![]()
累计融资近40亿元,国内首家估值超百亿纯推理GPU独角兽诞生。芯东西4月20日报道,刚刚,浙江杭州GPU创企曦望宣布完成新一轮超10亿元融资,这是2026年AI产业全面迈入"推理落地、智能体普及"时代后,国内GPU赛道诞生的最大单笔融资之一。本轮资金将用于新一代S3推理GPU的规模化量产交付、全栈软件生态建设,以及S4/S5后续芯片的研发迭代。此次融资由多家产业方战投、地方国资及头部财务机构共同参与。豪华投资方阵容正用真金白银,押注这家主攻推理的国产GPU创企。至此,分拆独立仅一年多的曦望已累计完成7轮融资,总融资额约40亿元,成为国内首家估值超百亿的纯推理GPU独角兽。作为国内首家All in推理的GPU企业、首批实现推理GPU万卡级交付的芯片公司,曦望成立于2020年,前身是商汤科技大芯片部门,2024年底分拆独立运营,目前其团队规模约400余人,集结来自英伟达、AMD、昆仑芯、商汤等企业的研发人才。如今其已悉数亮相三颗芯片,最新的启望S3是曦望为下一代大模型推理打造的高性价比GPU芯片,致力于以极致的单位算力成本,全面开启AI推理的“一分钱时代”。智能体时代,企业损益表正被全面重构。智能体已然成为核心生产力,以OpenClaw为代表的智能体应用迅速走红,数据中心也随之转型为持续吞吐海量数据、输出智能内容的“Token工厂”。在未来的AI服务体系中,Token将成为可直接计价的数字商品,AI服务也将依据吞吐量、速率、智能密度等维度对其进行分层定价。在这样的行业逻辑下,成本与效率成为竞争的关键胜负手,谁能将单位Token成本压至更低、让能效比达到更高,谁就能占据市场主导地位。而从创立之初便深耕推理领域的曦望,恰好踩中了智能体时代的核心命门:正如芯片领域对功耗、性能、面积的极致追求一样,若能将AI推理成本大幅降低90%,同时保障服务稳定可靠,便能真正改写中国AI产业的损益结构,让AI从高投入的烧钱模式走向可持续的商业化正循环。
过去数年,AI发展核心围绕训练展开,参数、集群、算力投入决定模型能力上限;如今AI深度参与各类复杂工作,直接推动行业焦点转向推理。这一趋势的重要性,被一组关键数据印证:英伟达创始人、CEO黄仁勋在GTC 2026大会称,过去两年AI推理计算量增长约一万倍、使用量增长约一百倍。▲英伟达创始人兼CEO黄仁勋GTC大会演讲
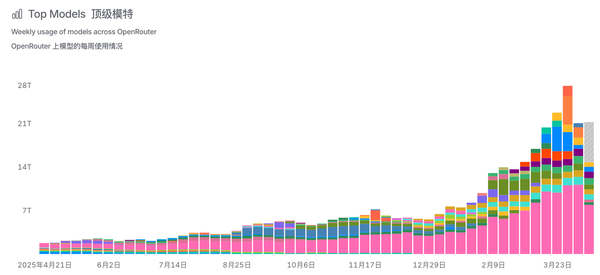
2026年初的OpenClaw热则直接改写了Token消耗逻辑,AI智能体一次复杂任务会触发数十次连续推理请求,Token消耗由此呈现指数级爆发的态势。▲OpenRouter平台上AI模型每周使用量趋势
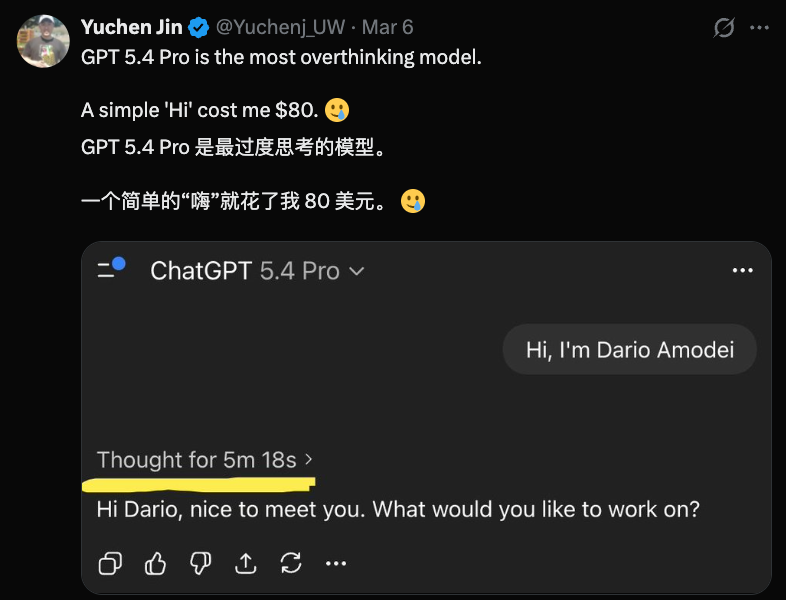
