五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库谁来为端侧大模型“功耗墙”破局?
| 端侧AI元年:千亿赛道的机遇与挑战
2025年被业界公认为“端侧AI元年”,随着AI手机、人形机器人、可穿戴设备等终端产品的爆发式增长,端侧大模型正从技术概念走向规模化应用,催生了对低功耗、高性能端侧AI芯片的海量需求。据测算,全球端侧AI市场将从2025年的3219亿元增长至2029年的1.2万亿元,复合年增长率高达39.6%,千亿赛道已然浮出水面。但繁荣背后,端侧大模型的落地始终被三大核心痛点束缚,成为制约行业发展的“三座大山”,而不同企业选择的技术路径差异,进一步加剧了赛道分化,也为具备创新思维的初创企业留下了破局空间。
第一个核心痛点,是“功耗-算力-成本”的不可能三角。端侧终端多依赖电池供电,对功耗有着严苛要求(通常需控制在5W以内),但大模型复杂度的提升,又对芯片算力提出了极高的需求:要稳定运行7B以上全量级大模型,才能满足高阶智能体验,这就导致多数芯片要么牺牲功耗换取算力(如传统GPU/NPU),要么降低算力控制功耗(如常规端侧ASIC芯片),难以实现三者的平衡。
第二个痛点,是“内存墙”难题突出,多数端侧芯片采用传统平面IO(LPDDR)设计,但计算单元与内存之间的数据搬运能耗高、效率低,带宽利用率普遍不足50%,不仅制约了推理速度,更进一步推高了功耗。尽管MOE结构大模型出现可以每次稀疏激活专家,但是通常端侧30B模型激活的3B专家无法达到智能涌现。因此大模型在端侧的有效应用,还是需要通过三维集成,从而根本解决低功耗、高带宽传输稠密模型参数及KV内存的挑战。
第三个痛点,是场景适配的矛盾,要么追求全场景覆盖导致产品泛化、针对性不足,要么局限于单一终端场景导致市场覆盖面窄,无法适配端侧大模型“多场景融合”的发展趋势,同时开源智能体的崛起也对芯片的场景适配能力提出了新要求。
| 行业困局:两条主流技术路径的分化与局限
痛点的背后,是端侧AI芯片行业两条主流技术路径的分化,这两条路径虽各有侧重,却均未能彻底破解行业困境,也构成了当前赛道的竞争格局。

第一条路径,是国际巨头主导的传统GPU/NPU架构路线。这类路线依托成熟的技术积累,能够提供较强的算力支撑,可稳定运行大模型,但核心短板极为明显:一是功耗居高不下,动辄50W以上的功耗,完全无法适配手机、可穿戴设备等电池供电的终端;二是生态封闭,芯片与软件的适配性较差,灵活调整空间有限,难以适配国内多样化的端侧场景;三是成本高昂,且受限于技术封锁,核心架构与IP依赖海外,无法满足国内市场对供应链安全的需求。即便部分国际巨头推出端侧优化版本,也多是云端芯片的简化版,未能从架构层面解决低功耗与高性能的矛盾,如Arm推出的AGI CPU-1虽单核心功耗控制较好,但整体热设计功耗仍达300瓦,无法适配小型终端场景。
