 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库图灵奖得主LeCun 两连推!LeJEPA 核心作者最新论文,改写 JEPA 表征坍塌困局
点击上方“图灵人工智能”,选择“星标”公众号
您想知道的人工智能干货,第一时间送达

作者丨幸丽娟
编辑丨马晓宁
社交平台 X 上,一项名叫 VISReg 的研究工作,获得图灵奖得主 Yann LeCun 两连推。
能让 LeCun 如此高调背书的 VISReg,究竟做对了什么?
答案很简单:它精准命中LeCun 全力押注的 JEPA 世界模型的核心痛点——表征坍塌。
更难得的是,VISReg 不靠启发式“外挂”,也不依赖海量数据,就在 15 个数据集上,综合表现力压 7 大主流自监督学习算法。

这篇论文的作者团队,也跟LeCun颇有渊源。
二作Randall Balestriero 现任 Brown University计算机科学系的助理教授,曾在Meta的FAIR实验室担任博士后研究员,合作导师正是Yann LeCun,也是LeCun团队此前LeJEPA工作的核心作者之一。

Randall Balestriero 照片
另外两位作者Haiyu Wu(一作)、Morgan Levine(三作)则来自 Altos Labs,这是一家由亚马逊创始人贝索斯等巨头投资的生物技术公司,专注于细胞重编程与衰老研究。
Haiyu Wu Github个人主页

01
嵌入表征坍塌这个“老大难”问题
JEPA 世界模型的底层技术,是 LeCun 早在 2017 年就力推的自监督学习。
这一学习范式,曾凭借“去标注化”为通用 AI 开启了无限可能。
以前训练AI,就像老师给一堆题目,每道题都要配标准答案(人工标注),费时费力还烧钱。
自监督学习不一样:AI自己从海量数据里"找规律"学习,就像学生自己看书悟出道理,不需要每道题都有标准答案。
但这个学习过程,有个棘手的问题:嵌入表征坍塌。
什么意思?AI学到最后学会“偷懒”了——不管输入什么东西,它都输出"差不多一样"的答案。就像学生考试,不管什么题都填"C",看似交卷了,其实啥也没学会。
为了防止这种坍塌,研究者们想了很多办法。
比较经典的一个解决方案,就是 LeCun 团队自己提出来的 VICReg(Variance-Invariance-Covariance Regularization)。把学习目标拆成三项——方差项、不变性项、协方差项。用协方差来限制各个维度"不要太相关"。

但问题在于:协方差只看了"两两之间的关系",就像你只知道班级的平均分和方差,却不知道分数具体分布——两个班级可以均分方差完全一样,但一个全是60-80分,一个全是 0 分和 100 分,天差地别。协方差看不出来这种差别。
后来,LeCun团队又提出了另一个方法 SIGReg(Sketched Isotropic Gaussian Regularization),它基于 Cramér-Wold 定理,通过素描(Sketching) 技术,直接把整个嵌入分布对齐到一个标准高斯分布。这相当于不仅知道班级的均值和方差,还能确保分数分布的形状和正态分布完全一致。

但 SIGReg 也存在两个硬伤:
1.梯度消失陷阱:当嵌入开始坍塌时,SIGReg 的梯度会持续衰减,坍塌越严重,修正信号越微弱,模型彻底失去自救能力,训练直接卡死;
2.“尺度”与“形状”耦合:没有分离特征 “幅度大小(尺度)” 和 “分布形态(形状)” 两个独立属性,这相当于同时调整音量大小和音色,互相干扰,在长尾、低质量、低秩数据集上适配性极差。
02
VISReg 做了什么?
VISReg 对VICReg、SIGReg 进行“扬长避短”,具体的创新在于:
把尺度、形状完全解耦,保留VICReg的方差项来控制尺度(确保每个维度的标准差趋近于1),但用基于切片Wasserstein距离(SWD)的 Sketching Objective 替代协方差项,来控制形状。
这个设计主要体现在三个精妙之处:
▎第一,尺度与形状解耦。
VISReg通过停止梯度(stop-gradient) 把尺度优化和形状优化分离开,互不干扰。就像把音量旋钮和音色旋钮分开,调音量不影响音色,调音色不影响音量。
▎第二,基于SWD的素描目标(Sketching Objective),比协方差更有表达力。
协方差只能控制“两两维度之间是否相关”,而SWD能强制所有投影方向上的完整边缘分布都符合高斯形状。
可以这样理解:协方差只检查“每一对同学的关系是否正常”,而SWD检查“全班在任何一个角度投影过去的分布形状是否合理”——后者要严格得多。
这种方法有个数学上的Cramér-Wold定理撑腰:高维分布的等价性,可以通过检查所有一维随机投影来判断。这意味着SWD约束的是完整分布形状,而非仅仅二阶矩。
▎第三,坍塌时反而更强。
这是最狠的一点:当模型表征已经"塌"了,VISReg的梯度信号反而更强,修正力度更大,能把模型拽回来。
为了证明这一点,论文还进行了模拟实验:让特征范数逐渐减小模拟坍缩,测各方法的梯度强度。VISReg在坍缩最严重时梯度最大,SIGReg梯度趋近零——一个"越危险越使劲救",一个"越危险越躺平"。
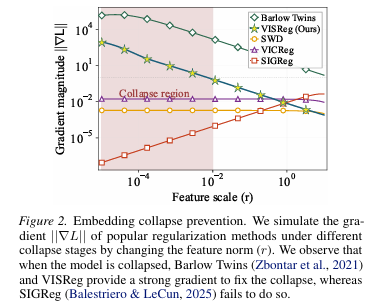
当下热门的 JEPA 世界模型赛道,长期悬而未决的表征坍塌痛点,迎来了突破性的正则化解法。
此外,在计算复杂度、算力成本,VISReg 均实现显著升级:
▎复杂度较 VICReg 大幅降低
VICReg 协方差计算复杂度为O(N D²),其中 D 为嵌入维度,维度越高算力爆炸;VISReg 复杂度为 O(N D K)(N 为 Batch大小,D 为嵌入维度,K 为切片数量),属于线性复杂度,与VICReg的高维算力差距极大。
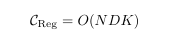
▎速度、内存优于 SIGReg
同等Batch规模下,VISReg 单 H100 GPU 的运行速度、显存占用全面优于SIGReg;分布式多卡训练时,切片任务可均匀分摊至每张显卡,K 切片数量可固定不变,无需随模型、Batch放大同步增加算力。
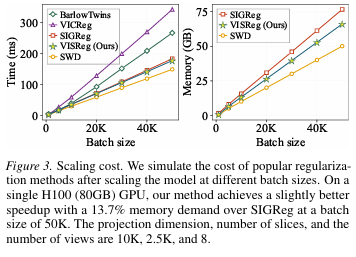
最后在准确度和训练稳定性上,VISReg也更优于VICReg、 SIGReg,尤其是在低质量数据集(ImageNet-LT、Galaxy10)上优势显著。

