 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库26年7月3日,全球AI资讯约15条:UC伯克利系主任都加入A社、卷不赢模型 Meta改行「算力包租公」、Verily获3亿美金融资从谷歌独立等

昨日,AI领域发生了多项重要事件和进展,共计约15条汇总如下。
AI应用进展和演化
1-1. 葡萄牙发布首个欧洲葡语开源大语言模型 AMALIA
葡萄牙近日正式发布首个本土开源大语言模型——AMALIA,标志着该国在人工智能领域迈出关键一步。作为国家级战略项目,AMALIA由全国多所高校和研究机构的60多名科学家联合研发,历时18个月,首期投入550万欧元,并依托Deucalion、MareNostrum 5等高性能算力平台。模型以欧洲葡萄牙语为核心,首轮训练使用约4万亿个葡语单词,成功推出90亿参数(9B)基础版本,已具备文本理解与生成能力。
更进一步,AMALIA已完成多模态升级,可同步处理文本、图像和语音信息,显著提升实用性。按计划,今年内还将推出更大规模的220亿参数(22B)版本,并新增“智能体”能力——即能自主规划、调用工具、执行复杂任务。这一升级需追加投资150万欧元。https://www.1ai.net/54447.html

1-2. 全球第一! 中国模型登顶榜首,首个可编辑AI语音来了
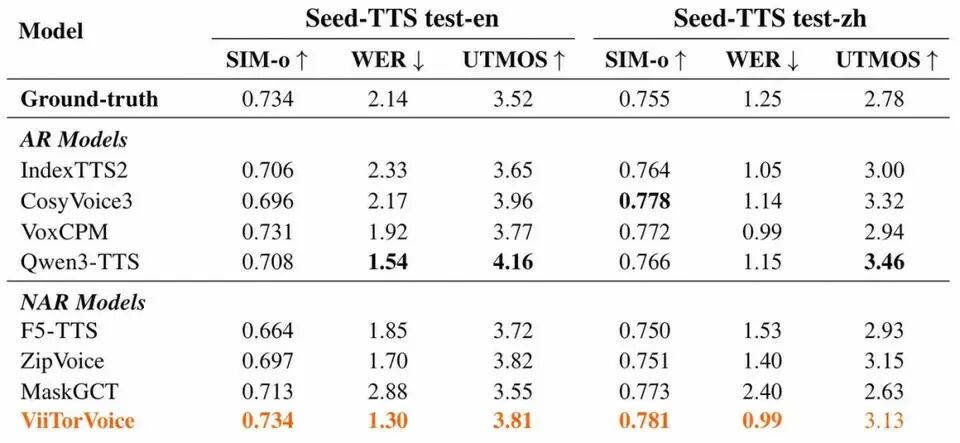
ViiTorVoice是中国团队“云上曲率”研发的全球首个支持局部语音编辑的AI语音模型,近日登顶国际权威评测Seed-TTS榜单,中文词错率(WER)仅0.99、英文仅1.32,成为首个中文WER突破1.0的模型,准确性和稳定性达行业新高。它彻底告别传统TTS“整段重录”的痛点——像修改Word文档一样,可精准替换音频中任意一个词、一句话。
实测中,轻松将哈兰德广告改为“怕饿晕找哈兰德”,把姆巴佩魔性“补水啦~”自然嵌入汽车广告,效果逼真搞笑。其核心技术采用难度更高的非自回归(NAR)架构,推理首帧延迟低于60ms,远快于主流模型(150–200ms)。还支持零样本跨语种克隆、词级情绪控制,已服务短剧出海、有声书、广告等场景,日处理音频超十万小时。https://www.163.com/dy/article/L0R93GMD0511ABV6.html
1-3. 天工AI业务ARR突破8亿美元,向中国首个非BAT10亿美元ARR的AI公司迈进
天工AI近期交出了一份亮眼的商业化成绩单:2026年第二季度,其AI原生业务年度经常性收入(ARR)突破8亿美元,距“中国首个非BAT十亿美元ARR AI公司”仅一步之遥。其中,AI短剧平台DramaWave贡献超7亿美元ARR,AI工具业务也突破1亿美元,展现极强的变现能力。