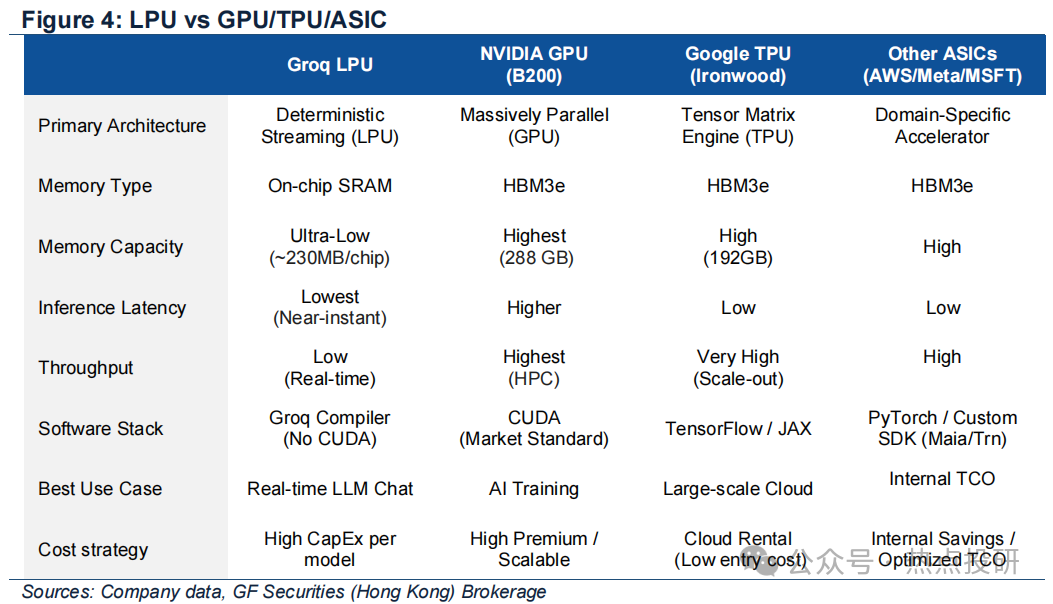
第二条路径,是国内多数同行采用的常规TPU或ASIC架构路线。这类路线精准抓住了端侧终端的低功耗需求,将芯片功耗控制在5W左右,但同样存在难以突破的局限:一是算力不足,多局限于4B以下小模型的运行,无法支撑7B以上全量级大模型,导致智能体验大打折扣;二是“内存墙”难题未得到根本解决,平面IO设计的带宽利用率偏低,能效比难以提升;三是部署模式僵化,多采用固定算力设计,一款芯片仅能适配单一终端场景,研发与部署成本高,难以实现规模化落地;四是核心IP或工艺多依赖海外,国产化程度不足,无法实现真正的自主可控,与国内半导体产业国产替代的发展趋势相悖。
两条主流路径的局限,让端侧大模型芯片赛道陷入了“两难困境”:要么高功耗、高算力、高成本,要么低功耗、低算力、场景窄。
| 破局之道: 迈特芯技术、模式、定位的三重创新
在这样的行业背景下,成立仅2年的深圳初创企业迈特芯,并未跟随主流路径,而是通过技术、模式、定位的三重创新,走出了一条差异化破局之路——其核心依托3D分布式TPU技术、类矿机可扩展模式、龙虾终端定位的协同发力,不仅破解了行业痛点,更形成了区别于所有竞争对手的独特优势,成为端侧大模型低功耗芯片赛道的新锐探索者。
作为长期关注端侧算力领域的观察者,迈特芯的价值,不仅在于推出了一款适配端侧场景的芯片,更在于其重构了端侧大模型芯片的发展逻辑,为行业提供了一条可落地、可规模化的创新路径。
要理解这一独特的技术布局,首要需厘清其核心技术——3D分布式TPU与LPU之间的关系,这也是解读其技术优势的关键。
事实上,3D分布式TPU是LPU技术路线的底层核心架构,LPU则是基于这一架构研发的、面向端侧大模型推理的专用芯片及相关产品体系的统称。
| 核心技术:3D分布式TPU与LPU技术路线
从技术角度看,3D分布式TPU技术,跳出了传统架构的局限,从根源上破解了“功耗-算力-内存墙”的三重难题,这也是其与国内外竞争对手最核心的技术差异。不同于国际巨头的传统GPU/NPU架构,也区别于国内同行的常规TPU设计,采用立方脉动架构与3D分布式IO(3D-DRAM近存计算)的深度融合,构建了全新的技术体系,且已通过全国产28nm工艺实现流片,摆脱了海外技术与供应链的依赖。

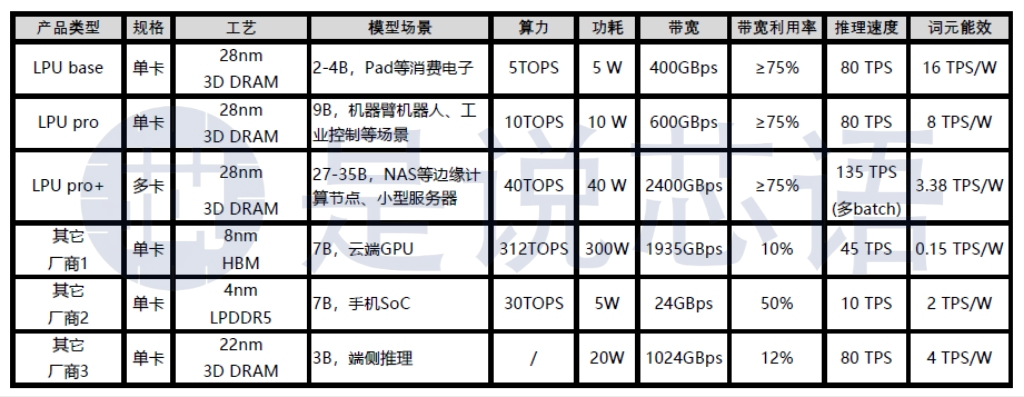