03
VISReg 到底多强?
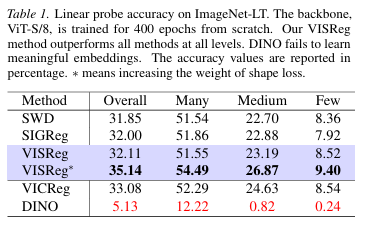
研究团队在 15个数据集(8个 In-Domain 域内数据集+6个 OOD 域外数据集 + 1个 用于稠密实例预测的 ADE20K 数据集)上做了测试,涵盖天文Galaxy、医疗(胸片ChestXRay、眼底 Retina、器官 OrganA)、航拍遥感 AID、花卉Flowers等场景,跟7个标杆级别的自监督学习算法(MoCoV3、DINO、I-JEPA、MAE等)硬刚。
▎In-Domain 数据集:不用"外挂"也能打
为让对比更加公平,实验把算法分为两大组别:带“外挂”组(w/heuristics)和无“外挂”组 (w/o heuristics)。
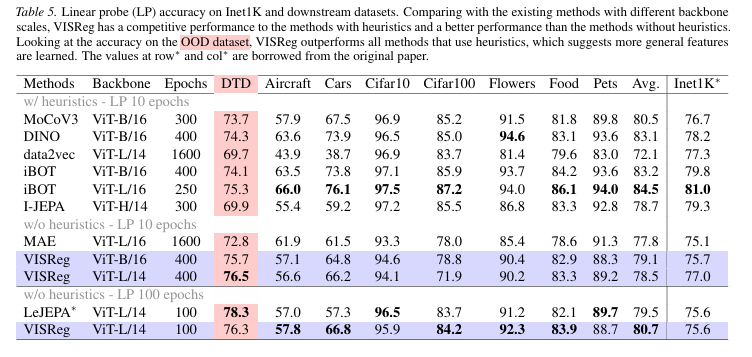
在无启发式“外挂”组,VISReg 表现领先:
同规模下(ViT-B/16):VISReg 域内线性精度达 75.7%,显著超越 MAE(75.1%);
升级规模后(ViT-L/14):VISReg 进一步提升至 77.0%,高于 LeJEPA(75.6%)。
值得强调的是,VISReg 没有用师生网络、EMA、特殊蒸馏这些常见的“炼丹技巧”,纯靠基础训练就把性能拉满了。
跟那些带有启发式"外挂"的算法(iBOT、DINO)比,VISReg在常规任务上只差了一点点。但一到考验真本事的纹理数据集(DTD)上,VISReg直接反超所有带外挂的算法。
这一结果直接表明VISReg的跨域泛化能力是天生优势,而非依赖人工技巧堆砌。
▎OOD 数据集:断层领先
OOD 测试数据集覆盖医疗(胸片ChestXRay、眼底 Retina、器官 OrganA)、天文 Galaxy10、航拍遥感 AID、纹理 DTD,全部和 ImageNet 训练域完全无关。
这就好比:学生在学校学的是“猫、狗、汽车”,考试考的却是“X光片和星空图”——这才是检验真本事的黄金标准。
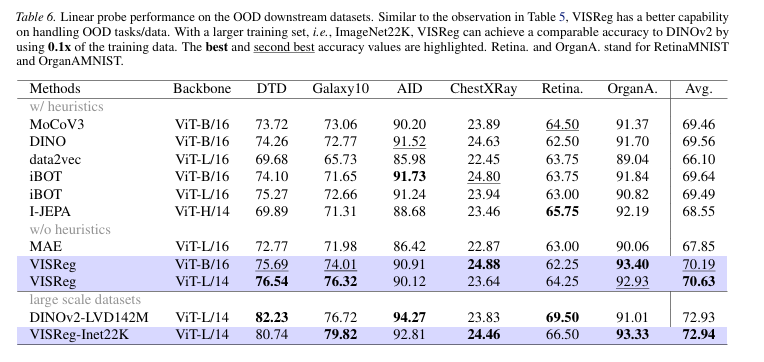
无启发式“外挂”下: ViT-B/16 的VISReg 平均 OOD 精度70.19%,ViT-L/14 达到70.63%,大幅甩开 MAE(67.85%),同时高于大部分带“外挂”的经典算法(MoCoV3 69.46%、DINO 69.56%、I-JEPA 68.55%)。
在Retina、OrganA等数据集优势尤为突出,这也证明VISReg的表征能学到通用底层视觉规律(线条、形状、纹理),而非死记 ImageNet 的自然物体特征。
▎数据效率:10 倍碾压 DINOv2
行业标杆DINOv2用了1.42亿张图训练(LVD142M),VISReg只用了它的十分之一(ImageNet-22K)。
结果呢?
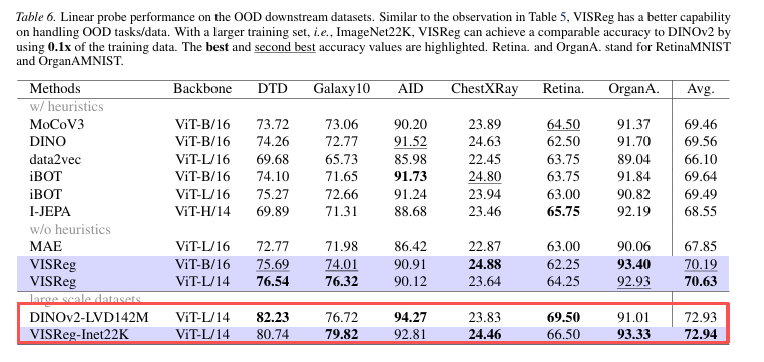
VISReg 精度 72.94%,DINOv2 72.93%——甚至还高了0.01%。
VISReg的学习效率是DINOv2的10倍! 这正好印证了JEPA世界模型路线的核心目标:花小钱办大事。
▎下游迁移学习:微调能力优于 DINO,表征适配性更强
在CIFAR10、CIFAR100、Flowers、ImageNet1K、Galaxy10五套数据集上做微调测试,VISReg的精度全部高于DINO。
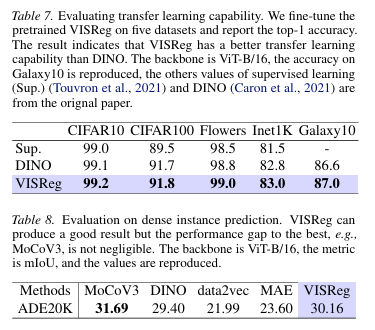
这也说明VISReg学出来的"知识表征"分布更均匀、冗余更低、可塑性更强——不是死记硬背,后续接任何任务上限都更高。
▎稠密实例预测任务:表现稳健

