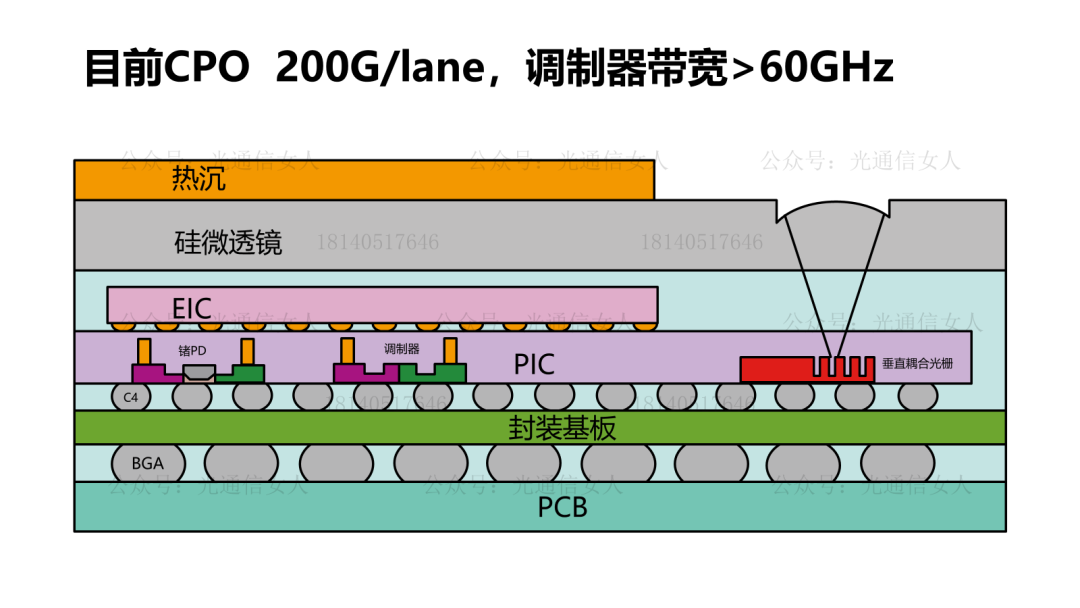
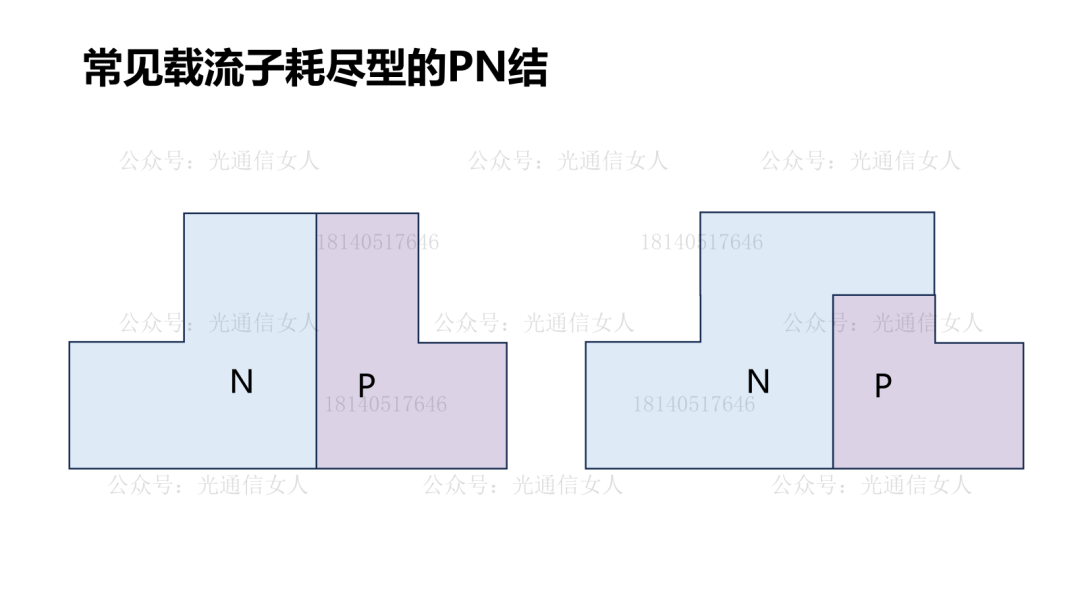
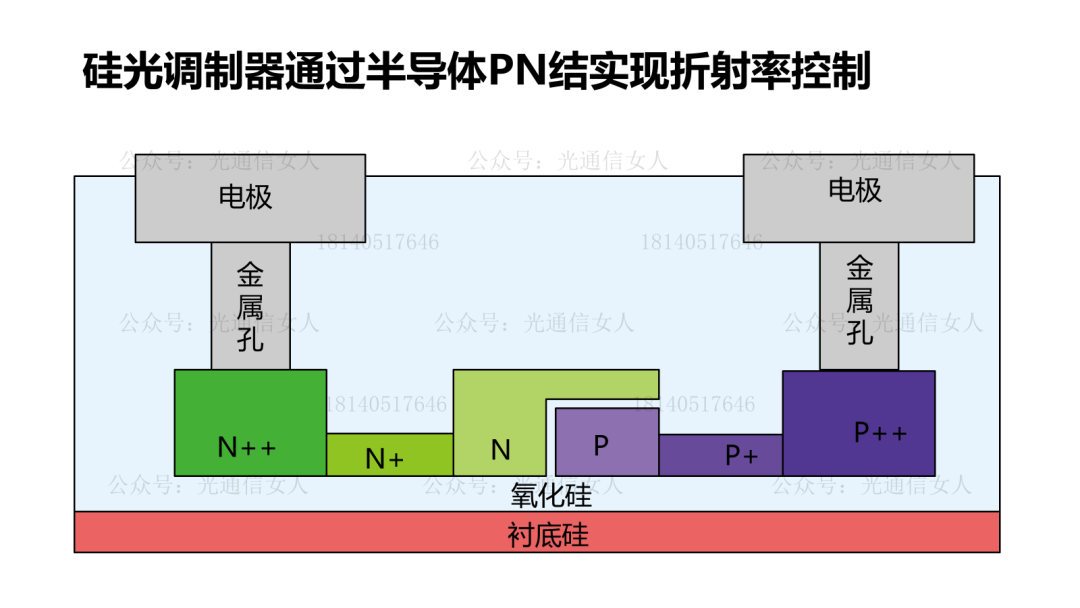
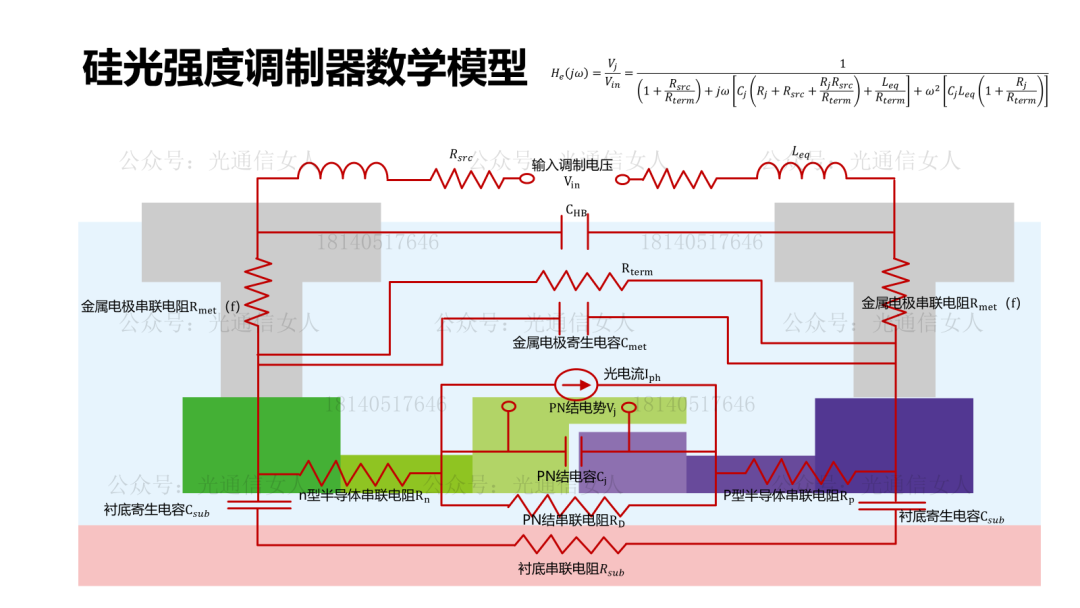
Y12T93 Nvidia:200+Gbps微环调制器的结电容与调制效率
发布时间:2026-04-03来源:光通信女人