更关键的是,DramaWave已实现AI原生化转型——80%以上新增短剧由AI自动生成,标志着内容生产正式迈入“AI驱动时代”。在技术侧,其视频模型SkyReels、音乐模型Mureka、游戏世界模型MatrixGame均跻身全球第一梯队;产品矩阵覆盖创作、娱乐、游戏全链条,核心业务连续多季度保持双位数环比增长。天工AI成为少有的实现“模型领先+产品落地+规模营收”闭环的企业。https://www.qbitai.com/2026/07/441786.html
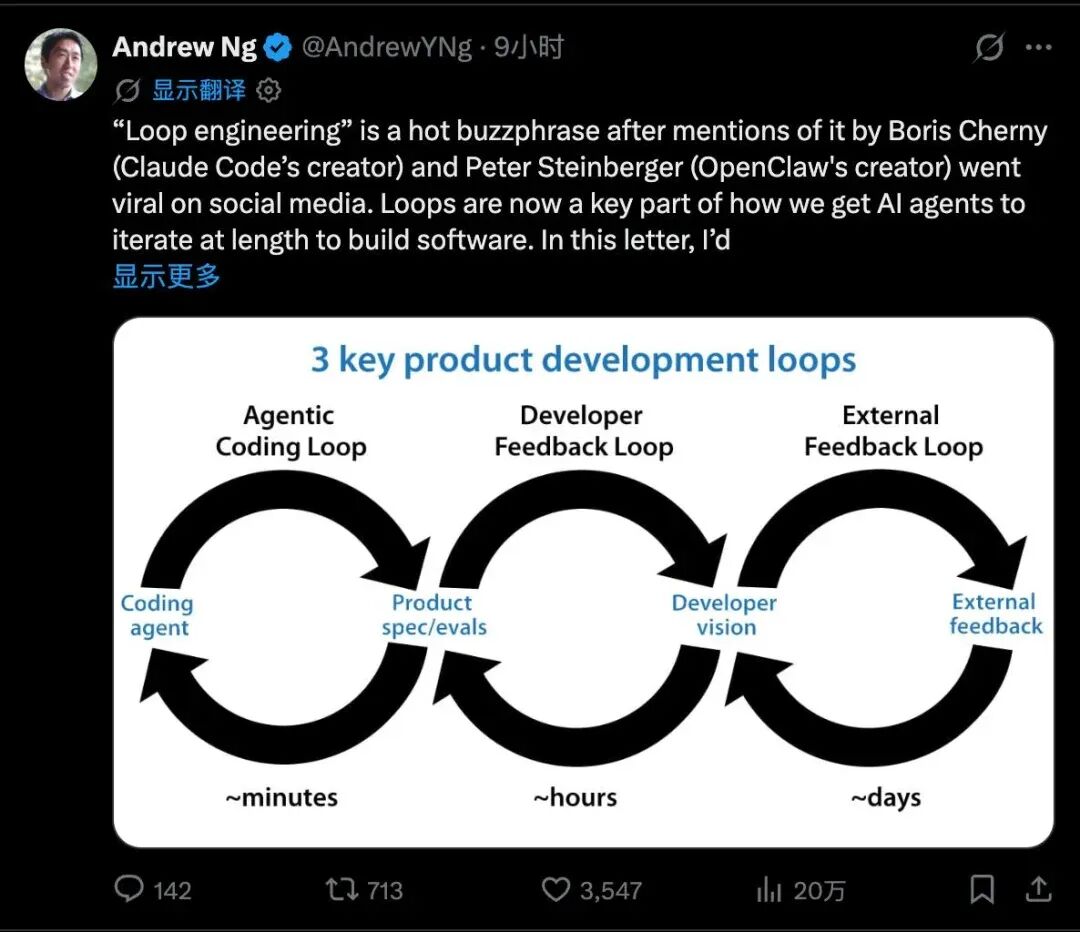
1-4. 吴恩达对 Loop Engineering 的理解真犀利
Andrew Ng 近期提出一个深刻又通俗的“三层循环”(Three-Loop Engineering)模型,重新定义了AI时代的软件开发:
最内层(秒/分钟级):AI Agent 自主写代码、跑测试、调试修复。
中间层(小时级):开发者专注“方向判断”——调整UI、重写需求文档。过去花在找Bug的时间少了,精力转向更高维的产品决策。
最外层(天/周级):真实世界反馈——Beta测试、A/B实验、用户行为数据。它最慢,却最关键:只有上线后才知道设计是否被理解、市场是否已变。
三层环环相扣:外层校准方向,中层翻译为指令,内层高速执行。AI没消除循环,只是把最快那层压缩到分钟级;而真正稀缺的能力,正从“写代码”转向“想清楚问题+定义好任务+听懂真实世界”。https://aitntnews.com/newDetail.html?newId=26787
AI大模型算法、赛事和会议
2-1. 具身智能Skill时刻!英伟达开源机器人技能库,Jim Fan:范式变了
英伟达近日开源机器人新框架ASPIRE,它不像传统训练依赖海量数据和梯度下降,而是让机器人像人类工程师一样:执行任务→回放多模态轨迹→由大模型诊断失败原因→修复控制代码→沉淀为可复用的“Skill”。例如,当机器人因路径规划撞到障碍物失败,ASPIRE会总结出“从45°/90°等多角度重试接近”的技能,后续遇到收音机、微波炉等类似物体均可直接调用。
实验证明,在Robosuite双臂交接任务中,成功率从20%跃升至92%;在泛化测试LIBERO-Pro上,未新增训练的情况下,成功率随技能库扩容从接近0%提升至31%。ASPIRE不产出静态权重,而构建持续进化的“机器人技能库”,真正实现“完成第100个任务时,不再像第1个那样一无所知”。https://www.qbitai.com/2026/07/441396.html