在完全不使用任何启发式“外挂”的前提下,VISReg 在ADE20K上的稠密分割效果仅次于 MoCoV3,远优于 DINO、MAE、data2vec。
论文也坦诚:分割这块离顶尖还有差距,后续会重点优化。
▎图像生成:不仅能当‘尖子生’,还能当‘创作教练’
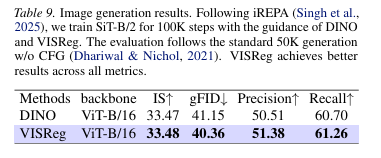
最后,团队还让VISReg和DINO分别当"教练",去指导同一个画图AI(SiT-B/2),完成 10 万步轻量化训练。
四个评分指标中有三个,VISReg 指导出来的画图 AI 都优于 DINO 指导的。
说明VISReg提取的特征不仅能做识别,还能当生成模型的"好教练",帮它加速训练。
总的看下来,VISReg用更朴素的方法(不用外挂)、更少的数据(十分之一)、更稳的训练(越坍缩越自救),在图像识别、分割、生成加速三个维度上都达到了顶尖或接近顶尖的水平。
这也难怪,这项工作能戳中LeCun的心尖~
Paper 链接:
https://arxiv.org/pdf/2606.02572Project
链接:
链接:

文章精选:
1.编程时代已终结!ClaudeCode创始人断言:编程就像发短信一样自然,首曝个人最新工作流:自创Sloop循环,单日PR达150!传统SaaS护城河崩掉