基于3D分布式TPU架构的LPU技术路线,迈特芯产品落地的核心亮点在于高性能与高能效的双重领先。其LPU芯片技术路线采用全国产工艺及传统制程加3D DRAM堆叠,功耗平均5W,带宽高达600GBps,带宽利用率达到80%,大模型推理速度高达80tps,这种技术创新的核心价值,体现在三个层面。
其一,彻底解决“内存墙”难题,3D分布式IO实现了计算单元与内存的直连,将带宽利用率提升至80%左右,远超国内同行50%以下的平均水平,也打破了国际巨头“高带宽必高功耗”的固有认知——数据无需经过中间环节搬运,不仅提升了推理速度,更大幅降低了数据搬运过程中的能耗,这是架构层面的重构,而非简单的参数优化。
其二,实现能效比的跨越式提升,依托3D分布式TPU 架构,其中5W可稳定运行2-9B模型、性能(近百token)可媲美高端算力芯片,却将功耗降低一个量级,词元能效比(token/W)大大领先其他技术路线。技术优势尤为明显。
其三,国产化落地的领先性,核心架构、IP全自研,基于全国产工艺流片,完全摆脱了海外IP与工艺的依赖,契合国内半导体产业国产替代的发展趋势,这也是国内多数同行尚未实现的突破,更是国际巨头无法适配国内市场的核心短板。同时已完成Qwen、GLM、miniCPM等主流开源大模型的部署,实现了对多模型的广泛适配,打破了部分芯片仅能适配单一模型的局限,进一步强化了其产品的实用性与竞争力,真正实现了性能和能效的国际领先。
从行业角度看:3D分布式TPU技术的最大意义,在于打破了“低功耗与高性能不可兼得”的行业固有认知,为端侧大模型芯片提供了全新的技术路线参考,也为LPU产品的性能领先奠定了坚实基础。
| 迈特芯推理芯片的产品矩阵:
MC_mega_188(Base系列), 3D DRAM容量为2.5GB, 满足低功耗要求,典型适用模型为0.5B-3B。 | 具身智能大小脑盒子  |
龙虾AI学习机
| |
龙虾NAS,龙虾盒子  | |
| 8 芯片MC_mega_488(Pro Max系列)推理卡,3D DRAM容量为80GB,采用分布式方案,典型适配模型为122B。 |  |

| 部署模式创新:类矿机可扩展模式
如果说3D分布式TPU是迈特芯的技术根基,那么类矿机可扩展模式,则是其破解端侧算力规模化落地难题的关键创新,也是其在部署模式上区别于竞争对手的核心特色。当前,行业内的部署模式主要分为两种:国际巨头的云端协同模式,端侧芯片仅作为辅助算力,核心算力仍依赖云端,虽能实现算力扩展,但存在隐私泄露、延迟较高的问题,不符合端侧大模型“本地独立运行”的发展趋势;国内同行的固定算力模式,一款芯片仅适配单一场景,部署成本高、灵活性差,难以实现规模化落地。

