 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库谷歌第八代TPU详解:联手博通与联发科挑战英伟达!

当地时间2026年4月22日,在拉斯维加斯举行的Google Cloud Next '26大会上,谷歌正式发布了第八代张量处理器(TPU)。这是谷歌史上首次将AI训练与推理任务拆分至两款独立芯片——专为模型训练设计的TPU 8t与专为推理优化的TPU 8i,标志着其AI硬件战略的重大转向。

与此同时,谷歌宣布其第七代TPU Ironwood正式向云客户开放,并预告了与英伟达的深度合作——将在2026年下半年成为首家提供NVIDIA Vera Rubin NVL72超级计算机的云服务商。
为何拆分训练与推理?
谷歌做出这一战略调整的根本原因,是AI计算负载的日益分化。谷歌AI与基础设施高级副总裁兼首席技术官Amin Vahdat在官方博客中指出:“随着AI智能体的兴起,我们确定业界将受益于针对训练和推理需求分别进行专门优化的芯片。”
具体而言,训练任务追求极致的吞吐量与规模扩展能力,需要芯片具备最高的计算密度和内存带宽,以在数周甚至数月内处理万亿级参数。而推理任务则对延迟和并发更为敏感——当数百万个AI智能体同时运行时,响应速度至关重要,而对峰值算力的要求相对较低。
Amin Vahdat在大会现场明确表示:“这两款芯片都是从头开始专门为训练和推理设计的,而非彼此衍生产品。它们的规格、能力、互联方式都因各自需求而专门设计。
Alphabet首席执行官桑达尔·皮查伊则强调,这一新架构旨在以低成本提供大规模吞吐量和低延迟,满足数百万个AI智能体同时运行的需求。
TPU 8t:大规模预训练旗舰芯片
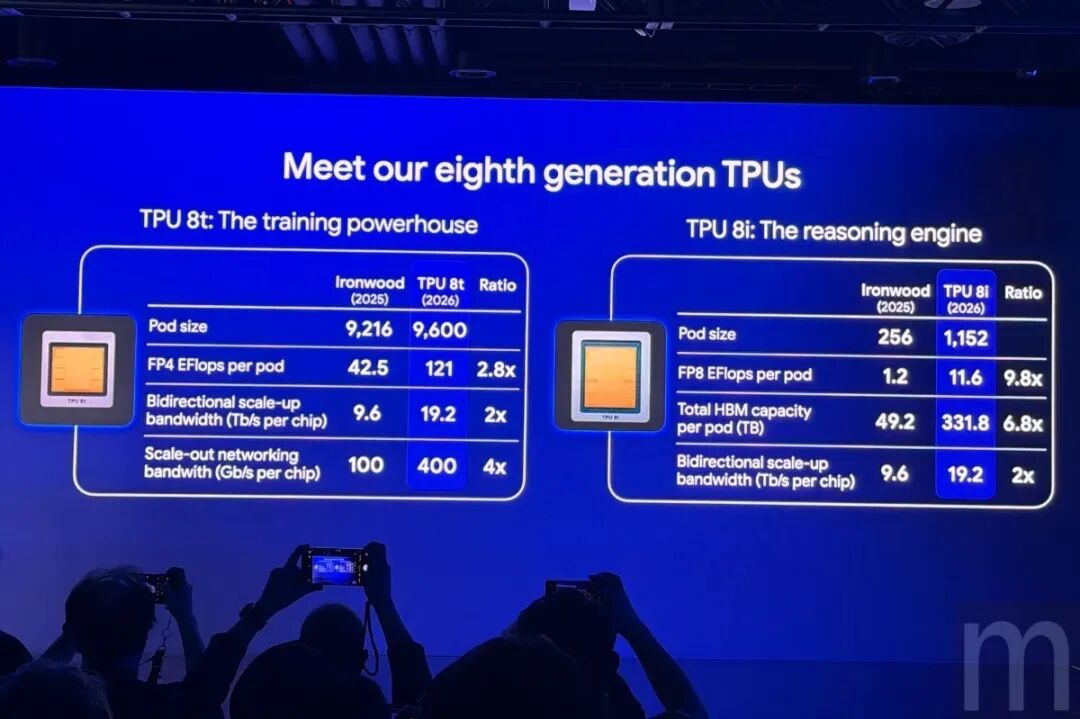
TPU 8t由谷歌和博通共同设计,是谷歌为超大规模AI模型训练打造的旗舰芯片。单个超级计算节点最多可集成9,600块TPU 8t芯片,配备2 PB高带宽内存,每Pod计算性能达121 exaflops(FP4精度),较上一代Ironwood提升约3倍,同等价格下性能提升2.8倍。通过JAX与Pathways框架,可将分布式训练扩展至单一集群超过100万块芯片。
在架构设计上,TPU 8t采用双计算芯粒加单I/O芯粒的架构,配备8组12层堆叠的HBM3e高带宽内存。芯片搭载了SparseCore专用加速器,专门处理大语言模型查找过程中常见的不规则内存访问问题;同时支持原生FP4浮点精度,矩阵运算单元算力吞吐直接翻倍,海量数据搬运功耗大幅下降。

