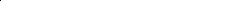五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库筑基AI+:四问智算集群

智算集群正经历从“千卡级”向“万卡级”乃至“十万卡级”的跨越式发展。
伴随全球人工智能产业加速演进,国内基础设施建设正告别粗放式规模扩张,全面迈向智能化升级新阶段。以算力网络、新一代通信网络为核心的信息基础设施,已然成为稳定有效投资、培育壮大新质生产力的关键支撑与核心引擎。智算集群作为 AI 时代的 “超级大脑工厂”,正从单点试点走向规模化落地,成为支撑大模型训练、产业智能化升级的核心底座。
从国家数据局《数字中国建设2025年行动方案》到国务院《关于深入实施“人工智能+”行动的意见》,再到2026年政府工作报告,政策层面已将智算集群建设提升至国家战略高度。《通信产业报》全媒体研究组从“智算集群是什么、关键有哪些、挑战有几个、谁来干”四个维度,深度解析智算集群的发展现状与未来路径。
是什么?
2026年政府工作报告提出“实施超大规模智算集群、算电协同等新基建工程,加强全国一体化算力监测调度,支持公共云发展”。目前,中国已建成42个万卡级智算集群,智能算力总规模超过1590EFLOPS,该体系已被纳入国家“东数西算”工程整体布局。
智算集群是专门用于人工智能(AI)模型训练与推理的高性能计算资源集合,由大量 GPU(或专用 AI 芯片)、高速网络、存储系统和调度软件协同组成,是支撑大模型、生成式 AI、自动驾驶、科学智能等前沿应用的 “数字底座”。作为 AI 产业的核心基础设施,智算集群区别于传统数据中心和通用超算集群,具备高密度算力、极致通信、绿色低碳、软硬协同四大核心特征。
从定义内涵看,智算集群区别于传统数据中心的核心特征在于“三专”:专用AI芯片架构、专用高速互联协议、专用软件栈优化。从技术演进脉络看,智算集群正经历从“千卡级”向“万卡级”乃至“十万卡级”的跨越式发展。从功能定位看,智算集群正在从“算力堆砌”向“智能调度”转变。传统的算力供给模式侧重于硬件堆砌,而新一代智算集群强调软硬件协同优化。

关键有哪些?
智算集群的建设是一项复杂的系统工程,其关键技术可归纳为“算、联、存、调、散”五大核心环节。
AI芯片是智算集群的算力源泉。当前主流路径包括通用GPU(图形处理器)和ASIC(专用集成电路)两大技术路线。目前来看,英伟达凭借CUDA生态在通用GPU领域占据主导地位,而寒武纪等国内企业则聚焦ASIC路线。
通过专用架构实现特定场景的高效计算。华为昇腾系列芯片的技术演进颇具代表性。2025年9月,华为轮值董事长徐直军披露了未来三年芯片规划:2026年一季度推出昇腾950PR,2026年四季度推出昇腾950DT,2027年四季度推出昇腾960,2028年四季度推出昇腾970。其中昇腾950PR全面支持FP8、MXFP8、HIF8、MXFP4和HIF4等低精度数据格式,FP8算力达1 PFLOPS,MXFP4算力高达2 PFLOPS,针对AI训练和推理的不同需求进行优化。
超大规模集群的核心挑战在于芯片间的高效通信。传统以太网在带宽、时延、可靠性等方面已难以满足万卡级集群需求。例如,华为推出的“灵衢”(UnifiedBus)互联协议,正是为解决这一瓶颈而生。
大模型训练对数据吞吐能力提出极高要求。以GPT-3为例,其训练数据集规模达570GB,训练过程中需要频繁读取海量数据。阿里云推出的“沧海”统一存储系统,支持对象/文件/块存储融合,AI训练数据读取带宽达TB级,延迟降低70%。
存储架构的创新方向包括:高并发数据读取优化、冷热数据分层管理、近计算存储(Near-Data Processing)等。浪潮信息的智算集群解决方案通过优化数据加载路径,将数据预处理时间缩短40%,显著提升GPU利用率。联想集团提出的“万全异构智算平台”,在数据存储环节,其NetApp AFX全闪存系统吞吐量达457GiB/s,配合AIDE引擎与LiSA智能体,在制造业及金融等落地项目中实现质检效率提升80%、存储成本降低30%。
算力调度是释放集群效能的关键。由于算力是高度异构和非标准化的,算力调度的复杂度,要远超水、电的调度。国家信息中心大数据发展部专家表示,英伟达、华为的AI芯片架构不同,这些AI芯片和通用的CPU(中央处理器)架构也不同。因此,不同的芯片,无法像水电那样简单混合使用,这给调度带来了极高的适配难度。
调度技术的核心能力包括:细粒度租户配额管理、任务优先级智能排队、断点续训与容错重试、弹性资源伸缩等。
随着单机柜功率突破50kW,传统风冷技术已逼近物理极限。中国科学院院士张锁江指出,智算中心已不可逆地迈入“兆瓦级时代”,亟需在突破芯片效能的同时,攻克高效散热难题。
液冷技术成为主流解决方案。曙光数创发布的全球首个兆瓦级相变浸没液冷整机柜,最高支持单机柜功率超过900kW,散热能力超过200W/cm²,机房占地面积节省超85%。联想集团的海神Neptune温水水冷技术,通过45℃~50℃温水循环,实现散热效率98%、余热回收90%,数据中心PUE降至1.1。
挑战是什么?
