云巨头、服务器厂商密集支持,DeepSeek赢麻了。芯东西4月24日报道,刚刚,华为昇腾直播解读DeepSeek-V4技术,并披露昇腾950性能表现。截至发稿,华为昇腾、寒武纪、海光信息、摩尔线程、沐曦股份、百度昆仑芯、阿里平头哥真武、天数智芯8家国产AI芯片品牌和英伟达均已适配DeepSeek-V4。▲昇腾950性能表现(图源:昇腾CANN直播截图)
此外,华为云、腾讯云、PPIO、用友、联想智能云、天翼云息壤、云工场科技等云服务商,宁畅、长江计算、百信、昆仑技术等服务器企业,郑州人工智能计算中心等算力服务提供商、快手万擎等MaaS平台,都第一时间宣布适配或上架DeepSeek-V4模型服务。网易智企、万格智元、极光、网易有道旗下Agent产品宣布接入DeepSeek-V4。▲截至发稿,官宣支持DeepSeek模型的AI芯片企业(芯东西制表)
根据DeepSeek-V4技术报告,其并细粒度专家并行(EP)方案同时在英伟达GPU和华为昇腾NPU上完成验证,相比非融合基线在通用推理场景中实现1.50-1.73倍加速,在对延迟敏感的强化学习推演和高速Agent服务场景中最高可达1.96倍。▲DeepSeek-V4技术报告
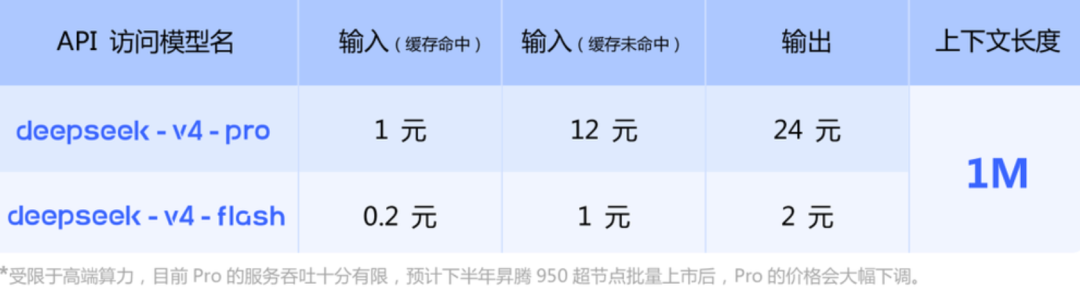