为匹配海量数据吞吐需求,谷歌全新研发了Virgo互联架构,训练场景数据中心网络带宽最高提升至前代4倍。该架构采用高基数交换机减少层级,扁平化两层无阻塞拓扑结构,单套网络可互联13.4万颗TPU 8t芯片,无阻塞二分带宽高达47Pbps,芯片间互联带宽较上一代提升2倍。在存储访问方面,TPU 8t通过TPU直连RDMA和TPU直连存储两项技术,绕过CPU实现TPU与网卡、高速存储之间的直接内存访问,存储访问速度提升10倍。此外,芯片还拥有一整套可靠性、可用性与可维护性能力,包括实时遥测监控、自动检测并绕过故障链路、以及无需人工干预自动重构硬件拓扑的光路电路交换技术。
TPU 8i:高并发推理专属平台

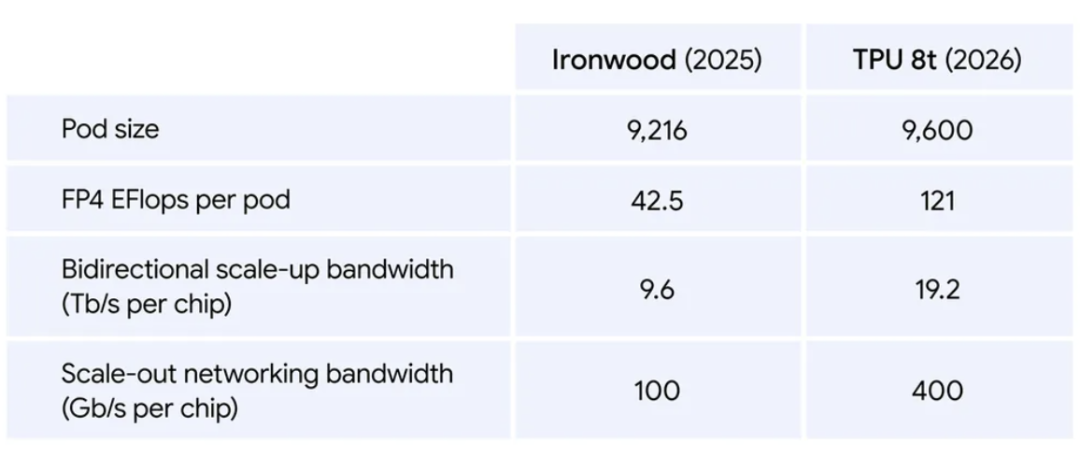
TPU 8i首次由谷歌和联发科合作设计,专注于AI推理场景,旨在消除“等待室效应”——即用户请求被有意排队或延迟以实现硬件利用率最大化的情况。单个Pod可扩展至1,152块芯片,提供11.6 exaflops FP8计算性能,较Ironwood同等价格下性能提升80%,每瓦性能较上一代提升117%。
TPU 8i最显著的特征是搭载了384MB片上SRAM缓存,容量是上一代Ironwood的三倍。这一设计的核心价值在于可将更大的KV Cache保留在芯片上,大幅减少长上下文解码时芯片核心的空闲等待时间,实现更快的文本生成速度和更低的延迟。芯片还引入了全新的集合通信加速引擎(CAE),专门加速自回归解码与思维链推理所需的规约与同步运算,多核心结果聚合几乎零延迟,片上集合通信延迟较前代降低5倍。单颗TPU 8i内置两颗张量核心和一颗片上CAE,替代前代Ironwood的四颗稀疏计算核心。

