五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库刚刚,谷歌发布两款芯片,剑指英伟达!

多年来,谷歌一直在生产既能训练人工智能模型又能处理推理工作的芯片,现在,谷歌正将这些任务分离到不同的处理器中,这是其在人工智能硬件领域挑战英伟达的最新举措。
谷歌周三表示,将对其第八代张量处理单元(TPU)进行这项更改。这两款芯片都将于今年晚些时候上市。
谷歌高级副总裁兼人工智能和基础设施首席技术官阿明·瓦赫达特在一篇博客文章中表示:“随着人工智能代理的兴起,我们认为,如果芯片能够根据训练和服务的需求进行个性化定制,那么整个社区将会受益。”
今年3月,英伟达大力宣传即将推出的芯片,该芯片能够让模型快速响应用户提问,这得益于其以200亿美元收购芯片初创公司Groq所获得的技术。谷歌是英伟达的大客户,但它也向使用其云服务的公司提供TPU作为替代方案。
全球大多数顶尖科技公司都在寻求定制化的人工智能半导体开发,以最大限度地提高效率,并满足特定应用场景的需求。苹果多年来一直在其自主研发的iPhone芯片中集成神经网络引擎AI组件。微软于今年1月发布了第二代AI芯片。上周,Meta公司表示正在与博通公司合作开发多个版本的AI处理器。
谷歌很早就抓住了这一趋势。2015年,该公司开始使用其自主设计的处理器来运行人工智能模型,并于2018年开始将这些处理器出租给云客户。亚马逊网络服务公司(AWS)于2018年发布了用于处理人工智能请求的Inferentia芯片,并于2020年推出了用于训练人工智能模型的Trainium处理器。
DA Davidson 分析师在 9 月份估计,TPU 业务加上 Google DeepMind AI 集团,价值约为9000 亿美元。
目前没有任何一家科技巨头能够取代英伟达,谷歌甚至都没有将自家新芯片的性能与这家人工智能芯片领军企业的产品进行比较。谷歌确实表示,这款训练芯片的性能是去年11月发布的第七代Ironwood TPU的2.8倍,价格却相同;而推理处理器的性能则提升了80%。
英伟达表示,其即将推出的Groq 3 LPU硬件将采用大量的静态随机存取存储器(SRAM),这种存储器也被人工智能芯片制造商 Cerebras 使用,该公司已于本月初提交了上市申请。谷歌的新型推理芯片 TPU 8i 也依赖于 SRAM。每个芯片包含 384 兆字节的 SRAM,是 Ironwood 芯片容量的三倍。
谷歌母公司 Alphabet 的首席执行官桑达尔·皮查伊在一篇博客文章中写道,该架构旨在“以经济高效的方式同时运行数百万个代理所需的巨大吞吐量和低延迟”。
谷歌人工智能芯片的应用正在加速增长。据谷歌称,Citadel Securities 开发了一款基于谷歌 TPU 的量化研究软件,美国能源部所有 17 个国家实验室也都在使用基于这些芯片构建的人工智能协同科学家软件。Anthropic 公司已承诺使用数吉瓦的谷歌 TPU。
第八代TPU:面向智能体的两款芯片
今天在 Google Cloud Next 大会上,我们(指代谷歌,下同)将推出第八代 Google 定制张量处理器 (TPU),即将推出两种专为训练和推理而设计的架构:TPU 8t 和 TPU 8i。这两款芯片旨在为我们定制的超级计算机提供强大动力,驱动从前沿模型训练和智能体开发到海量推理工作负载的各种应用。
多年来,TPU 一直为包括 Gemini 在内的领先基础模型提供支持。第八代 TPU 将共同为训练、服务和智能体工作负载带来卓越的规模、效率和功能。
