五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库从英伟达GTC大会,看见国产芯片的差距与机遇
而英伟达的 GTC 大会素有“ AI 界的春晚”之称。每逢此时,全球科技圈的数亿双眼睛,都将盯着台上一身皮衣的黄仁勋,逐字逐句地分析他所说的每一段话。
作为 AI 时代的超级玩家,英伟达是如何判断未来行业发展的?又是如何制定当下的游戏规则?
今年 GTC 大会,黄仁勋一口气讲了两个小时,信息量巨大,让我们既看到了目前在高端芯片上的实力差距,也看到了中国芯片产业的机遇。

“AI 行业的拐点已经来临,大模型将从训练为主切换为推理为主。”
这是今年 GTC 会议上,英伟达抛出的最重要的行业判断之一。
作为解释,黄仁勋列举了一个风靡全球的案例——OpenClaw。
自今年开年起,“养龙虾”蔚然成风。
有人用它当秘书,有人用它炒股、炒币,也有人用它写代码。甚至连帮人上门安装 OpenClaw,都成为一门有望年入百万的生意。
人人都指望 OpenClaw 能成为自己专属的“贾维斯”。但实际体验后,大家普遍的感受却是:
自己当不了钢铁侠。
因为这玩意儿太烧钱了。
为了模拟全天候助理,OpenClaw 每30分钟会自动醒来,检查有没有需要处理的工作。每次唤醒都不是简单的检查,而是一个装着冗长提示词、数十个工具参数的完整请求。Token(以下称中文名“词元”)耗费量极大。
有开发者算了一笔账。在没有太多实际产出的情况下,OpenClaw 一个月烧掉了近750美元。
作为行业的先行者,英伟达感受到了风向,也捕捉到了痛点。
AI 的交互方式从“对话”变为“做事”,所需的词元数量和算力增加了约10,000倍。
未来谁能高效地生成词元,谁就能取得极大优势。
打个比方。
“模型训练”阶段,就像在“造发电厂”。谁都知道电力不可或缺,所以无论火电、光电还是核电,能够发出电就是好电厂。
但到了“模型应用”阶段,逻辑就变了,变成了“运营电网”。
让电力成为基础设施,需要的是“平价电”、“稳定电”。只有这样,家家户户才能用上电,才能使用电灯、微波炉、电脑等产品。
AI 时代如何更高效地生成词元,英伟达率先给出了自己的方案。

今年 GTC 大会上,英伟达不再着重强调单一芯片的性能突破,而是提供一套“7款芯片+5套机架系统+AI 工厂”的完整解决方案。
英伟达宣布,今年共有七款全新芯片进入量产阶段,分别是:Rubin GPU(新一代加速核心)、Vera CPU(专为智能体任务优化的中央处理器)、Groq LPU(推理加速器)、BlueField-4 DPU/STX(专用存储处理单元)、NVLink 6/7/8交换机(机架内铜缆互联及跨机架光学互联)、ConnectX-9 SuperNICs(增强网络接口性能)、Spectrum-6/7 以太网交换机(高速网络交换)。
新一代的芯片囊括计算、存储、互联方向,集成在5套全新的机架系统中。此举的目的是将英伟达从“单一 GPU 供应商”向“全栈基础设施提供商”转型,即黄仁勋在大会上强调的“AI工厂”理念。
如何理解英伟达此次提出的“AI 工厂”理念?你可以想象下面这样的场景:
你是一名富有雄心的创业老板,正打算创立一家公司(开发一个 AI 大模型),成就一番大事业。
但目前业内普遍提供的基础设施方案是:
一间毛坯办公室(NPU/GPU 单一种类芯片,缺乏专用的 CPU、LPU、DPU 配套)
基础控制开关(软件生态成熟度较低或需自行开发)
基础网线接口(依赖通用的 PCIe 或 RoCE 网络进行互联,多卡/多机扩展时的通信效率损耗较大)
初步管线排布(用户需自行调优散热策略,省电增效的 PUE 优化依赖现场工程师经验)
此时,英伟达向你提供了另一套解决方案:
精装修办公室,可以直接入场办公(NVL72机架开箱即可运行大模型训练)
全套智能设备控制系统(成熟软件系统,百万级开发者生态)
高速光缆(NVLink 铜缆互联,单 GPU 3.6Tb/s,机架内无损通信)
全屋定制(800V电源、液冷 manifold 散热和背板设计纳入统一规范,整个机架如同“一颗巨大的芯片”)
“AI 工厂”不仅降低了 AI 行业的进入门槛,更重要的是,通过效率优化,令每 GW(吉瓦)的词元吞吐量更高。
这也让英伟达的商业模式变为出售经过优化的“AI 工厂”产能——客户购买的是确定的词元产出率和低延迟服务。

不可否认,近两年来国产芯片的成就可圈可点。
无论是在各项基准测试中的表现,还是在实际可用性上,我们都在迅速缩小差距。
但看完今年英伟达的布局,一个现实摆在面前:未来的牌桌上,玩法已经变了。
如果国内芯片厂商依然将目光局限在“如何做出一块算力更强的单卡”,继续陷入“单芯片能力突破”的窠臼,那无异于在别人已经开始兜售整座“发电厂”时,我们还在死磕如何造出一台功率更高的“发电机”。
英伟达已用实际行动证明,未来的比拼是系统整合能力,是全栈基础设施的完善度,归根结底,是谁能提供更有效率的词元生产能力。
因为芯片的最终目的,从来不是为了在跑分榜上争个高下,而是为了帮助开发者作出、运行更好的大模型。
缺乏配套的软件生态和互联系统,单卡的纸面数据再好看,也难以转化为规模化的生产力。
不过,国内芯片同样有其得天独厚的优势。在当前算力普遍不足的背景下,国内丰富的 AI 生态和需求就是我们最大的底牌。
在集成电路产业发展的长跑中,国内芯片企业应当遵循“高筑墙、广积粮、不称霸”的九字方针。