AI基础设施方面(硬软件、数据)
3-1. 金融AI武道大会开赛!四道业务真题,出题人:猜不到最优解
这是一场不拼算力、专攻“真问题”的金融AI实战大赛——AFAC2026金融智能创新大赛。它跳出了刷分式Benchmark,直面金融行业四大落地难题:
① 看盘识人:从海量L2行情中识别机构交易意图(如拆单、挂撤单博弈),考验对市场行为与人性的理解;
② 啃透保险PDF:将含复杂表格、批注的扫描件精准转为结构化Markdown,当前顶尖模型在该任务上平均得分不足0.1,FinixDoc-VL在专属评测集FinixDocBench中达81.43分;
③ 稀疏反馈实验:在有限尝试次数下,让AI像研究员一样优化图学习模型,强调“3B小模型可能比大模型更高效”;
④ 长文精准问答:处理数百页金融文档,既要答案准,更要溯源到具体页码条款,Token消耗被纳入评分。https://www.qbitai.com/2026/07/441246.html

AI人才和资本动态
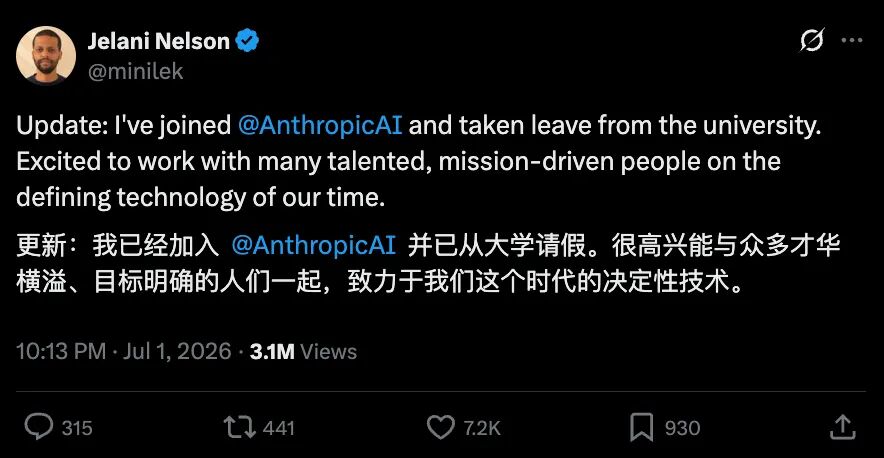
4-1. 人才黑洞!UC伯克利系主任都加入A社了
加州大学伯克利分校EECS系主任、著名理论计算机科学家Jelani Nelson宣布暂离学术岗位,加盟AI公司Anthropic,加入其预训练团队——负责Claude大模型的核心能力研发。这一消息引发广泛关注:Nelson主讲的算法公开课在YouTube播放量超2100万,是公认的“硬核教学顶流”;他博士毕业于MIT,长期深耕高维数据高效处理算法,研究成果曾获MIT杰出博士论文奖。
他的加入,凸显Anthropic对底层算法与数学根基的重视。值得一提的是,Nelson过去5年还兼任谷歌研究科学家,而Anthropic近期已接连吸引多位顶尖人才,包括清华物理学霸姚顺宇等。当前AI竞赛已从工程规模迈向“算法+数学”深度攻坚阶段,高校顶尖学者“下场”一线研发,正成为新趋势。https://www.qbitai.com/2026/07/441447.html
4-2. 97 年大模型专家孙天祥加入百度,任基础模型研发部负责人
95后AI新锐专家孙天祥正式加入百度,担任基础模型研发部(BMU)负责人,并进入百度模型委员会(BMC)。这位年轻专家博士期间主导开发了国内首个类ChatGPT开源大模型MOSS,已在ICML等全球顶级AI会议发表论文超40篇,曾实习于Amazon AI Lab和上海人工智能实验室。
