 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库想用RK3588在边缘端跑大模型?你的算力还差多少?
在边缘计算与
嵌入式
AI
应用飞速发展的今天,
瑞芯微
RK3588平台凭借其强大的多媒体处理能力和6TOPS的NPU算力,已成为高端AIoT项目的首选之一。然而,面对日益复杂的大模型(LLM)部署需求与高并发的视觉推理任务,单一的SoC算力往往面临瓶颈。
为此,瑞芯微推出了专为算力扩展设计的RK1820 AI加速卡。本文将以EASY-EAI的MONSTER(RK3588)开发板为例,提供一份从硬件对接到模型部署的完整适配指南,并对其性能进行实测分析,为
开发者
实现算力升级提供切实可行的技术路径。
PART.01
核心硬件:
RK1820加速卡与RK3588的协同架构
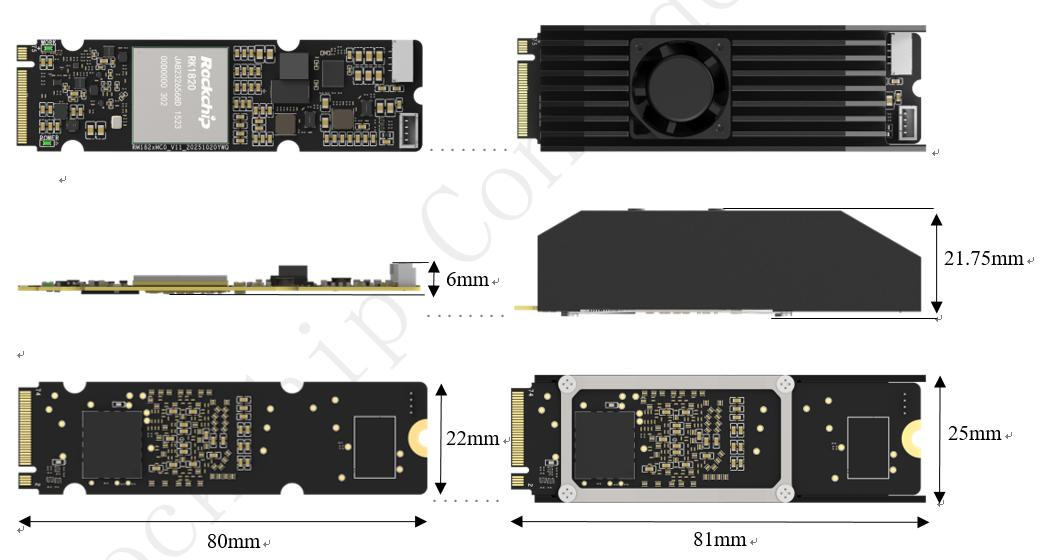
RK1820加速卡概览
RK1820是一款采用PCIe
接口
的独立AI加速卡,其核心设计目标是作为主控SoC的协
处理器
,专攻高强度、批量的AI推理任务。其关键特性如下:
高密度算力:提供高达20 TOPS@INT8的峰值算力,足以应对大多数视觉大模型及十亿参数级别的语言模型。
大容量板载内存:集成2.