“高筑墙”就是强化生态构建,加快发展国产芯片的硬实力。
在中国当前的人工智能发展路径中,拥有从芯片、云服务、大模型到顶层应用的全栈能力,是企业在激烈竞争中脱颖而出的决定性因素。当 AI 芯片与大模型、云实现深度适配,往往能激发出惊人的化学反应,实现1+1+1>3的结果。
此外,与海外相同价格档位的芯片相比,国产 AI 加速器在“性能/成本”方面展现出明显优势。这对于大规模部署 AI 服务的云厂商而言,也意味着更低的运营成本。
“广积粮”就是利用国内丰富的 AI 需求,支撑集成电路产业高额的研发和投入。
集成电路是国家战略级高度的产业,自主可控的发展趋势毋庸置疑。美国对华最先进芯片的禁售,催生了国产芯片发展的紧迫性,这已从十年前的“可选项”转变为关乎生存的“必需品”。
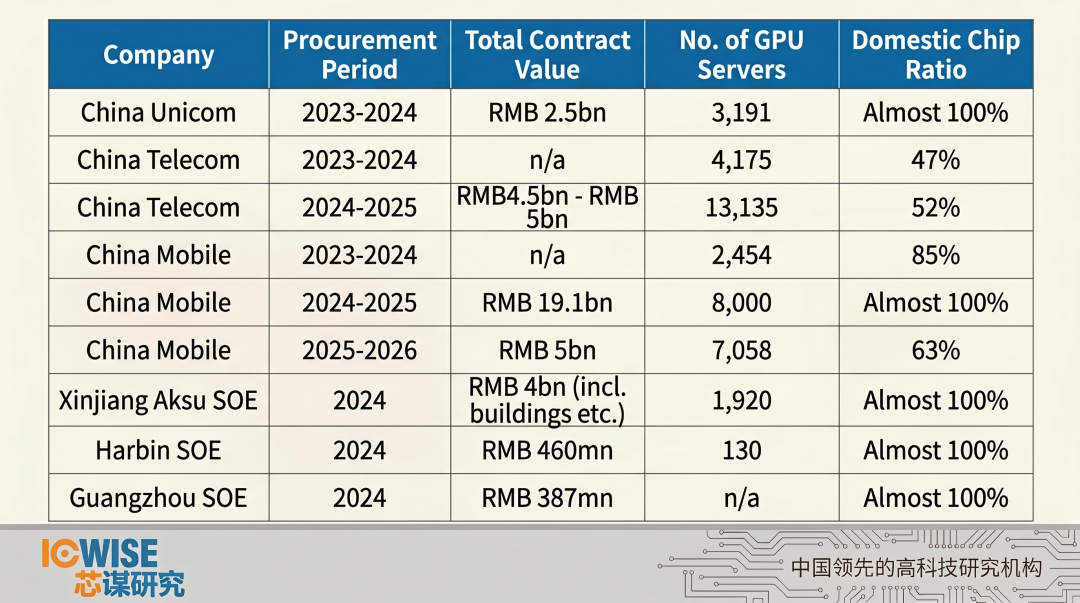
这也为国产芯片催生出了一片规模庞大的基础市场。尤其在公共部门领域,国有企业正大规模采购国产 GPU。中国移动、中国联通等电信运营商的多个采购项目中,国产芯片占比持续提高,部分项目接近100%。例如,中国移动2024-2025年价值191亿元人民币的采购项目中,几乎全部采用华为昇腾硬件产品。
从自动驾驶到智能制造,从政务云到各种垂直领域的业务场景,海量的真实落地需求构成了庞大的市场。这种源于一线的旺盛需求,将倒逼国产算力跳出单点作战的思维,在真正的应用实战中加速系统级整合的步伐。
“不称霸”则是低调发展,精准宣传,不搞媒体狂轰滥炸
相比追求媒体曝光和市场声量,国内芯片企业更应将精力聚焦于产品本身的打磨与技术积累。踏实做好每一代产品的迭代优化,在客户验证中积累口碑,这才是最好的宣传。
今年4月,美国两党提交《MATCH》法案,欲再次加码对华半导体技术封锁。在技术尚未完全成熟、生态尚未完善之前,保持低调务实的发展姿态更有利于构建长期竞争力。而过度的市场宣传和技术炒作,可能引来不必要的关注和压力,不利于行业的稳健发展。

结语
国产芯片行业不必如英伟达一般,在取得行业领先地位后,通过“自上而下”地定义行业规则来保持领先优势。
更适合当下国内芯片产业的发展路径,是通过旺盛且富有活力的AI需求和生态,“自下而上”地反哺技术与硬件能力的成长,同时低调发展,避免与美国芯片产业直接“硬碰硬”造成短期的强烈冲击。
国产芯片的发展,不是一场短跑冲刺,而是一场需要耐心和韧性的马拉松。只有在扎实的技术积累、完善的生态体系和充分的市场验证基础上,才能真正实现从“能用”到“好用”,再到“引领”的跨越。
- END -

推荐关注