TPU 8i最大的架构创新在于放弃了TPU传统的3D环形拓扑结构,转而采用全新的Boardfly层级互联拓扑。在MoE(混合专家模型)与推理模型时代,任意芯片都需要随时互通Token数据,跳转次数直接决定性能。对于8×8×16规模(1024芯片)的3D环形网络,最远芯片通信需要16跳;而Boardfly拓扑在同等规模下仅需7跳,网络直径缩减56%。
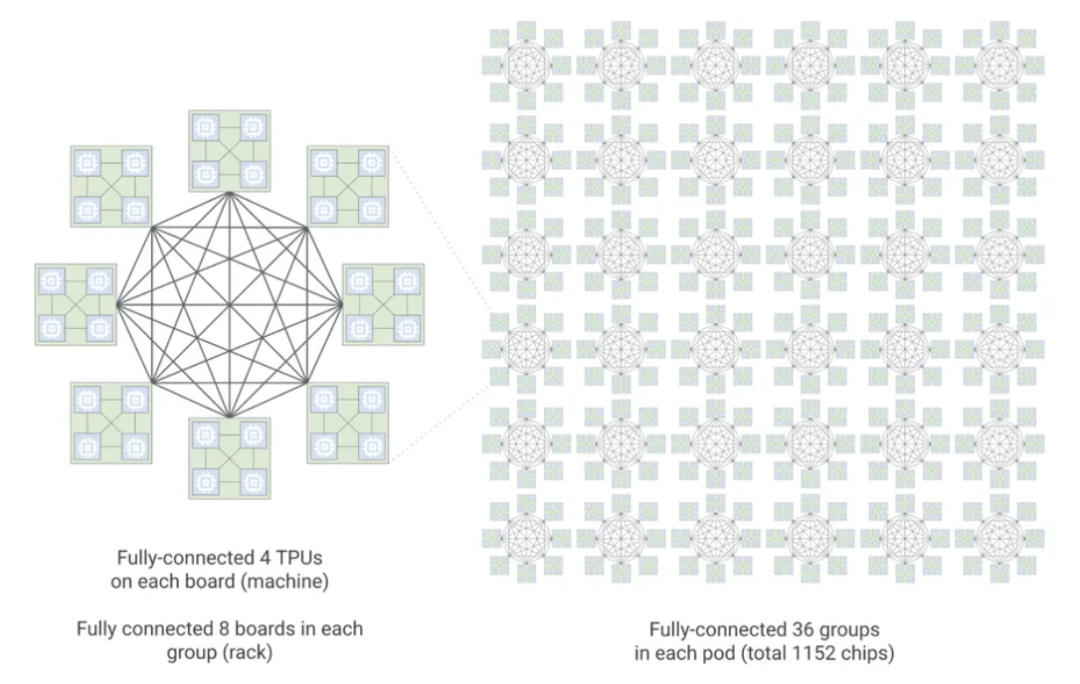
Boardfly采用分层设计:4颗芯片环形互联构成基础单元,8块板卡通过铜缆全互联构成本地算力组,36个算力组通过光开关互联构成最高1024颗芯片的集群。
在这种结构下,任意两枚芯片之间的通信最多只需经过7次跳转,全对全通信延迟改善最高50%,这对混合专家模型和频繁的跨芯片令牌路由极为有利。TPU 8i配备288GB HBM高带宽内存,结合384MB片上SRAM,确保模型的活跃工作集能够完全保留在芯片内部运行,从根本上解决“内存墙”问题。
基于2nm制程,2027年底量产
两款第八代TPU芯片均搭载了谷歌自研的Arm架构Axion CPU作为主控,彻底解决数据预处理延迟导致的主机算力瓶颈。芯片采用台积电2nm制程工艺制造,目标在2027年底量产,并由公司第四代液冷技术支持散热。

在软件生态方面,第八代TPU支持JAX、PyTorch、Keras及vLLM等主流框架,原生PyTorch支持现已进入预览阶段,用户可直接迁移模型而无需修改代码。
Anthropic已承诺采用
谷歌TPU的采用率正在持续攀升。Anthropic已承诺采用数GW等级的TPU算力,2027年上线规模将扩展至3.5吉瓦,成为第八代TPU的锚定客户。此外,Citadel Securities已利用TPU打造量化研究软件,美国能源部旗下17个国家实验室全面采用基于TPU的AI协同科学家系统。
分析师普遍认为,谷歌通过将TPU一拆为二,是对AI训练与推理需求加速分化的直接回应,有助于大幅提升特定场景下的单位算力性价比,从而降低云客户部署成本。
编辑:芯智讯-浪客剑
行业交流、合作请加微信:icsmart01
芯智讯官方交流群:221807116