这背后对企业而言就是不可预估的成本。本月初,外媒The Information拿到一份Meta内部追踪员工Token使用量的数据,过去30天内,Meta全员Token总消耗量超过60万亿个,若按照当时Claude Opus 4.6的公开定价估算,其排名第一月均使用2810亿Token的用户,一个月的成本就超过140万美元(约合人民币954万元)。更值得警惕的是,大量Token并未被有效利用,而是被无效浪费,成为企业算力账单的隐形成本。Hyperbolic联合创始人金宇晨曾在社交平台X平台上吐槽,GPT-5.4 Pro是他用过最爱“过度思考”的模型,他仅发了一句简单的“Hi”,模型直接烧掉80美元。这进一步推高云厂商硬件与运营成本,导致全球云厂商集体涨价。3月至今,阿里云、百度云、腾讯云等国内云厂商纷纷官宣调价,阿里云平头哥真武810E等算力卡产品上涨5%—34%,文件存储CPFS(智算版)上涨30%;百度智能云AI算力相关产品上调约5%—30%,并行文件存储上调约30%。云厂商的一系列调价动作,本质上都是推理成本压力的直接传导。Token爆发、云厂商涨价的双重作用下,企业推理成本压力愈发凸显。推理服务能否长期稳定运行、实现高效吞吐、控制合理成本,已成为企业核心的诉求。与之对应,行业不再单纯追逐芯片峰值算力,而是通过系统级创新,重新定义“每瓦Token”这一核心KPI,以此破解成本困局。对企业而言,过去比拼的是工人、设备与厂房规模;而在智能体时代,核心竞争力将取决于单位成本能调用多少有效Token、每个智能决策能创造多少价值。“每瓦Token”不仅是技术指标,更是企业关键的运营成本指标。同等电力、同等机柜空间下,能产出更多有效Token,意味着企业可以用更少机房、更低电费支撑更大业务规模,在算力密集型竞争中构筑显著的成本壁垒。这一背景下,中国已成为这场全球算力革命的核心战场。根据OpenRouter数据,中国大模型周调用量已连续6周超美国,周调用量达12.96万亿Token,是美国的4.28倍。中国已成为全球AI推理最大市场,推理成本的压力与机遇在此集中显现。一方面,国内拥有旺盛的推理算力需求和海量丰富的应用场景,为推理技术的迭代与落地提供了坚实基础;另一方面,企业对低成本AI的迫切诉求,也倒逼行业加速探索成本优化的路径。AI要实现像水电一样普及,第一道必须攻克的关口,就是将推理成本从“元级”压缩至“分级”。而破解这一困局的关键解法之一,便是打造一类为推理而生、为成本优化、为规模化部署量身定制的专属GPU。
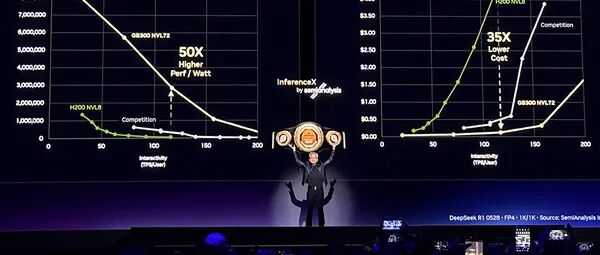
作为国内首家All-in推理的GPU企业,曦望是在行业集体卷训练、拼参数时,基于产业发展判断做出的反共识但极具前瞻性的战略选择。其核心目标不是取代、对标训推一体GPU或通用AI芯片,而是只做推理分流侧翼与成本优化层,在不改动客户现有技术栈的前提下,直接实现降本增效,用更高的推理性能重构AI产业成本结构。如今曦望已形成芯片、解决方案、生态三位一体布局,而这整套体系直接回答的就是一个问题:推理GPU,究竟该强在哪里?今年1月,曦望发布的新一代推理GPU芯片启望S3,正是对这一问题的有力回应。