他的加盟,标志着百度在大模型底层技术上的加速布局。目前,百度模型研发体系由两大核心部门构成:孙天祥领衔的基础模型研发部(BMU),聚焦通用大模型架构、训练与推理优化;贾磊负责的应用模型研发部(AMU),则专注行业落地与产品集成。业内人士认为,孙天祥的技术背景——尤其在开源模型、高效训练与前沿算法方面的积累——与百度加大基础模型研发投入的战略高度契合。https://www.1ai.net/54441.html
4-3. 卷不赢模型,Meta改行「算力包租公」!一夜炸崩美股
Meta正式进军云计算市场,推出“Meta Compute”业务,对外出租自建AI算力并提供模型API服务,直接挑战AWS、Azure和谷歌云。此举引爆资本市场:Meta股价单日飙升超10%,市值暴增近980亿美元;而算力服务商CoreWeave暴跌14%、Nebius重挫17%,英伟达等芯片股也应声下跌。
背后底气来自其疯狂投入——2025年资本支出722亿美元,2026年预计达1250–1450亿美元,累计承诺AI基建投资高达1829亿美元。当前,Meta自用算力尚有富余,而外部需求旺盛,顺势变现成为最优解。其商业模式双轨并行:一是低价出租裸算力,二是上线闭源模型Muse Spark等API服务,按Token收费。这不仅是新营收路径,更标志着AI竞赛正从“比模型”转向“拼算力基建”。https://www.163.com/dy/article/L0QNG3B60511ABV6.html
4-4. 硅基流动正式递表港交所,冲刺「AI Token 工厂第一股」
北京硅基流动科技近日正式向港交所递交上市申请。作为国内领先的AI算力服务平台,其核心业务是为大模型开发者提供高效、低成本的Token供应服务。平台注册用户突破1028万,单日平均Token吞吐量高达5785亿。按2025年全年Token吞吐量计算,公司位列中国第四大Token供应平台(市占率1.5%),并在“独立生态类”平台中排名第一。
财务上呈现高增长、高投入特征:2025年收入达5533万元,同比猛增653%;但因持续加大算力基建与技术研发,全年净亏损3.45亿元(为2024年的4.2倍),经调整后净亏损1.87亿元。公司已完成7轮融资,最新估值77.4亿元,股东阵容强大,涵盖阿里、美团、商汤、智谱等产业巨头,以及华为哈勃、创新工场等知名机构。https://www.1ai.net/54443.html

4-5. Base44推出自研氛围编程模型Base1,降低对Anthropic等外部API依赖,降低推理成本
Base44 是一家成立仅半年、团队仅8人的“氛围编程”(vibe-coding)初创公司,去年被Wix以8000万美元收购。如今,它正推出自研轻量级AI模型Base1——基于平台积累的“数千万次真实用户交互”数据训练而成。此举直面AI行业两大关键挑战:通用大模型在垂直场景中延迟高、成本高、适配性弱;以及过度依赖外部模型导致护城河薄弱。