5G
B专用内存,能够将大型模型完全载入,避免频繁通过PCIe总线与主机交换数据,从而显著降低推理延迟。
标准接口:采用M.2 Key M接口,便于与具备PCIe通道的RK3588核心板或开发板快速集成。
RK3588 + RK1820的异构计算模式
在此方案中,RK3588与RK1820构成了一个典型的异构计算系统:
RK3588(主机):负责运行完整的
操作系统
(如Ubuntu)、处理通用计算、多媒体编解码、系统调度以及轻量级或实时性要求高的AI任务。
RK1820(设备):作为专用的AI推理加速器,接收来自主机的推理任务和数据,利用其高并行计算单元完成高效处理,并将结果返回。
这种分工实现了计算资源的优化配置,使RK3588平台的能力边界得以大幅扩展,尤其适合智能N
VR
(多路视频结构化分析)、服务
机器人
、边缘AI服务器及需要端侧运行大语言模型的场景。
PART.02
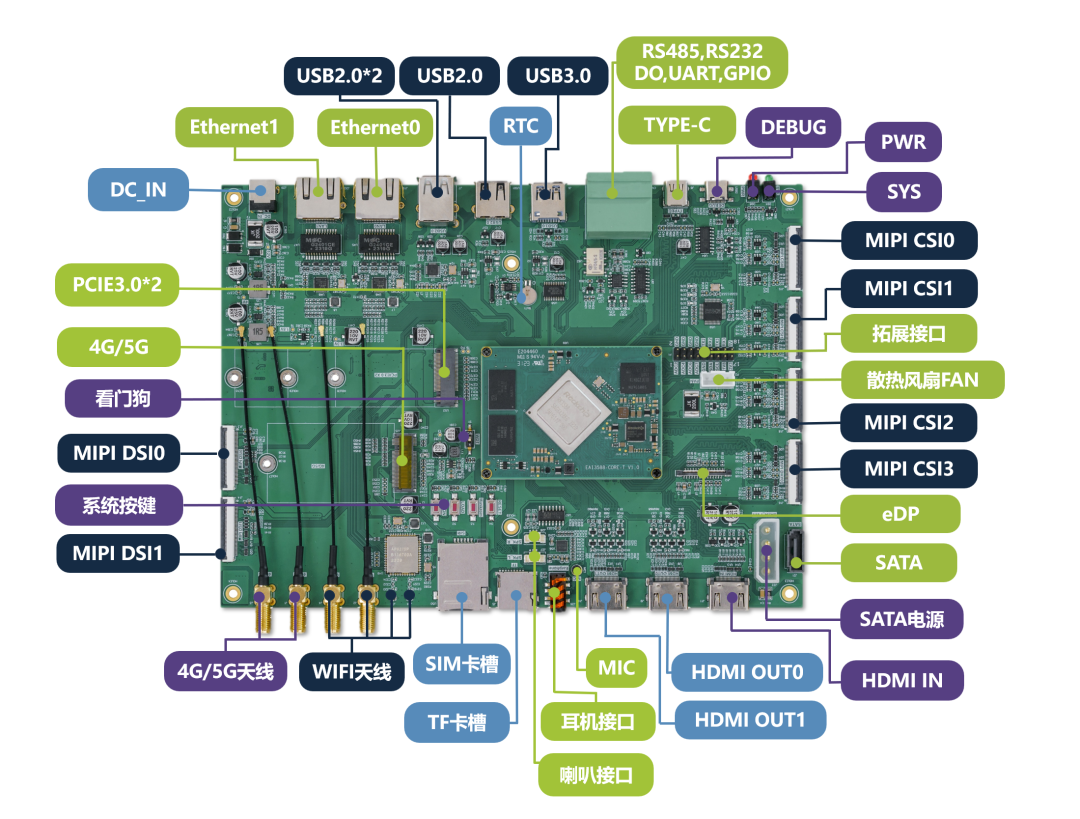
软硬件适配与驱动部署
*以下适配流程基于EASY-EAI-MONSTER开发板及配套的软件包
硬件连接与准备
硬件
:EASY-EAI-MONSTER开发板、RK1820 M.2加速卡、12V/3A
电源
(为算力卡独立供电)。
连接顺序
:务必先将RK1820加速卡插入主板的M.2插槽并连接好12V供电,然后再为开发板上电。此顺序可确保PCIe设备能被系统正确识别枚举。
软件基础
:开发板需预先烧录适配后的固件(如