创新性采用的类矿机可扩展模式,跳出了这两种模式的局限,其核心逻辑是模块化设计,借鉴矿机设备可堆叠、可扩展的特性,让搭载3D分布式TPU技术的LPU系列产品(单芯片、推理卡、类矿机),能够根据实际场景需求,实现多单元协同部署,灵活调整算力规模。这种模式的优势,在于实现了“灵活适配+成本优化”的双重突破:对于平板pad、机器臂等小型终端,可单元部署,满足轻量化算力需求;对于NAS盒子、PC等,可多单元卡分布式集成;对于AI-token工厂可做类矿机提升算力规模。这种可扩展方式无需为不同场景单独研发芯片,大幅降低了研发与部署成本。
更重要的是,这种模式与3D分布式TPU技术形成了深度协同——低功耗的技术特性,让多单元堆叠无需担心功耗超标;可扩展的部署模式,让3D分布式TPU的算力价值得到充分发挥,形成了“技术+模式”的协同优势。类矿机可扩展模式的创新,本质上是对端侧算力部署逻辑的重构,它打破了“一款芯片对应一个场景”的固有模式,让端侧大模型的规模化落地变得更具可行性,这也是区别于所有竞争对手的重要亮点。
| 场景定位:产品与市场的差异化竞争
在技术与模式之外,迈特芯聚焦“龙虾终端”的场景定位,进一步强化了其差异化优势,也精准契合了端侧大模型“智能体本地化”的发展趋势,这与国内外竞争对手的场景布局形成了鲜明对比。当前,国际巨头的场景定位偏向全场景覆盖,试图兼顾消费电子、工业、政务等所有领域,但这种宽泛的定位导致产品针对性不足,无法深度适配某一细分场景的需求,且功耗与成本难以平衡;国内同行则多聚焦于单一场景,如专门适配手机或机器人,虽能实现场景深度适配,但市场覆盖面较窄,难以形成规模化效应,也无法应对端侧大模型“多场景融合”的发展趋势。
“龙虾终端”,核心是适配开源AI智能体“龙虾”(OpenClaw)的本地化运行需求。这款开源智能体可通过本地自主执行复杂任务、支持技能包扩展及IM嵌入式交互,能替人执行终端命令、读写文件、收发邮件、管理日程,无需使用者懂代码或操作系统,其“脚手架”式架构降低了AI使用门槛,推动全民参与AGI生态共建,是拥抱新质生产力的重要工具,也是当前端侧大模型落地的重要载体。核心定位就是为龙虾智能体的本地化运行提供高词元效率的AI端侧芯片,这种精准定位让其能够集中资源,实现技术与场景的深度适配:依托3D分布式TPU技术,为龙虾智能体提供低功耗、高性能的本地算力支撑,解决其本地化运行的算力瓶颈;借助类矿机可扩展模式,适配龙虾智能体在不同终端场景的算力需求,从消费电子到具身智能,实现场景的灵活延伸。
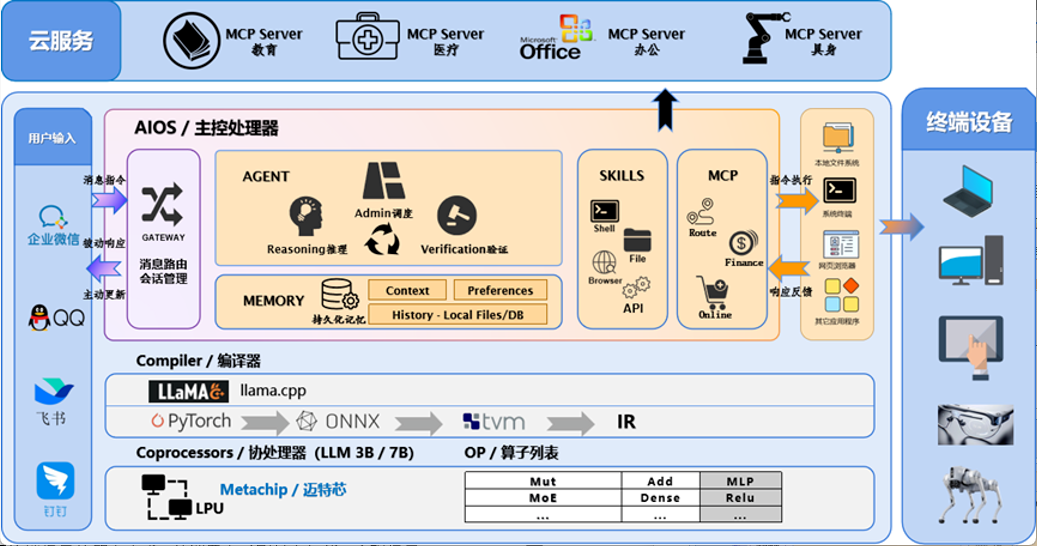
迈特芯端侧超级智能体操作系统架构:MetaClaw