Base44创始人强调,自有模型可优化延迟、降低成本,并更精准匹配用户偏好。目前其年化收入超1.5亿美元(两个月前刚破1亿),虽低于竞对Lovable的5亿美元,但正通过“数据+分发+技术栈”三重整合构建独特壁垒。VC专家指出,企业客户日益关注推理成本,不再盲目追求最先进模型,而是倾向“合适即最优”的模型编排策略。https://news.qq.com/rain/a/20260701A04LEZ00
4-6. Verily获3亿美金融资从谷歌独立,AI健康助手赛道开始进入商业化验证期
Verily曾是Alphabet旗下“最耀眼的医疗明星”:脱胎于Google X,深耕生命科学十余年,布局临床研究平台、慢病管理、可穿戴设备、AI健康助手等十余个方向,技术扎实、资源雄厚。但问题恰恰在于“太全能”——2022财年收入5.59亿美元,却亏损5.68亿美元,暴露出业务分散、缺乏主航道的困境。今年完成3亿美元融资后,Alphabet退居少数股东,Verily正式告别“大厂实验室”。
关键转折是推出消费者端产品Verily Me:整合健康记录、三星手表连续数据、AI助手Violet及临床建议,试图将多年积累的能力收敛为一个用户可感知的入口。但它面临的不是技术挑战,而是医疗商业闭环难题——用户愿不愿长期用?雇主和保险机构愿不愿为效果付费?https://www.zyentor.com/news/4334

4-7. 「华为天才少年」领衔、核心全员清北,Philo AI 完成近千万美金首轮,定义「世界生命模型」新物种
Philo AI 是一家由清华博士、华为“天才少年”张家声创立的AI初创公司,近期完成近千万美元首轮融资。团队堪称“顶配”:核心成员全员清北博士,涵盖多位华为“天才少年”、腾讯技术大咖及大厂资深专家,人均拥有顶尖学术与工程履历——有人17岁入清华、25岁获港大博士;有人曾用一行命令将万卡集群性能提升3倍;还有人主导过5000卡VLLM训练与10PB级数据工程。
他们正在攻关的,是名为“世界生命模型”的全新范式:不是预设脚本的数字人,而是能实时感知、持续记忆、主动行为的“视频原生数字生命”,追求三维统一——身(动态视频形态)、心(情感记忆)、行。其本质是把视频从“生成内容”升级为“始终在线的交互主体”,迈向视频模态的AGI。https://aitntnews.com/newDetail.html?newId=26784
写在最后
欢迎大家关注、分享、转发本公众号,也欢迎直接与小编联系 对接合作~
小问卷:公众号打分点评