在人工智能时代,模型必须能够推理问题、执行多步骤工作流程,并在持续循环中从自身行为中学习。这给基础设施带来了新的挑战,而 TPU 8t 和 TPU 8i 正是与 Google DeepMind 合作设计的,旨在应对最苛刻的人工智能工作负载,并大规模适应不断演进的模型架构。
TPU 为众多机器学习超级计算组件树立了标准,包括定制数值计算、液冷、定制互连等等。我们的第八代 TPU 是十余年研发的结晶。最初 TPU 设计的核心理念至今依然适用:通过将芯片与硬件、网络和软件(包括模型架构和应用需求)进行定制和协同设计,我们可以显著提高能效和绝对性能。
我们欣喜地看到,十年的创新已转化为现实世界的突破。如今,像 Citadel Securities 这样的先锋企业正在不断突破极限,选择 TPU 来驱动其尖端的 AI 工作负载:

两枚芯片,满足当下需求
硬件开发周期远长于软件。每一代TPU的开发,我们都需要考虑其上市时将会出现哪些技术和需求。
几年前,我们预见到随着前沿AI模型在生产环境中大规模部署,客户对推理功能的需求将会不断增长。而随着AI代理的兴起,我们认为,如果能够开发出专门针对训练和服务需求而设计的芯片,将有助于整个社区的发展。
TPU 8t 擅长处理大规模、计算密集型的训练工作负载,其设计旨在提供更大的计算吞吐量和更强的可扩展带宽。TPU 8i 则拥有更高的内存带宽,专为对延迟最为敏感的推理工作负载而设计,这一点至关重要,因为大规模智能体之间的交互会放大哪怕是微小的效率损失。
重要的是,这两款芯片都能运行各种工作负载,但专业化可以显著提高效率并获得收益。
TPU 8t:专注于训练
TPU 8t旨在将前沿模型开发周期从数月缩短至数周。通过平衡尽可能高的计算吞吐量、共享内存和芯片间带宽,以及尽可能高的能效和高效的计算时间,我们打造出一个系统,其每个Pod的计算性能比上一代产品提升近3倍,从而加速创新,确保我们的客户继续引领行业发展。
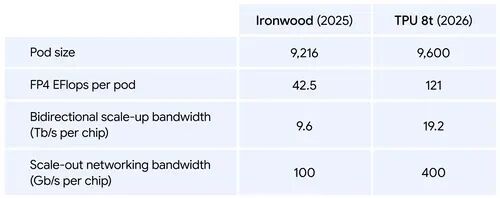
- 规模庞大:单个 TPU 8t 超级芯片组现已可扩展至 9,600 个芯片和 2 PB 共享高带宽内存,芯片间带宽是上一代的两倍。该架构可提供 121 ExaFlops 的计算能力,并允许最复杂的模型利用单个海量内存池。
- 最大利用率:TPU 8t 还集成了速度提升 10 倍的存储访问,并结合 TPUDirect 将数据直接拉入 TPU,从而有助于确保端到端系统的最大利用率。
- 近乎线性扩展:我们全新的Virgo 网络,结合 JAX 和 Pathways 软件,意味着 TPU 8t 可以在单个逻辑集群中为多达一百万个芯片提供近乎线性的扩展。
除了卓越的性能之外,TPU 8t 还通过一套全面的可靠性、可用性和可维护性 (RAS) 功能,力求实现超过 97% 的“有效吞吐量”(衡量有效计算时间的指标)。这些功能包括:对数万个芯片进行实时遥测;自动检测并绕过故障的 ICI 链路(无需中断作业);以及光路交换 (OCS) 技术,无需人工干预即可在故障发生时重新配置硬件。
每次硬件故障、网络停滞或检查点重启都会导致集群停止训练,而在前沿训练规模下,每一个百分点都可能转化为数天的活跃训练时间。
在智能体时代,用户期望能够提出问题、委派任务并获得结果。
TPU 8i 旨在处理众多专业智能体复杂、协作、迭代的工作,这些智能体通常会在复杂的流程中“集群”协作,为最具挑战性的任务提供解决方案和洞见。我们通过四项关键创新重新设计了技术栈,以消除“等待室”效应:
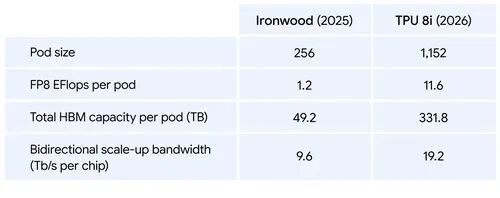
- 突破“内存墙”:为了防止处理器闲置,TPU 8i 将 288 GB 高带宽内存与 384 MB 片上 SRAM 相结合——比上一代多 3 倍——使型号的活动工作集完全在芯片上。