Nvidia的硅光CPO选择了微环结构的调制器,今年OFC对微环的性能优化做了很多讨论,之前写了通过微环结构的设计,降低制造工艺误差所引起的微环谐振波长的漂移。- Y12T87 Nvidia:降低微环刻蚀工艺误差产生的波长敏感性
- Y11T92 Nvidia:再谈下一代AI的CPO技术
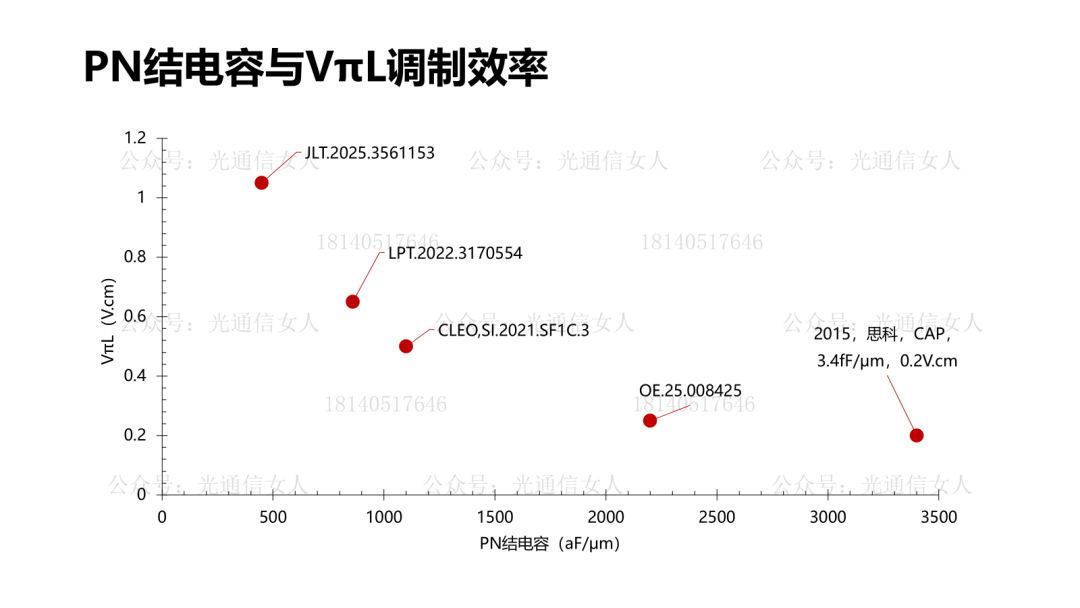
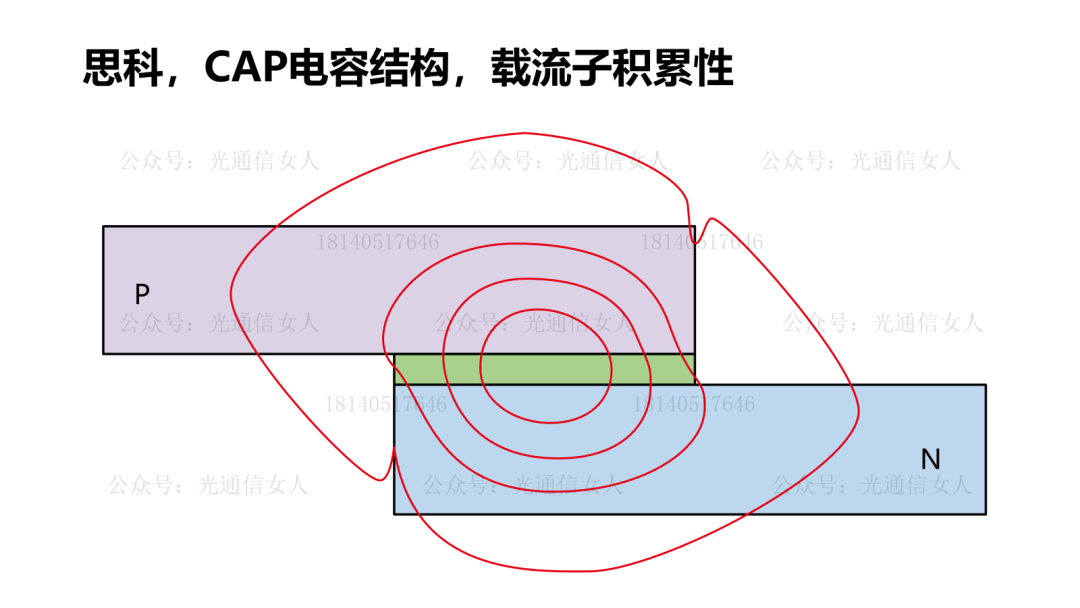