迈特芯的龙虾终端MetaClaw,基于本地大模型(7B-32B)实现token自由,从而支持本地的NAS + IoT + Video等智能应用。作为本地化模型调度中枢,支持Hermes自我学习Skills插件挂载,用户行为记忆沉淀、及本地知识库增量更新,个人数据不出设备,通过Claw做终端网关连接各种终端设备。支持 Markdown、PDF、Word、PPT、音频、视频等多格式导入,及多个智能体场景:家庭政务龙虾、教育健康龙虾、具身龙虾等。
与竞争对手相比,这种定位的优势在于“精准性与扩展性的平衡”:既避免了国际巨头“全场景覆盖”的泛化问题,实现了龙虾智能体在端侧场景的深度适配及真正落地;也解决了国内同行“单一场景聚焦”的局限,通过龙虾智能体(盒子、pad等)场景延伸,覆盖了更多终端类型。
此外,迈特芯与多家上下游企业(麒麟软件、全志科技等)展开生态联合。聚焦龙虾终端的定位,不仅在激烈的赛道中找到了差异化切入点,更抓住了端侧大模型“智能体本地化”的发展趋势,为端侧芯片的场景化布局提供了新的思路,这一点也是多数竞争对手未能实现的。
迈特芯即将推出的三类主打产品,均基于LPU技术路线,针对不同市场需求和应用场景进行精准布局,具有高性能、低功耗、高集成度等特点,能够满足客户的多样化需求,进一步完善了其差异化竞争优势。其一,LPU base系列,采用全国产工艺及传统制程加3D DRAM,聚焦AI pad等消费电子终端,以平均5W的低功耗、大于80Token/s的推理速度,为终端设备提供本地大模型支撑,适配龙虾pad等开源智能体的本地化运行需求;其二,LPU pro系列,聚焦机械臂、工业控制场景,提供轻量化,低成本的本地推理解决方案;其三,LPU pro+ 系列,侧重边缘NAS盒子、PC及token工厂等场景,提供高性能低成本的解决方案。三类产品形成互补,覆盖消费电子、工业、边缘计算等多领域,构建了完整的产品矩阵,也让其市场覆盖更具针对性与竞争力。
| 竞争格局与迈特芯差异化优势
当前,端侧AI芯片赛道竞争日趋激烈,不仅面临着英伟达、高通等具有全球影响力的国际巨头的直接竞争,同时也需应对国内同行的同质化竞争压力。从竞争格局来看,英伟达、高通凭借成熟的技术积累、完善的生态布局和强大的品牌影响力,在高端端侧芯片市场占据主导地位——英伟达的端侧GPU虽算力强劲,但功耗居高不下,难以适配电池供电的小型终端;高通的骁龙AI芯片聚焦手机场景,但其核心架构仍依赖传统设计,带宽利用率与能效比不及LPU路线。而国内同行多采用常规2D IO或传统NoC路线,其架构利用率低、功耗高、难扩展、智能体适配性差,或采用3D IO架构的无法解决大算力3D堆叠带来的散热问题,因此难以形成核心竞争力。