智算集群的快速发展背后,面临着技术、生态、能耗、成本等多重挑战。中国信通院《智算基础设施发展研究报告》将其归纳为四大核心瓶颈。
尽管国产AI芯片取得长足进步,但在制程、算力性能、软件生态等方面与国际先进水平仍存在差距。特别是在芯片制造环节,先进代工能力是AI芯片的“物理基座”,当前国内先进制程产能供给仍受制约。
生态短板同样突出。英伟达CUDA生态经过十多年发展,已成为AI开发的事实标准,拥有庞大的开发者社区和丰富的软件工具链。华为的昇思MindSpore、海光的DTK软件栈虽然在技术上不断进步,但在全球开发者接受度和应用广度方面仍需时间积累。
当前,智算集群普遍存在“重建设、轻运营”的问题。在“2025云网智联大会”上,SNAI推委会荣誉主席、原中国电信科技委主任韦乐平表示,当前国内智算中心已超280个,看似算力充沛,实则GPU平均利用率不足30%,且分布极不均衡。大量设施长期闲置或低效运行,暴露出典型的“有硬件、无体系”短板。
跨区域、跨行业的算力调度机制尚未健全。中国移动集团级首席专家张昊表示,从技术经济账来看,有人担心跨域调度的网络成本是否会抵消掉西部电价的优惠。如果为了省1元电费要花2元网费,那么调度的商业逻辑就不成立。同时,由于不同厂商的芯片架构、软件生态存在差异,模型应用跨厂商、跨架构调度往往面临着复杂度高和成本高的技术痛点。
中科院计算所研究员赵晓芳认为,从商业机制来看,算力资源掌握在不同的云计算厂商、电信运营商和地方国企手中。不同企业在业务上存在竞争关系,这会涉及算力定价和利益分配的难题。
智算集群已成为“电老虎”。据斯坦福人工智能研究所发布的《2023年AI指数报告》,AI大语言模型GPT-3一次训练的耗电量为1287兆瓦时,大概相当于3000辆特斯拉电动汽车共同开跑、每辆车跑20万英里所耗电量的总和。据中国信通院预测,到2030年,中国数据中心年用电量或将达到约7000亿千瓦时,占全国总用电量的比例将由目前的1.7%上升到约5.3%。因此,持续完善算电协同政策体系,提升协同智能化水平与自主可控能力,健全安全保障体系成为关键。
建设成本同样高昂。以万卡级集群为例,仅AI芯片采购成本就达数亿元,加上网络设备、存储系统、机房建设、液冷设施等投入,总投资规模往往超过10亿元甚至上百亿。高昂的投资门槛导致算力资源向头部企业集聚,中小企业面临“用不起”的困境。
谁建设?