据DeepSeek公众号披露,受限于高端算力,目前DeepSeek-V4-Pro的服务吞吐十分有限,预计下半年昇腾950超节点批量上市后,其价格会大幅下调。▲DeepSeek官方文章
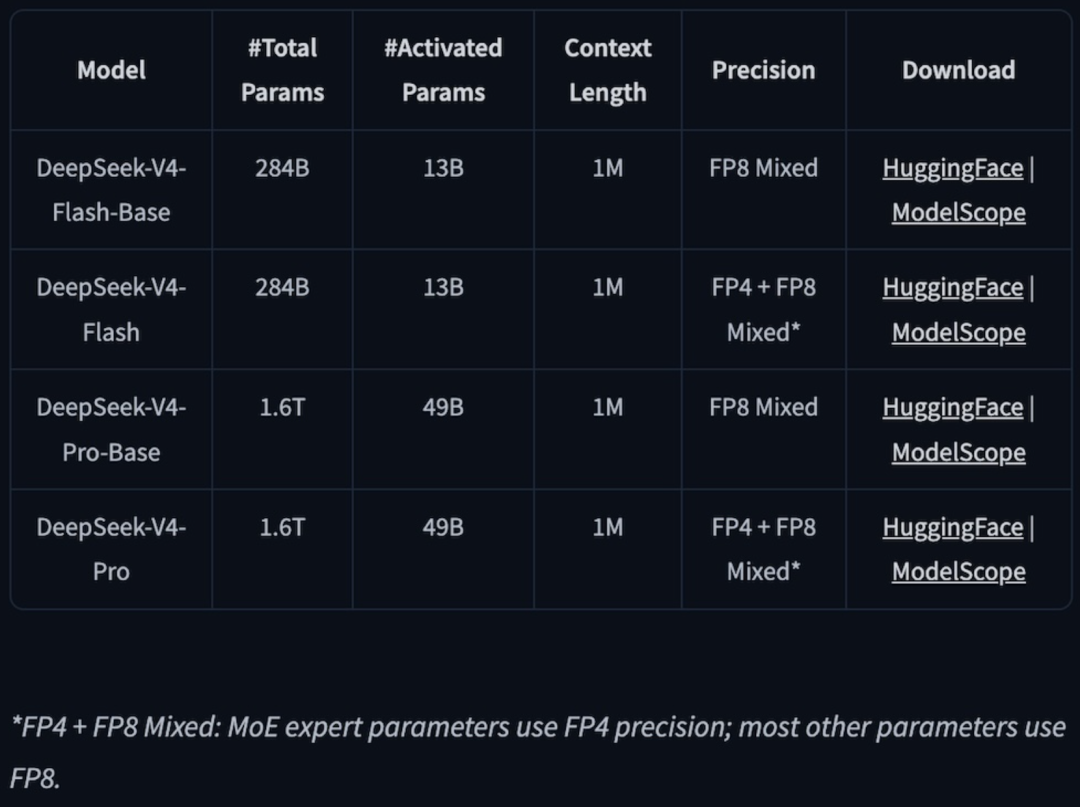
DeepSeek-V4模型采用FP4+FP8混合精度训练,在脱离英伟达生态背景下,其大概率是基于深度定制的内部格式。网友猜测,该模型依托华为昇腾950超节点集群完成训练,从侧面印证华为底层算力架构与低精度混合训练技术,已具备支撑万亿级大模型的能力。▲DeepSeek在Hugging Face上的模型卡
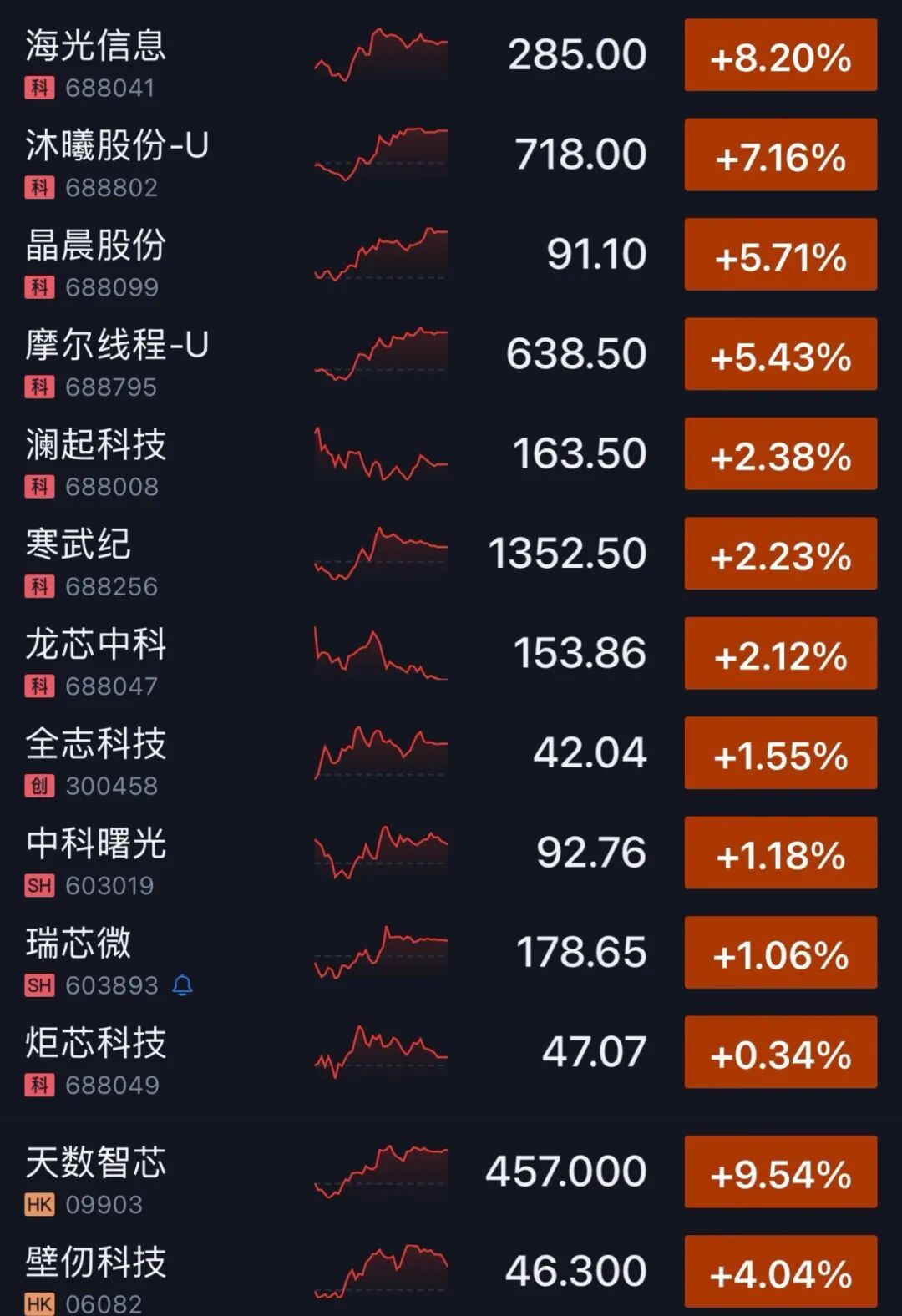
智源研究院众智FlagOS社区在8款AI芯片上适配DeepSeek-V4时,实现了三大技术突破:支持8种以上芯片的全算子替代、解除张量并行最多单机8卡限制、支持从“FP4+FP8混合精度”到BF16的精度转换。截至今日收盘,AI算力板块股价大涨,在A股,海光信息以8.2%的增幅领涨、寒武纪增幅为2.23%,在港股,天数智芯的涨幅达到9.54%。▲AI算力板块股价变化
支撑DeepSeek-V4毫秒级推理、超高并发推理