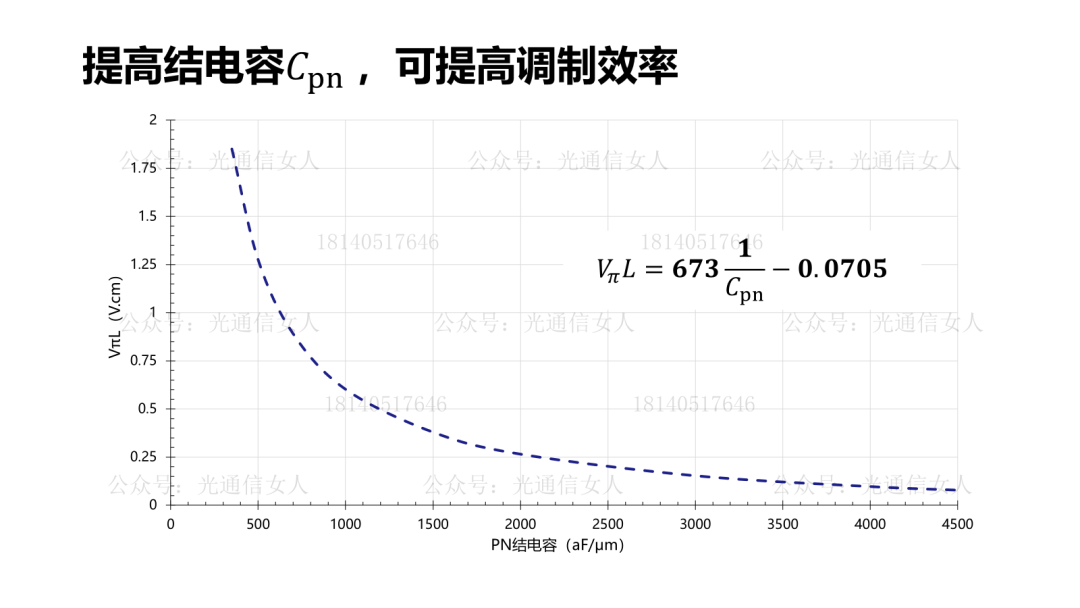
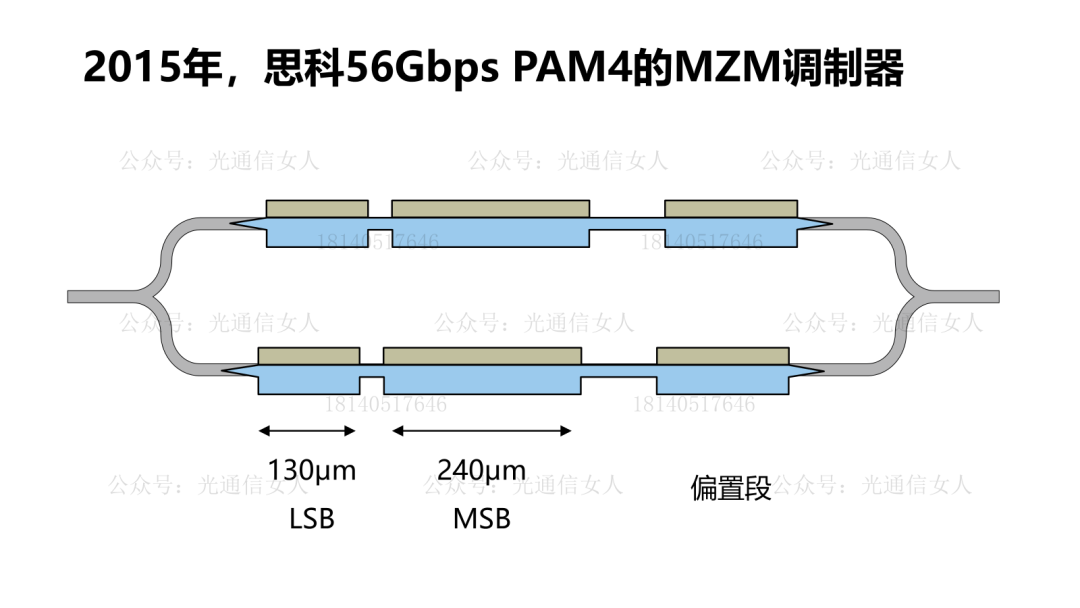
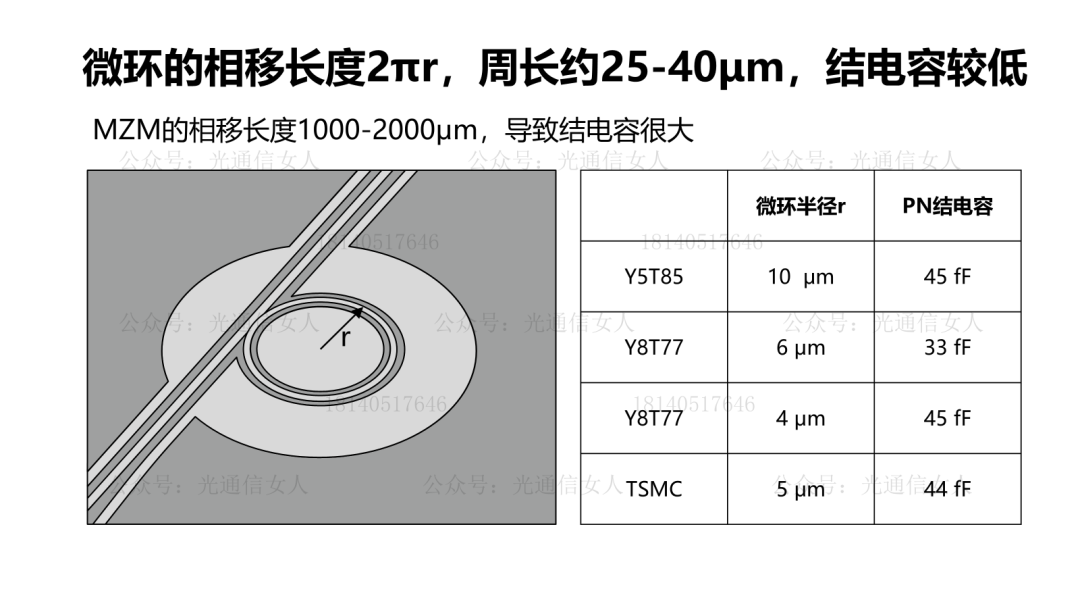
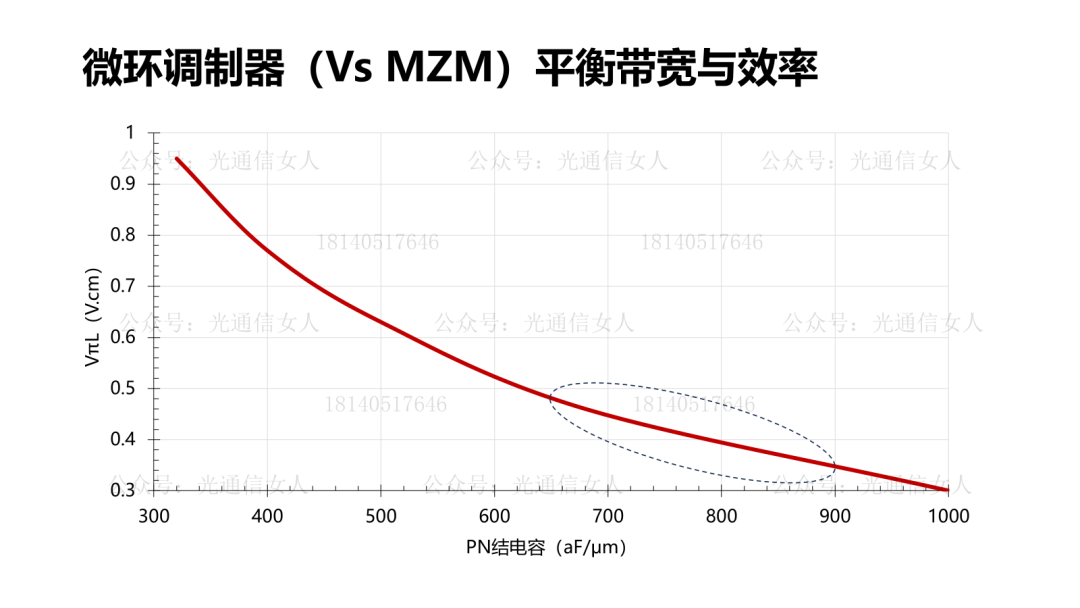
写过Intel、TSMC、三星的硅光平台的带宽性能,MZM调制器带宽50GHz,MRM的调制器带宽则>60GHz。