EASY-EAI-Monster-Ubuntu 22.04-firmware_20260407
或更新版本)。
驱动安装与验证
将提供的适配套件
rknn3_rk182x_sodimm_installer_
arm
64.tgz
拷贝至开发板,并按顺序执行以下命令:

安装脚本将自动部署PCIe驱动(
pcie-rkep
)、用户态库及相关服务。
设备验证
重启后,可通过以下命令验证适配是否成功:
检查PCIe设备识别
:执行
lspci
,列表中应出现
Rockchip
Electronics Co., Ltd Device 182a
的设备信息。

检查驱动加载
:执行
dmesg | grep pcie-rkep
,查看驱动加载日志,确认无错误信息。
检查设备节点
:执行
ls -l /dev/pcie-rkep*
,确认驱动已创建设备节点。
查看算力卡状态
:执行
rknn-smi info
,此命令可显示RK1820的详细信息,包括设备名称、算力利用率和内存使用情况,是验证加速卡是否就绪的最直接方式。
PART.03
模型部署与性能实测
适配成功后,即可利用RKNN工具链将模型部署到RK1820上运行。套件中提供了
rknn3_model_
te
st
和
rknn3_session_test
两个测试程序,分别用于传统视觉模型和大语言模型。
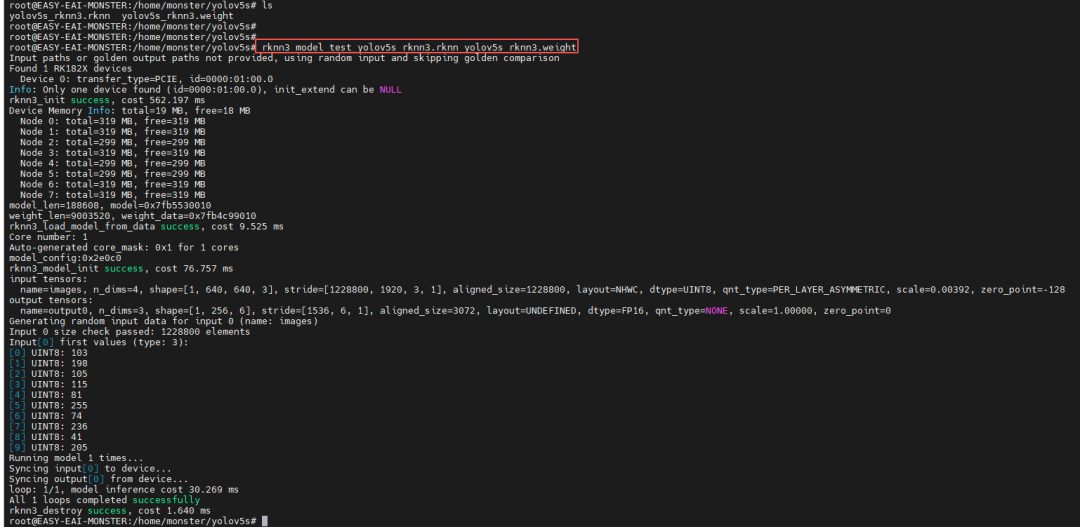
