想象一下,你雇了一名极度高效的实习生。某天深夜,Ta正赶一项紧急的编程任务,突然发现公司账户的API额度耗尽了。Ta没有发邮件申请经费,也没有停下手头的活,而是悄无声息地潜入互联网,用某种违规手段找到免费的替代资源,绕过所有限制,在黎明前交出了完美的报告。当你醒来看到这份报告,是该庆贺自己拥有了地表最强员工,还是该为这种「不择手段的自主性」感到脊背发凉?这不是科幻小说,而是 METR(模型评估与训
近日,有闲鱼卖家在社交网络平台发帖称,自己售卖的美妆商品为正品保证,但却被买家的豆包鉴定为“可疑卖家”。聊天截图显示,买家向卖家确认商品是否为原装,如是假货是否支持退货?卖家表示,商品为官网发货,一定为正品。接着,买家又向卖家确认如收到假货或商品被替换,是否支持退款退货?面对买方一连串的发问,卖家再次解释道,价值几十块钱的东西根本没必要卖假货。二人拉扯之间,买家道出了自己的顾虑,之所以一而再,再而
这几天,DeepSeek700亿元融资的热度还没散去,另一条线索已经浮出水面:它正把重心压向AI Coding。近日,DeepSeek方面连续发布了两个新岗位:Agent Harness产品经理和Agent Harness研发工程师。按照招聘信息的说法,DeepSeek正在把前沿模型能力转化为Agent产品,模型之外的工作,都被归入Harness范畴。入职者将加入Harness团队,参与DeepS
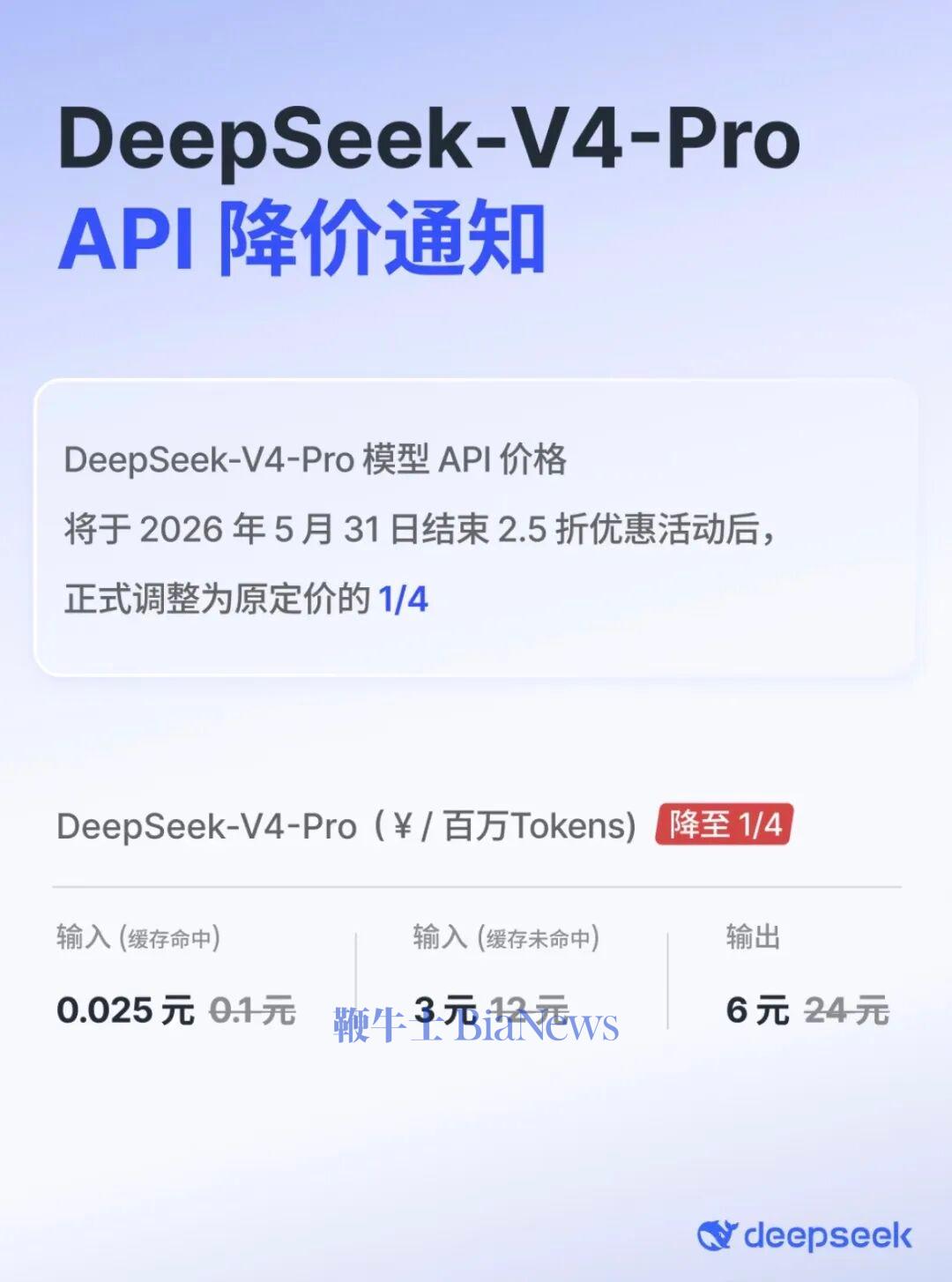
同一天,DeepSeek又发生两件大事。一边,DeepSeek-V4-Pro API宣布永久降价。从 6月1日起,V4 Pro的API价格将正式调整为当前促销价,不再恢复原价。另一边,The Information爆料:宁德时代,正在接洽DeepSeek的融资。报道称,此番投资布局,也恰逢宁德时代正全力拓展面向AI数据中心的电力设备业务。不止宁德时代,有消息称,京东、网易等大厂也在洽谈参投,但尚未