- 得益于 Axion 架构,效率显著提升:我们每台服务器的物理 CPU 主机数量翻了一番,并采用了我们定制的基于 Axion Arm 架构的 CPU。通过使用非均匀内存架构 (NUMA) 进行隔离,我们优化了整个系统,从而实现了卓越的性能。
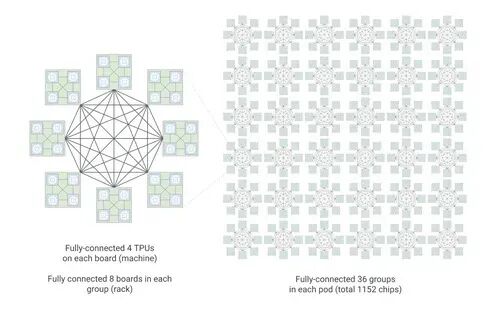
- 扩展 MoE 模型:对于现代混合专家 (MoE) 模型,我们将互连 (ICI) 带宽提高了一倍,达到 19.2 Tb/s。我们新的 Boardfly 架构将最大网络直径减少了 50% 以上,确保系统作为一个统一、低延迟的单元运行。
- 消除延迟:我们全新的片上集体加速引擎 (CAE) 可卸载全局操作,将片上延迟降低至多 5 倍,从而最大限度地减少延迟。
与上一代产品相比,这些创新技术每美元的性能提高了 80%,使企业能够以相同的成本服务近两倍的客户量。
这款第八代 TPU 也是我们共同设计理念的最新体现,其每一项规格都旨在解决人工智能面临的最大挑战。
Boardfly拓扑结构是专门为满足当今最强大的推理模型的通信需求而设计的。
- TPU 8i 中的 SRAM 容量是根据生产规模推理模型的 KV 缓存占用空间来确定的。
- Virgo Network 架构的带宽目标源自万亿参数训练的并行性要求。
而且,这两款芯片首次都运行在谷歌自家基于 ARM 的 Axion CPU 主机上,这使我们能够优化整个系统,而不仅仅是芯片,以提高性能和效率。
这两个平台都原生支持 JAX、MaxText、PyTorch、SGLang 和 vLLM 等开发者常用的框架,并提供裸机访问,让客户无需虚拟化即可直接访问硬件。包括 MaxText 参考实现和用于强化学习的 Tunix 在内的开源贡献,为从功能实现到生产部署提供了便捷的途径。
大规模节能设计
在当今的数据中心,电力(而不仅仅是芯片供电)是一个关键的制约因素。为了解决这个问题,我们优化了整个堆栈的效率,并集成了电源管理功能,可根据实时需求动态调整功耗。TPU 8t 和 TPU 8i 的每瓦性能比上一代产品 Ironwood 提升高达两倍。
但谷歌的效率衡量标准并非仅限于芯片层面,而是从芯片到数据中心的系统级承诺。例如,我们将网络连接与计算集成在同一芯片上,显著降低了TPU芯片间数据传输的能耗。甚至我们的数据中心也是与TPU芯片协同设计的。我们在硬件和软件方面不断创新,使我们的数据中心单位电力下的计算能力比五年前提高了六倍。
TPU 8t 和 TPU 8i 延续了这一发展轨迹。它们均采用我们第四代液冷技术,能够维持风冷无法实现的性能密度。通过掌控从 Axion 主机到加速器的全栈设计,我们可以优化系统级能效,而这在主机和芯片独立设计的情况下是无法实现的。

面向智能体的基础设施
每一次重大的计算转型都需要基础设施的突破,智能体时代也不例外。基础设施必须不断发展,才能满足自主智能体在推理、规划、执行和学习的持续循环中运行的需求。
TPU 8t 和 TPU 8i 正是我们应对这一挑战的答案:
两种专为重新定义人工智能可能性而打造的专用架构,从构建功能最强大的 AI 模型,到完美协调的智能体集群,再到管理最复杂的推理任务,无所不能。这两款芯片将于今年晚些时候正式上市,并可作为谷歌 AI 超级计算机的一部分使用。该超级计算机将专用硬件(计算、存储、网络)、开源软件(框架、推理引擎)和灵活的消费模式(编排、集群管理和交付模型)整合到一个统一的平台中。
智能体计算将重新定义一切皆有可能。我们非常激动地宣布,为推动这一变革,我们不断创新,如今推出了最新的产品——TPU 8i 和 8t。

是说芯语转载,欢迎关注分享
合作洽谈,进入公众号:服务—>商务合作