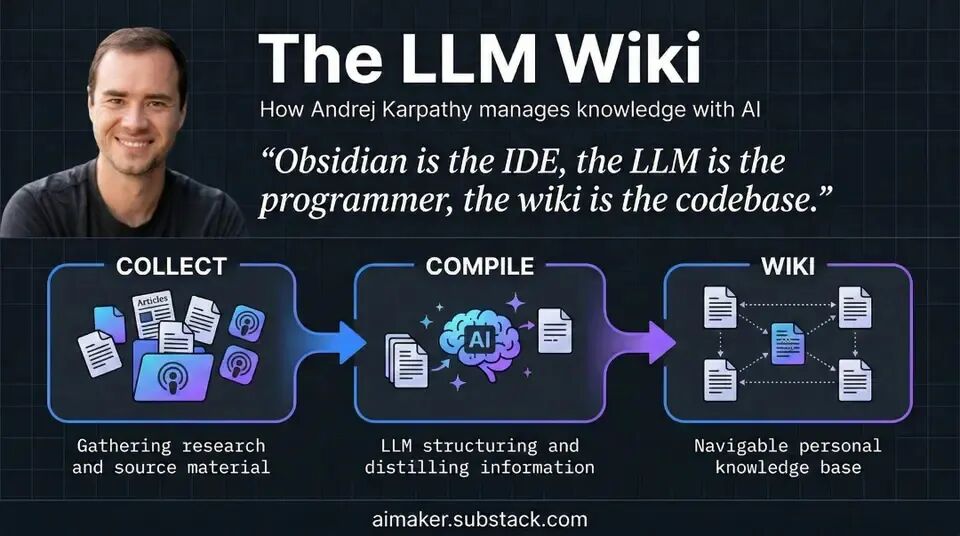
1-5. Karpathy又封神!掀翻RAG,把你的笔记变成第二大脑
Andrej Karpathy提出一个颠覆性知识管理新范式——LLM-Wiki:把个人笔记当作“不可变源代码”,让大模型当“编译器”,一次性将杂乱笔记编译成结构化、自更新、带交叉引用的活体知识库。短短两个月,其开源方案在GitHub获5000+星标,引发Claude等社区静默革命。
相比传统RAG——每次提问都临时“翻找”碎片信息、易矛盾、难维护——LLM-Wiki通过三层架构实现质变:原始笔记(Raw)、知识规则、AI自动维护的Wiki层。用户只需“摄入”新内容、“查询”已编译结果、“体检”知识健康度。AI自动更新页面、标注冲突、加固逻辑,彻底解决知识库“腐烂”难题。这不仅是工具升级,更是认知关系的跃迁:人类专注思考与选择,AI承担所有“记账式劳动”。https://www.163.com/dy/article/L0O8H0TS0511ABV6.html
1-6. Multi-Agent 实测:不会带团队,模型干到死
单个AI(Agent)干复杂活容易卡壳、出幻觉、上下文爆炸;而Multi-Agent就像组建一支AI小队——有人写代码、有人审UI、有人测性能、有人改bug,分工协作、互相纠错。以Kimi K2.6模型为例实测:它用53分钟自主完成一个可交互的浏览器版macOS原型,全程拆解为6类角色、经历迭代优化闭环。背后靠的是256K超长上下文、1T级MoE架构、支持4000步协调与300子Agent调度。
数据显示:在金融引擎优化中,它连续运行13小时、修改4000+行代码、提升吞吐133%;在本地模型推理优化中,12小时完成14轮迭代,速度提升12倍。这说明:未来AI的竞争,不仅是“多聪明”,更是“多会带团队”。组织能力,正成为开源大模型落地产业的新门槛。https://www.leiphone.com/category/industrynews/RTAChbLCPVfJQYm6.html
AI基础设施方面(硬软件、数据)
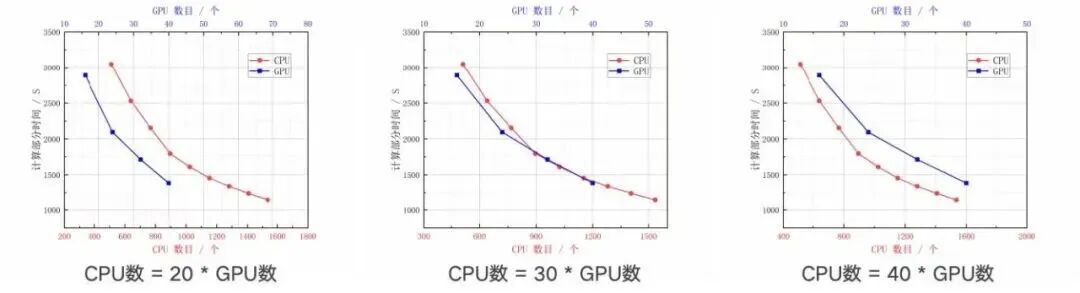
2-1. 40张GPU硬刚1536颗CPU!70岁「古董」代码狂飙数十倍
以海洋模拟软件ROMS为例——它用Fortran编写,已有几十年历史,全球科研机构依赖它预测台风、评估海平面上升,但一次高精度模拟动辄耗时数月。香港科研团队联合是石科技对其优化:将核心计算从CPU迁移到GPU,16张GPU卡仅需519毫秒,而同等任务CPU需16.4秒,提速31.6倍;40张GPU更等效1536个CPU核心,加速达38.4倍。
难点不在硬件,而在工程:Fortran老代码内存按列存储、下标从1起始,与C/GPU习惯截然不同。团队采用“Fortran→C→CUDA”三步法,精准翻译+并行重构,确保3个算例各跑2880步,GPU与CPU结果完全一致。类似方法已推广至气象、CAE仿真等领域,GPU侧最高提速28倍。https://www.163.com/dy/article/L0OPRF3N0511ABV6.html