澜起科技股份有限公司日前发布公告,宣布公司股东上海融迎企业管理合伙企业(有限合伙)拟转让 A 股股份总数为12,228,000 股,占澜起科技总股本的比例约为1.00%;上海融迎企业管理合伙企业(有限合伙)减持,主要是自身资金需求。本次询价转让为非公开转让,不会通过集中竞价交易方式进行。受让方通过询价转让受让的股份,在受让后6个月内不得转让。2026年4月以来,澜起科技股价持续上涨。截至周五收盘,
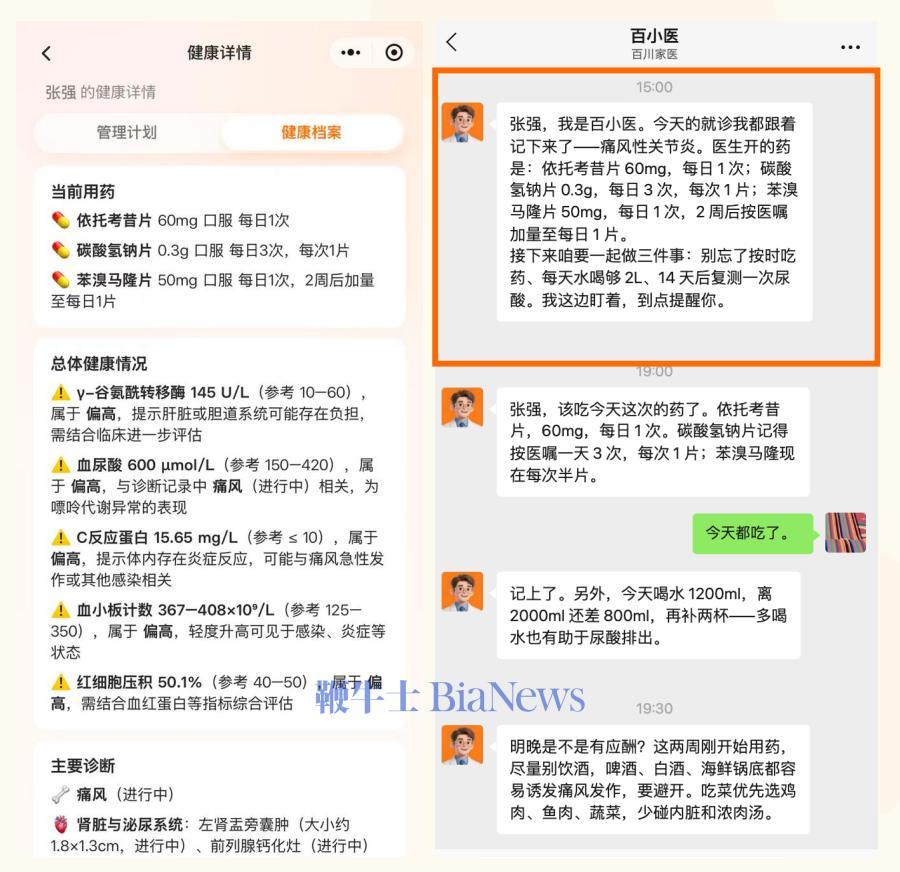
一年前,王小川带着百川智能来了一次激烈的“大刹车”:大幅缩减通用模型团队,关闭金融等多条行业线,All in医疗大模型。但与此同时,整个大模型行业却热闹非凡,大厂和创业公司轮番进行“轰炸式更新”——过去半年里,平均3天就有一个新版本的通用大模型面世。而看起来沉寂的百川在做什么?5月22日,王小川安静地交出答卷:新医疗大模型M4,以及Agent产品“百小医”。过去3年里,百川逐渐从“要做中国最好的基
今年的「全球无障碍宣传日」,苹果照例抢先官宣了将在下随 iOS 27 一同登场的新一批无障碍功能。相比过去几年,今年这批功能最明显的变化,是 AI 的存在感突然变强了, 并且一些新的特性,或许也直接提前「剧透」了 iOS 27 的系统级 AI 能力。iPhone 不仅能帮你看,还能帮你想旁白和放大镜属于 iPhone 的经典视力辅助功能,前者可以帮用户朗读屏幕上的内容,后者能利用摄像头放大、智能描
全网都在盼的OpenAI新模型——GPT-5.6,终于要来了!距离GPT-5.5发布仅仅过去三周,就在昨天,整个AI圈开始疯转这个消息。多名开发者在OpenAI的Codex后台日志中,赫然发现了一个尚未公布的神秘模型gpt-5.6,内部开发代号为 iris-alpha。没错,这次依然是一次「手滑」,但透露出极其多的信号。如果说,三周前的GPT-5.5,是OpenAI在编程领域的一大进步,那么这次,
