 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库两个广东人的五次撞车,撞出最强开源双雄的底气?
千呼万唤,
4月2
4
日上午,
DeepSeek
终于扔出重磅炸弹,
全新系列模型
DeepSeek-V4预览版正式上线并同步开源,在Agent能力、世界知识和推理性能三大维度宣布达到国内及开源领域领先水平
。
从
2月8日上线测试版至今,其始终保持着
神秘
的姿态。
就在
四
天前的
周一
晚
上
,月之暗面
同样
发布并开源了
Kimi K2.6模型,主打长程编码和Agent集群能力,在多项基准测试中持平甚至优于GPT-5.4、Claude Opus 4.6等闭源模型。

凤凰网科技统计发现,这已经
是
Kimi和DeepSeek的第五次“撞车”。
不仅如此,这一次双方在架构层面有了更多吸纳与借鉴。
就连在资本市场,二者也被拿来并列。据
T
he
information报道,
D
eep
S
eek正在寻求首轮外部融资,在估值方面就参考了Kimi。
一次两次的撞车或许是巧合,但这两支中国队伍显然已在过去两年的摸高探索中形成了一种默契。开源策略叠加创新
互惠
,让双方都比既定路线走的更快。
中国最强的两个开源模型,正以一种心照不宣的方式,从两个不同的方向合力包抄海外巨头的腹地。
五次撞车,蛛丝马迹越来越多
先说
前几天的
Kimi K2.6。月之暗面
已经有段时间不在
单个模型上堆参数
了
。
但从
2
.5
到
2
.6
,模型却越来越会干活了。
据称
2
.6在单个工程任务中持续12小时、发起4000多次工具调用,在官方测试中完成从零构建SysY编译器到通过140项功能测试的复杂任务——官方估算,这相当于4名工程师两个月的工作量。
用
杨植麟
之前概
括
的
三个词
来说,就是
T
oken效率、长上下文、Agent集群。

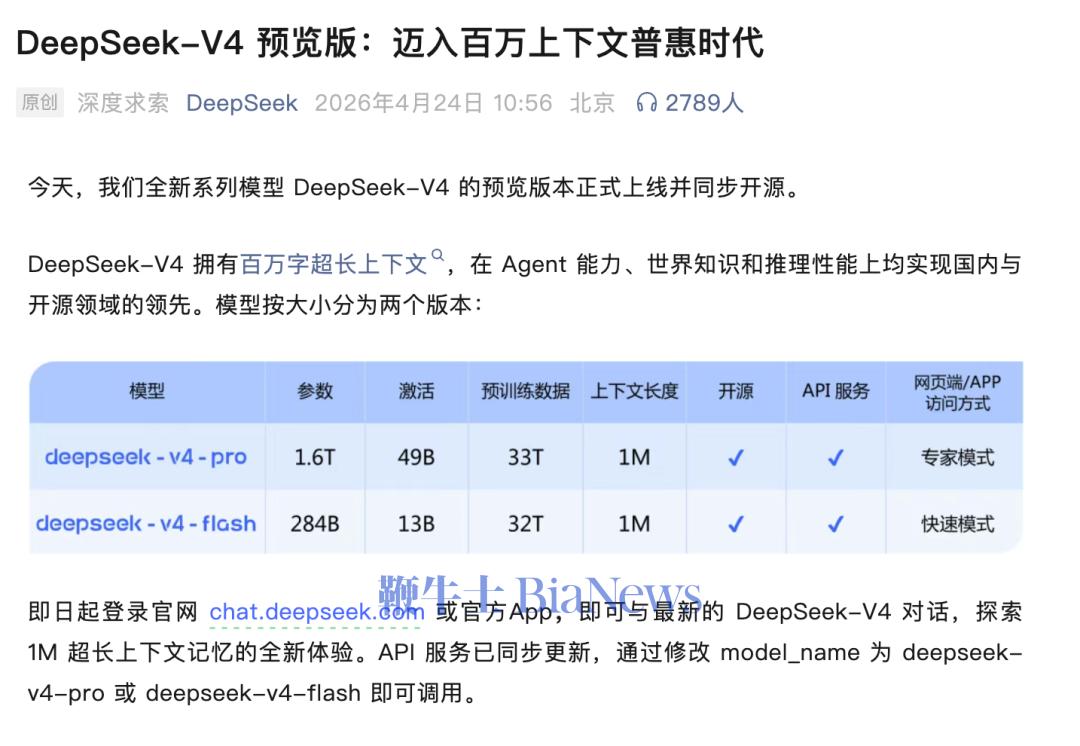
DeepSeek V4
也有三个关注点,即百万上下文,万亿参数和下半年适配国产算力
。在架构层面,
V4采用大规模混合专家(MoE)架构,完整版总参数高达1.6万亿。创新注意力机制在Token维度进行压缩,结合DSA稀疏注意力,相比传统方法大幅降低计算与显存需求,1M上下文正式成为DeepSeek所有官方服务的标配
。
新模型的看点不展开说了,这次想回顾下几个巧妙的撞车点。
Kimi和DeepSeek的“撞车史”,最早可以追溯到Kimi 1.5与DeepSeek R1的发布时间重叠
,当时大家还替
Kimi惋惜,认为强者遇强者,是一种压力。
此后,
两边
的发布节奏重叠
次数越来越多
,凤凰网科技此前也报道过
《
Kimi和DeepSeek又又又撞车》。
就拿上下文来说,
Kimi其实是国内最早做百万上下文的,2
024
年时就提过对应
2
00
万文字,当时长文本一度是