目前大部分的硅光调制器选择载流子耗尽型,相比较注入型与积累性,其结电容相对较低,有利于提高带宽。产业里对硅光集成的强度调制器的数学模型,基本形成共识。Nvidia收集了很多PN结的电容与调制效率VπL的关系,做了一些拟合。前边几个是载流子耗尽型,最后一个做了标注,是思科CAP电容积累性,与其他常用结构不同。这个结构在P型N型半导体之间沉积绝缘层,设计的电容结构,电容很大,调制效率很高,只是带宽较低,这个一会儿聊。回到刚才思科那个带宽较低的说法,降低结电容可提高带宽,结电容过大带宽受限。思科结电容3400aF/μm,也就是3.4fF/μm,其相移长度数百μm,导致电容很大。降低结电容,提高带宽,200Gbps的微环半径4-6μm,周长约30μm,其电容<50fF,可获得较高带宽,并且可获得较高的调制效率,降低VπL。硅MZM调制器,VπL在2V.cm,带宽约50GHz, VπL在0.2V.cm,带宽约19GHz,而微环调制器,VπL为0.35V.cm,带宽约65GHz,相对于MZM结构调制器,可兼顾带宽与效率。4月11日,《人工智能AI大算力驱动的高速光模块/引擎发展趋势》,可详细18140517646
转载说明:本文系转载内容,版权归原作者及原出处所有。转载目的在于传递更多行业信息,文章观点仅代表原作者本人,与本平台立场无关。若涉及作品版权问题,请原作者或相关权利人及时与本平台联系,我们将在第一时间核实后移除相关内容。
 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库