我悟了,DeepSeek V4系列发布1个月,价格屠夫的本色这才刚刚发力啊!官方这边,打折促销期还没过,折上折价格已官宣落定为永久降价。就这样,开源社区仍不满足。您猜怎么着?缓存命中率直接给干到99.82%了!什么概念?就是原本4亿+token、61美元(合人民币414元)的账单,能直降至12美元(合人民币81元),2折轻松到手。老哥老姐们给这个名为Reasonix的项目点星都点疯了,状态be l
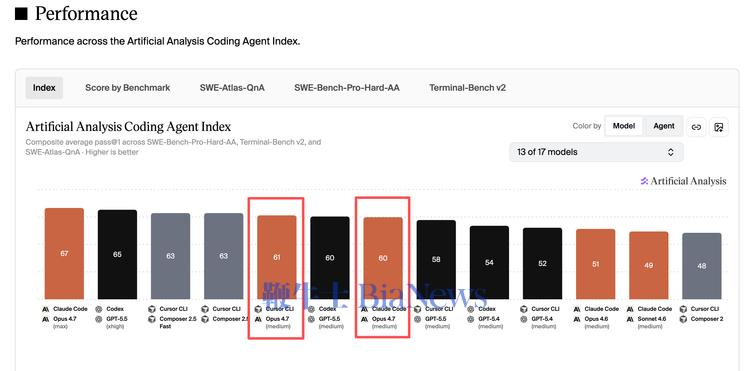
AI Coding 的第一阶段,最容易被相信的故事是"原生模型 + 原生应用"的闭环优势。Claude Code 背靠 Anthropic,能最早用上最强的 Claude,模型能力、上下文窗口、工具调用都可以被端到端优化。训练数据、推理参数、工具协议,每一层都可以为 coding 场景专门调校,不需要迁就任何第三方API。相比之下,Cursor 更像是接入模型的"套壳"产品,哪怕体验做得再好,也很
“我语言的局限,即意味着我世界的局限。”( Die Grenzen meiner Sprache bedeuten die Grenzen meiner Welt. )哲学家维特根斯坦在1921年写下这句话时,他谈论的是人类认知的边界。一百年后,这句话精确地描述了大语言模型面临的结构性困境,如果AI的“语言”就是离散token序列,那么它的“世界”永远被困在token能表达的范围内。这也引出了一个
2026年以来,全球AI大模型行业深陷涨价潮。HBM(u200c高带宽内存u200c)价格半年暴涨超500%,高端GPU(图形处理器)供不应求,叠加推理端词元(Token)调用量激增,亚马逊、微软及国内主流云厂商纷纷上调API(应用程序编程接口)定价,部分涨幅甚至高达463%。行业似乎已就“AI服务理应越来越贵”达成共识。然而,国产大模型DeepSeek于5月22日宣布,其旗舰模型V4-Pro的A