作为国内首款搭载LPDDR6且兼容LPDDR5X内存的推理GPU,S3从AI Core计算架构到内存IO系统进行了全链路重构。在计算层,S3进行了深度定制,其推理性能较上一代S2提升5倍,目标是实现Token成本下降90%。S3实现了极致算子利用率、智能体原生微架构、全链路FP4低精度三大核心突破。包括128-bit、3D指令集搭配独立线程调度,配合片上数据复用技术,适配智能体复杂推理;原生支持FP16到FP4低精度运算,主流大模型推理效果接近无损,吞吐量较FP16提升3~4倍,直接提升客户盈利空间;将GEMM、Flash Attention利用率分别提升至约99%、98%,硬件有效算力与并发能力大幅提升。在系统层,S3集成LPDDR6内存接口技术、高速SerDes+SUE融合互联技术、PCIe Gen6接口技术三大先进高速接口,解决了智能体三大核心瓶颈。首先LPDDR6方案使得S3带宽充足、容量大幅提升、功耗降50%+;兼容 LPDDR5x,可灵活推出多规格产品,覆盖边缘至云端推理,可以破解推理场景大容量、高性价比、低功耗的核心需求。其次, S3采用了片上原生融合Scale-Up+Scale-Out双模底座;以太网超节点引擎支持一跳直达、硬件加速集合通信,利旧交换机并可压延迟至百纳秒级;集成RDMA引擎,优化KV Cache零拷贝传输,支持32–256弹性组网。这一系列创新是针对智能体多模型协同瓶颈的有效解法。最后PCIe Gen6接口技术下,S3带宽较Gen5翻倍,支撑多路高速网卡与NVMe 集群;构建显存-DRAM-NVMe三层异构KV Cache,实现热温冷数据分层管理,高效扩展容量;同时兼容业界标准,无缝融入云原生高性能体系。这对应解决的是智能体的资源碎片化问题。由此可见,S3押注的是,彻底剥离训练能力,专为大模型推理做原生深度优化。其砍掉训练相关模块后,节省的晶体管与功耗全部倾斜于推理,让单位面积有效算力效率提升超5倍。因此一定程度上可以说,S3是更适合智能体时代的原生芯片。在曦望董事长徐冰看来,S3不是简单的性能升级,而是一次对AI推理成本曲线的重构。他们的目标是将推理成本降至“百万Token一分钱”,让AI像水电一样成为普惠基础设施。这与当下的智能体浪潮不谋而合,智能体时代真正的瓶颈不在模型能力,而在规模化、低成本、高稳定的推理供给。在芯片之外,曦望已构建起完整硬件矩阵,包括寰望超节点集群、辰望计算平台、寰望AI计算集群,其中,寰望SC3-256超节点可支持千亿、万亿级参数多模态MoE推理,同⼀量级下,成本仅为千万元级别。曦望并未止步于硬件层,而是持续向上延伸,构建起完备的算法与生态能力,实现大模型适配优化、AI算法平台、场景定制算法,同时自研AI软件栈、CUDA兼容生态、主流框架支持。从芯片到集群,从底层软件到上层算法,可以看出,曦望的All-in推理不是口号,而是真正从芯片到系统的全栈重构。