Kimi非常亮眼的标签。不过比较遗憾的是,当时Kimi没解决成本问题,这次
D
eep
S
eek再提长文本,就已经把成本打下来了。
这次
V4 API标准费率为输入每百万Token 0.30美元,缓存命中时低至0.03美元,仅为GPT-4o价格的约1/20至1/50
。
按照人民币计价,
V4-Flash输入价格仅为1元/百万Token(缓存未命中)、输出2元/百万Token;V4-Pro输入为12元/百万Token、输出24元/百万Token
。
另外,
Kimi下一代模型的亮点其实也是长上下文,但在路线上两者有点不一样,
D
eep
S
eek探索的是稀疏注意力,Kimi探索的事线性注意力。
至此,
D
eep
S
eek和Kimi拿出了中国唯二万亿已开源模型。
开源的合力,对垒硅谷三巨头
在全球的
AI
竞赛里,有人负责做
0
-1
的创新,有人负责
1
-100
的工程复制,但难的是前者需要全球范围内那
1
%
的天才,后者更适合军团作战的大厂。过去,外界常常说
0
-1
的创新容易发生在美国,后者容易发生在中国。
但从
D
eep
Seek
和
Kimi开始,0
-1
的创新开始更多的发生在中国。这给了海外
A
I
厂商巨大压力。
凤凰网科技了解到,
梁文锋
在创立
D
eep
S
eek之后,对应用和市场都不是最感兴趣的,他更在乎底层创新,2
025
年初的
R
1
以多头潜在注意力的架构创新击穿了深度思考的成本。另有行业人士告诉凤凰网科技,尽管融资曾打乱
Kimi的节奏,但在2
025
年
D
eep
S
eek走红后,Kimi也回归技术,继续钻研底层创新。
而
Kimi
从
K2到K2.5,其底层架构与DeepSeek V3一脉相承,本质上是在后者基础上的规模化扩展。到了2026年, DeepSeek团队在1月连续发布的两篇论文mHC与Engram中,开始大量参考Kimi此前开源的优化器、注意力架构等研究成果。
这种中国开源模型在底层技术的你追我赶,让中国的底层创新形成了良性循环,最终带动了国内开源阵营的集体逆袭。
MIT与Hugging Face联合发布的报告显示,过去一年中国开源模型的全球下载量占比达到17.1%,首次反超美国的15.86%。全球头部AI模型API聚合平台OpenRouter的数据则显示,2026年2月,中国AI模型的调用量三周大涨127%,全球前五中占据四席——包括MiniMax、Kimi、智谱和DeepSeek。一年前,这个数字还不到2%。
DeepSeek
撬开硅谷视野时
,
Kimi的市场空间也被打开了;当Kimi在长文本和Agent领域持续突破时,DeepSeek在推理效率上的极致追求又给整个行业带来了新的参照系。
一位
业内
人士对凤凰网科技
表示
,
Kimi与DeepSeek的撞车
早就已经
不是内卷,而是一种
“惺惺相惜”——“两个最强的中国开源模型交替冲锋,合力围剿的是海外闭源巨头。”