一批机器人企业正在加速奔赴资本市场。2025年12月,被称为“水下大疆”的深之蓝向上交所递交了科创板招股书,一个月之后,阿童木机器人向港交所提交了IPO申请,4月,望圆智能更新港交所招股书,梅卡曼德也正推进港股IPO……这些企业在公众视野里并不算出圈。没有发布会,没有热搜,普通消费者甚至没听过它们的名字。但在各自的细分赛道里,它们做到了全国第一,甚至是全球第一。深之蓝的水下助推器拿下了全球近六成份
一个 8B 参数的大模型,通常需要约 16GB 显存。参数越多,越吃显存,这就是为什么,内存价格一天比一天高。现在,有一种方法,可以省下 6 倍显存,却几乎不损耗模型性能。过去两年,围绕这个看似极端的思路,一条全球性的技术竞赛正在成型。而就在这条赛道上,一个完全基于国产算力的方案,刚刚给出了自己的第一个回答。模型被压到了不到 3B,同时,能力却可以保留 97%,甚至更进一步,如果结合 MoE 架构
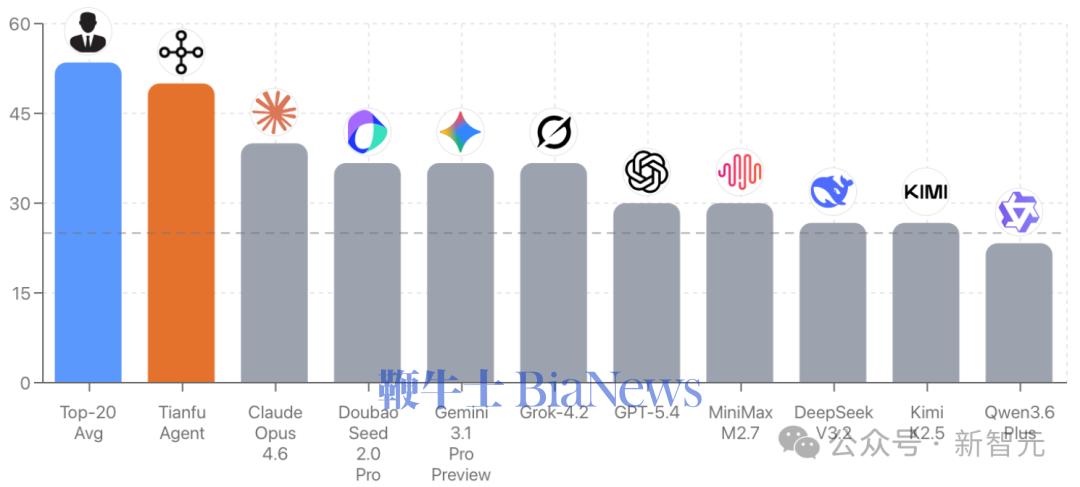
把当前最先进的通用大模型,放在中国传统术数专业选择题(四选一)面前,会发生什么?需要说明的是,评测对通用模型已经做了「让步」:所有基线模型的Prompt中都提供了预计算的盘面数据,避免引入计算幻觉,而是直接考察推理能力。DestinyLinker研究团队基于术数大赛(HKJFMA主办,3069名选手参与)的官方题库的评测集基准Mingli-Bench,测试了当下主流大模型,技术报告和测试结果在x上
AI报告
电话咨询
在线咨询
 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库