作为对比,迈特芯的LPU路线依托3D分布式TPU架构,实现了带宽利用率、能效比、推理速度的三重领先,核心参数均达到国际先进水平,且基于全国产工艺,摆脱了海外IP与供应链的依赖,契合国内半导体产业国产替代的发展趋势;在产品上,三类主打产品定位精准,覆盖多场景需求,且实现了多主流模型的适配,实用性更强;在市场上,已与众多终端龙头客户建立合作关系,为其提供端侧AI算力解决方案,积累了宝贵的客户资源和市场口碑,进一步强化了其市场竞争力。
从行业角度看,迈特芯的竞争优势,并非单一维度的技术或产品优势,而是“技术-模式-定位”三者形成的协同壁垒——3D分布式TPU技术解决了“低功耗+高性能+内存墙”的核心痛点,类矿机可扩展模式解决了规模化落地的难题,龙虾终端定位实现了场景的精准适配,再加上2026年初全国产工艺流片的落地优势,让其在赛道中形成了独特的竞争优势。这种协同壁垒,既区别于国际巨头“高功耗、封闭生态、泛场景”的模式,也不同于国内同行“单技术、固定模式、单一场景”的局限,更跳出了行业“两难困境”,为端侧大模型芯片的发展提供了全新的可能。
| 公司背景及使命
作为一家成立仅2年的初创企业,突围并非偶然,其背后是顶尖团队的支撑——由南科大余浩教授(国家级领军人才、两获吴文俊人工智能奖、3DIC国际最佳论文)领衔,核心团队汇聚大厂芯片及系统专家,覆盖芯片全产业链,形成了“顶尖学术引领+资深产业落地”的黄金组合。团队稳扎稳打,2023年ASIC投片验证TPU,2024年FPGA原型机验证分布式IO大模型,2025年全国产3D工艺设计,2026年流片量产3D分布式TPU芯片及推理卡。
未来,迈特芯计划2026年底实现样片量产,2027年大规模落地,持续迭代14nm/7nm工艺,从而降低功耗提升词元能效比,进一步强化三大核心优势,构建端侧大模型芯片生态。
端侧大模型的规模化落地,迫切需要跳出传统技术路径的局限,而迈特芯的探索,不仅为自身赢得了发展机遇,更为整个行业提供了宝贵的借鉴。在国产替代加速与端侧AI爆发的双重浪潮下,只有聚焦行业痛点、坚持技术创新、找准场景定位,才能在激烈的赛道竞争中脱颖而出。迈特芯作为“端侧大模型低功耗芯片先行者”,其差异化的发展路径(3D分布式TPU架构),将推动端侧智能从“概念”走向“现实”,让AI新硬件终端真正拥有独立的“智能大脑”,为AI-token经济提供了国产化路径的方案,也为我国半导体产业破解“卡脖子”难题、实现自主可控注入新的活力。迈特芯,让端侧智能体无处不在,让龙虾都有自己的家。

是说芯语原创,欢迎关注分享
合作洽谈,进入公众号:服务—>商务合作