智算集群的建设主体呈现多元化格局,主要包括政府、电信运营商、互联网云厂商、AI科技企业等。当前,已形成“政府引导、企业主导、政企协同”的建设运营模式。政府主导建设的智算中心通常作为公共基础设施存在,用于支持地方产业与AI融合,推动产业集群化发展。政府角色正从“直接投资者”向“规则制定者”和“生态搭建者”转变。
中国移动、中国电信、中国联通都制定了宏大的智算投资计划。运营商的核心优势在于网络基础设施和属地化服务能力。通过将智算中心与5G网络、边缘计算节点协同部署,运营商能够提供"云-边-端"一体化的AI算力服务。
互联网及云厂商在智算集群建设上展现出强劲的技术创新能力。据东北证券测算,中国互联网企业AI基础设施资本开支将从2025年的1688亿元增长至2030年的1.92万亿元,其中超节点占比预计从10%提升至约80%,对应超节点需求空间从253亿元增至1.54万亿元。
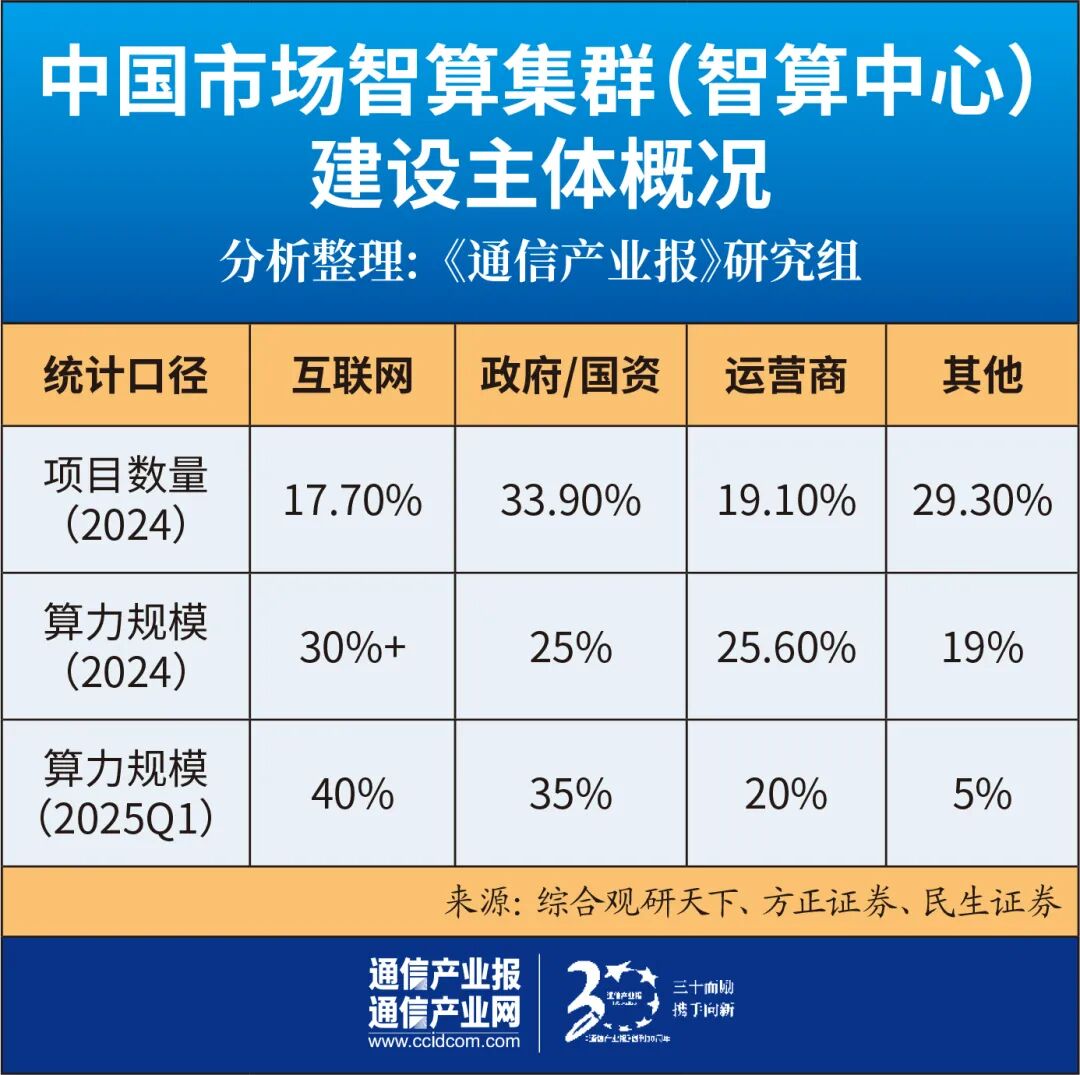
科技巨头的优势在于“算力-算法-数据”的闭环生态。字节跳动、阿里巴巴、百度等企业不仅建设大规模智算集群支撑自研大模型,还通过云服务向外输出算力。
智算集群建设还带动了产业链上下游的协同发展。在芯片层,华为、寒武纪、海光信息等国产厂商加速突破;在服务器层,浪潮信息、中科曙光、新华三等推出AI服务器新品;在散热层,曙光数创、英维克、高澜股份等液冷方案商快速崛起;在运营层,万国数据、世纪互联等第三方IDC厂商积极转型智算服务。
智算集群作为人工智能时代的“新基建”,正经历从规模扩张向质量提升的关键转型。从国家数据局的顶层设计到华为、中国移动等企业的技术突破,从政府主导的公共算力设施到市场驱动的商业集群,多元主体共同构筑起中国智能算力的四梁八柱。
采写:李洪力
延伸阅读
工信部:四方面持续推动算力产业体系化高质量发展
1000亿美元天价算力大单!亚马逊又有大动作
中国移动:加强Token运营,“十五五”算力收入要翻番
工信部:建设“1+M+N”国家算力互联互通节点体系
“东数西算”四年:八大枢纽成绩几何(附图)
国产AI万卡超集群落地国家级算力枢纽!
三大运营商中标:中国星网智能算力基建招标
算力“上天”:是什么?谁来干?