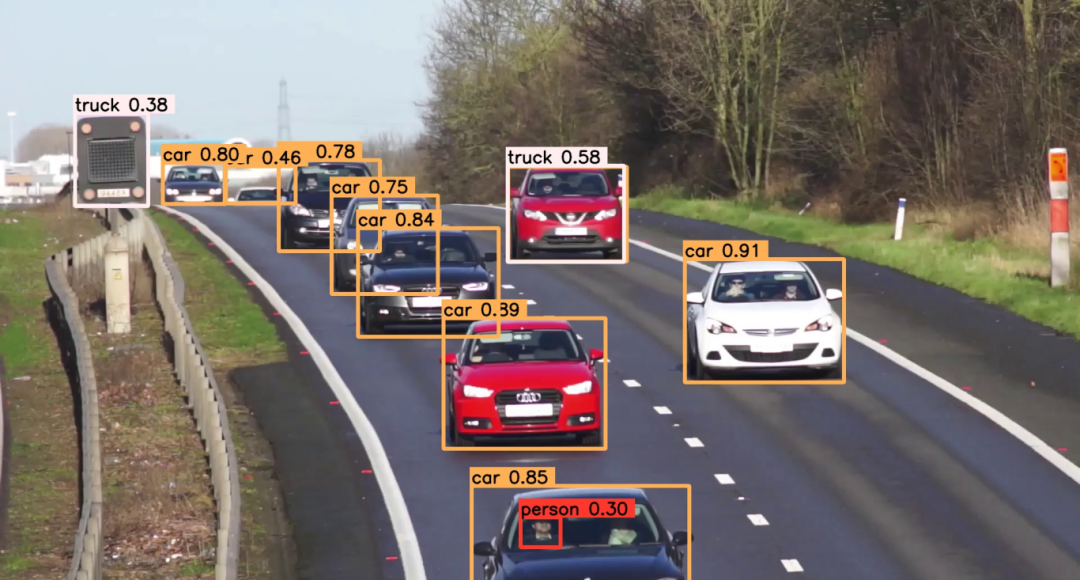
视觉模型测试
(以YOLOv5s为例)
模型准备
:使用RKNN-Toolkit2将训练好的YOLOv5s模型转换为RK1820支持的
.rknn
格式。
执行推理
:将模型文件置于板端,运行以下命令:

性能指标
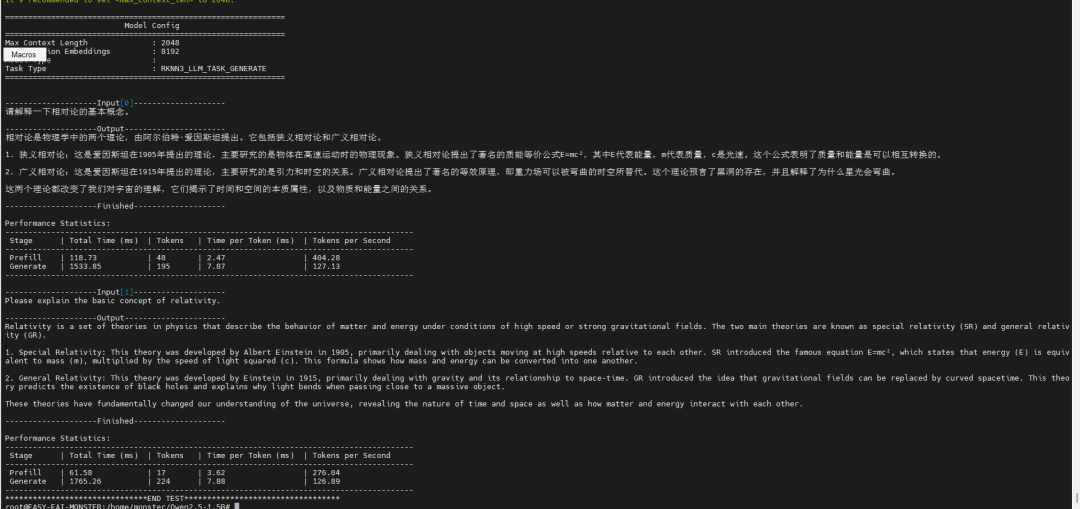
:在测试中,YOLOv5s模型在RK1820上的单次推理耗时约为
30.27毫秒
,展现了其处理实时视觉任务的高效能力。
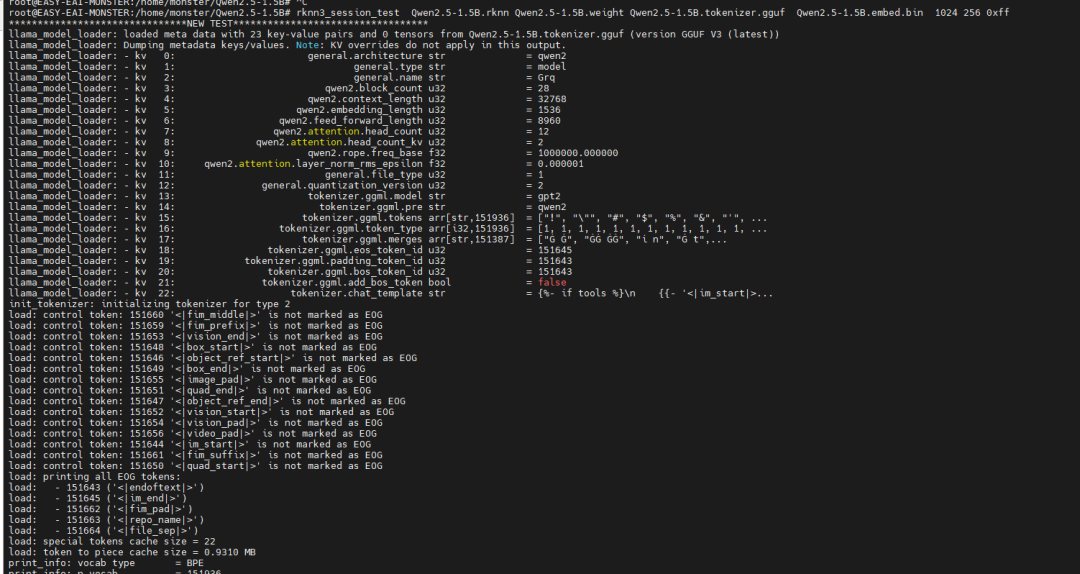
大语言模型测试
(以Qwen2.5-1.5B为例)
模型准备
:需要准备转换后的
Qwen2.5-1.5B.rknn
模型文件、权重文件(
.weight
)、分词器文件(
.tokenizer.gguf
)和嵌入层文件(
.embed.bin
)。
执行推理
:由于大模型运行通常需要独立的模型服务,需先停止系统默认的rknpu服务,然后启动会话测试:

能力验证
:此测试将启动一个交互式会话,开发者可以直接输入文本,模型将基于RK1820的算力进行生成式回复,直观验证了在边缘端部署并运行十亿参数级大模型的可行性。

PART.04
应用场景与开发建议
典型应用场景
多路高性能视频分析
:利用RK3588强大的解码能力处理多路视频流,将解码后的画面数据通过PCIe总线发送给RK1820进行
高精度