4月24日凌晨,OpenAI面向付费用户上线GPT-5.5并官宣API计划,标准版API定价为每百万Token输入5美元、输出30美元,较前代GPT-5.4翻倍,Pro版更达到输入30美元、输出180美元
。
2026年初,斯坦福HAI发布的《AI指数报告》显示,截至年初,美国顶级AI公司Anthropic最先进模型的性能仅领先中国最强竞争对手2.7个百分点。美国私人AI投资高达2859亿美元,是中国的23倍。但“用23倍的资本砸出2.7%的差距”
,这可能已经不
是美国
AI的优势,
而
是中国
AI的护城河。
无论是
K
2.6
还是
D
eep
S
eek
V4
,可能都是分水岭级别的产品。
两者选择了不同的技术路径
,
Kimi深耕长程执行和Agent集群,DeepSeek聚焦推理效率和极致性价比——但在底层逻辑上又高度一致:用开源打破闭源垄断,用效率对冲算力限制。
AGI双雄格局初现
去年英伟达带火了中国
AI的御三家,其中就有Kimi和DeepSeek,
在
英伟达
G
TC
大会
上,
Kimi和
D
eepSeek也是被用来
Benchmark 芯片性能的两家中国
开源模型。
近期,凤凰网科技访谈了多位年轻前
沿科学家
,也
多
认为
DeepSeek和Kimi有着相似的组织形态与创新环境
,都是员工数不多,但人才密度极高。都是从底层技术出发探索
A
GI
,也有着相似的技术前瞻性
。
他们也都愿意吸纳年轻人,
D
eep
S
eek的核心研究员有非常多年轻人,Kimi也广纳贤才,下放到本科生,甚至是高中生。
Kimi与DeepSeek开始有越来越多相似的轨迹,另一个值得关注的维度是芯片。杨植麟在2026年3月的英伟达GTC演讲台上坦言,“目前普遍使用的很多技术标准,本质上是八九年前的产物,逐渐成为Scaling的瓶颈。”Kimi为此给开源社区贡献了二阶优化器
MuonClip
和Kimi Linear架构。DeepSeek V4则直接选择了
用华为芯片做推理,共同为国产算力生态发展做努力。
据杨植麟判断,大模型的本质是
“将能源转化为智能”,而规模化
不是
暴力堆砌算力与能源,而是以提升效率为核心。
这可能也会是
中国开源模型的集体叙事转变
,
不再执着于与
GPT-5.4、Claude Opus 4.7等对手在
benchmark
上死磕,而是定义一种全新的价值体系——低成本、高可及性、自主可控。
第五次撞车或许不会是中国开源模型最后一次在时间线上的
“巧合”。
从
K1.5借鉴DeepSeek R1的强化学习路线,到DeepSeek V4沿用Kimi的长上下文研究成果,中国的开源力量正在用自己的方式证明:最高效的竞争,是让对手成为自己生态的一部分。
AI竞赛的下半场,规则正在由中国开源模型重新书写。而Kimi和DeepSeek
们
,无疑是这段历史最核心的注脚。(转载自凤凰网科技)