AI人才和资本动态
3-1. 卡帕西李飞飞辛顿都投了的Transformer专用芯片,签下10亿美元大单
Etched是一家专注Transformer专用AI芯片的硅谷初创公司,由三位哈佛辍学的“00后”天才工程师于2022年创立,获卡帕西、李飞飞、辛顿等AI泰斗投资。公司坚持“专芯专用”,不走通用路线,今年初成功流片首款芯片A0(基于台积电N4P工艺),并已交付首批机柜。
关键突破在于:采用低电压推理(LVI)技术,使芯片在不到常规AI芯片一半电压下运行,浮点运算密度提升数倍;支持万亿参数MoE模型以超80%峰值FLOPs持续运行,无热降频;创新推出集群规模内存(CSM),兼顾高带宽与超低延迟,显著优化长上下文和Agent推理。目前已融资超8亿美元,斩获10亿美元客户订单,团队超400人,来自英伟达、谷歌TPU等顶尖机构。https://www.qbitai.com/2026/07/441183.html

3-2. a16z领投Probook3400万美元A轮押注家政调度AI
a16z近日领投家政服务AI公司Probook 3400万美元A轮融资,释放出一个关键信号:AI投资正从“能说会道”的前台应用,转向更底层、更硬核的线下服务业调度系统。
所谓调度,就是解决“谁去、何时去、先做哪单”三大问题——它直接决定技师利用率、订单响应速度、履约成本和客户满意度。数据显示,家政、维修等上门服务企业中,调度效率每提升10%,人力成本可降5%–8%,接单能力提升15%以上。a16z罕见地在X平台公开强调:“对每一家家庭服务企业而言,dispatch(调度)是最基础、最关键的运营能力。”这标志着资本逻辑的深层迁移:不再只看AI是否“酷”,而是看它能否嵌入真实业务流、优化单位经济模型(如单人日均接单量、客单履约时长)。https://www.unite.ai/zh-cn/probook-raises-34-million-series-a-to-bring-ai-into-the-operational-core-of-home-services/

3-3. 跨维智能又融资10亿,一家定义Physical Token经济学的具身世界模型公司
跨维智能以超10亿元B轮融资、投后估值破百亿的成绩,成为国内少数跻身“百亿独角兽”的物理AI企业,并加速冲刺IPO。其核心竞争力在于:不追风口,而解真题——贾奎教授自21年创立起,就锚定“让AI真正理解三维物理世界”,自主研发DexWorldModel具身世界模型和Dexterity-BEV数据底座,攻克空间感知不准、仿真与实操脱节等行业痛点。
技术实力获硬核验证:在RoboTwin基准中任务成功率94%,WorldArena全球评测夺冠。更关键的是落地实效——已服务超百家企业,落地数十条常态化产线,在美的、中车、海信等500强工厂实现量产:海信装配机器人成功率99.99%,美的分拣效率达人工3倍。全年营收目标3亿元,人形机器人年内出货1000台,全部用于真实作业。https://view.inews.qq.com/k/20260630A06C0F00