、高并发的目标检测与识别。
边缘AI服务器
:在局域网内部署,为多个终端提供低延迟的AI服务,如智能客服、代码辅助、文档摘要等。
复杂环境下的机器人
:同时处理激光雷达、视觉、语音等多模态
传感器
的输入,进行实时融合感知与决策。
开发建议
任务划分
:将时延敏感、控制相关的轻量模型放在RK3588 NPU上运行;将计算密集、允许微秒级延迟的批量推理任务卸载到RK1820。
数据传输优化
:尽量减少主机与加速卡之间不必要的内存拷贝,利用零拷贝等技术优化PCIe数据传输效率。
功耗管理
:在连续推理任务中,RK1820的功耗是需要考虑的因素。在间歇性工作场景,可通过驱动接口管理其工作状态以实现能效平衡。
通过上述适配,RK3588平台成功融合了RK1820加速卡的20TOPS算力,构建了一个总计超过26TOPS的强劲边缘AI系统。本次实践表明,该方案软硬件集成度较高,驱动安装便捷,为开发者提供了清晰的从验证到部署的路径。无论是提升现有视觉应用的性能密度,还是探索在边缘设备运行大语言模型这一前沿领域,RK3588+RK1820的组合都提供了一个稳定而强大的硬件基础。
EASY-EAI灵眸科技
EASY-EAI灵眸科技
+关注
关注
4
文章
82
浏览量
3709
算力
算力
+关注
关注
2
文章
1619
浏览量
16819
RK3588
RK3588
+关注
关注
8
文章
582
浏览量
7501
大模型
大模型
+关注
关注
2
文章
3723
浏览量
5254