对算力发展清晰研判需要对AI和芯片的洞察都更清晰。从商汤大芯片部门独立而来的曦望,就自带“芯片基因+AI应用经验”,为其切入新一代算力赛道构筑了先天壁垒。其领导团队精准搭建了以AI产业布局、芯片顶尖研发、互联网产品商业化为核心的“黄金三角”架构:曦望董事长徐冰是商汤联合创始人,曾于⾹港中⽂⼤学博⼠在读期间与导师汤晓鸥教授共同创办商汤。商汤不仅是彼时国内AI领域的标杆企业,更在2021年成功登陆港股,成为“港股AI第一股”,其在AI算法、场景应用上积累了经验。负责研发的曦望联席CEO王勇,是前AMD、昆仑芯的核心架构师,有20年芯片研发经验,主导昆仑芯及曦望多代芯⽚的研发量产。2020年加入商汤后,他带领百人团队主导了曦望两代芯片的研发和量产,均实现一次性成功点亮。与王勇的技术研发能力形成互补,另一位联席CEO王湛拥有凭借丰富的互联网产品运营经验,王湛是百度创始团队成员、前资深副总裁,曾领导数千⼈团队打造了百度搜索引擎产品。▲曦望董事长徐冰、曦望联席CEO王勇、曦望联席CEO王湛(从左至右)
凭借核心团队的独特优势,曦望在算力与AI赛道中形成了差异化竞争力。其核心团队亲身经历国内最早一批大规模AI应用、人脸识别、自动驾驶、多模态等多个技术周期与应用场景,历经用户需求的反复打磨捶打,对AI技术的落地痛点、算力需求的核心痛点有着更为精准的洞察,也让曦望成为更懂AI的GPU芯片企业。在这样的布局下,曦望目前的团队规模已经达到400余人,研发人员占比超过80%,汇聚了英伟达、AMD、华为海思、百度昆仑芯、阿里巴巴、商汤等各赛道的头部企业人才,且核心技术人才平均拥有15年行业经验。基于对AI和芯片赛道的判断,曦望从创立之初便立足企业业务需求侧,聚焦为客户核算实际价值账,而非单纯比拼参数,由此抢先卡位推理时代。曦望董事长徐冰透露,2026年,曦望将围绕“落地、兑现、增长”核心原则,全力推进S3芯片量产交付,完成与国内外主流大模型、多模态模型和Agent框架的全面适配。同时,该公司已完成S4高性能推理GPU和S5安全可控推理GPU的技术路线规划,持续加码近存计算、光电共封等前沿技术探索。曦望的资本化布局正在稳步推进,2026年2月,其完成股份制改造,成为浙江省首家完成股改的GPU企业,深度融入杭州争创全国AI创新发展第一城的发展大局。本次投资方的代表为杭州资本,这是其紧扣杭州“296X”先进制造业集群建设战略、深耕AI能万亿级产业赛道的重要布局,他们认为,曦望“All-in推理”的战略选择具备行业前瞻性,其在技术创新和产品商业化方面的能力,是他们决定投资的重要原因。作为长期资本,杭州资本更看重企业在关键技术方向上的持续投入与落地能力。
当下AI产业已从拼参数、堆算力的粗放阶段,进入单位Token成本与能效比的精细化竞赛。对企业而言,Token成本不断下探,就意味着其商业化边界能不断拓宽。未来,智能体带来的链式调用与并发爆发,将直接推动Token需求增长10倍乃至百倍,推理算力的缺口只会持续拉大。最终,这场以Token效率为核心的革命,将让AI真正融入千行百业,从技术概念变为实体经济的增长引擎。
 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库