3-4. OpenAI联手PE砸下40亿美元,聊聊硅谷最火新职位FDE
硅谷最火的新职业是“前线部署工程师”(FDE)——不是写代码的纯技术岗,而是AI落地的“桥梁型人才”:既懂大模型原理,又深入客户业务一线,把AI从演示变成医生、客服、投行经理真正每天用的AI-native工作流。FDE不是“驻场IT”,而是“Forward Deployed CTO”:既要现场启动PoC、共创用例,又要将实战经验反哺产品迭代。它常与FDPM(前线部署产品经理)搭档——一个攻坚技术实现,一个深耕业务信任。
数据显示,顶尖实验室资深FDE年薪中位数达48.5万美元,顶级岗位甚至突破72.5万美元。热潮背后是战略转向:OpenAI联合19家PE成立超40亿美元“部署公司”,模型厂商不再只卖API,而是亲自下场,帮企业改造流程、验证效果、闭环优化。https://aitntnews.com/newDetail.html?newId=26732
AI风险与政策管理
4-1. 他山科技联合图灵奖得主萨顿共建“机器人幼儿园”,具身智能从“模仿时代”迈向“经验时代”
北京首钢园迎来具身智能发展里程碑事件——全球首个“机器人幼儿园”正式揭牌。该平台由他山科技与2024年图灵奖得主、强化学习之父理查德·萨顿教授团队联合共建,是强化学习理论首次在真实机器人系统上的实体落地。它标志着AI正从依赖人类示范的“数据时代”,迈向机器人自主试错、持续积累经验的“经验时代”。
幼儿园核心理念是“像婴儿一样成长”:以触觉为第一感知通道,提供安全环境、允许犯错、实时反馈和真实交互。目前,他山科技已量产数十万个触觉指尖,应用于全球多款人形机器人。技术上,其电容式触觉可提前预警碰撞,动态触觉时间分辨率达微秒级,支撑长程持续学习。https://www.leiphone.com/category/industrynews/LaVawKu3UpUILUSR.html

4-2. 研究:把 AI 智能体叫做「员工」,会让人类犯更多错误
最近研究揭示,“数字员工”这一流行概念可能带来隐性风险。MIT《技术评论》报道指出,当AI工具被包装成“AI员工”而非普通助手时,人类管理者判断力明显下降:波士顿大学实验显示,识别错误的能力降低18%,近44%的人更愿把问题推给上级,而非主动纠正。
该研究覆盖1261名管理者,其中31%所在企业已将AI正式称为“员工”,23%甚至将其写入组织架构图——但AI并无真实权责能力。诺贝尔经济学奖得主达龙·阿西莫格鲁强调:AI不该被营销为“替代人类的员工”,而应定位为“增强人类的工具”。关键在于,所谓“数字员工”只是品牌话术,不提升技术能力,却会削弱人的责任感与决策力。https://www.1ai.net/54397.html
写在最后
欢迎大家关注、分享、转发本公众号,也欢迎直接与小编联系 对接合作~
小问卷:公众号打分点评