首发适配DeepSeek-V4后,华为昇腾今日16点开启了“基于CANN的训推优化实践”直播。在直播中,华为相关研发人员提到其基于CANN进行了全链路优化:1、昇腾950超节点支撑DeepSeek V4毫秒级推理,背后有三大黑科技昇腾950超节点实现DeepSeek V4-Pro 20ms和DeepSeek V4-Flash 10ms低时延推理。这得益于昇腾950代际底层架构的三大升级:
首先是原生精度加速,其全面支持FP8、MXFP8、MXFP4等数据格式,在保证模型精度的同时,可实现内存占用降低50%+,计算能力翻倍。
其次是稀疏访存优化,针对MoE模型的离散访存特征,他们通过大幅提升硬件级稀疏访存能力,解决了专家路由过程中的带宽瓶颈。
最后是Vector与Cube共享Memory,其采用创新存储架构设计,实现了向量单元(Vector)与矩阵单元(Cube)的Memory共享,消除大量片上数据搬运开销,降低了端到端推理时延。
根据华为官方信息,昇腾950超节点还从基础器件、协议算法到光电互联,实现了系统级突破,支持用户以64卡为步长按需扩展,可实现8192卡无收敛全互联,提供业界最大Scale Up能力。华为与DeepSeek联合定义了昇腾超节点架构,专门解决大模型超长上下文推理的时延高、吞吐低、成本贵三大痛点,同时能做到万卡级大规模扩展,并靠NAND SSU做低成本大容量KV Cache,支撑4K~1M全长度长序列应用。
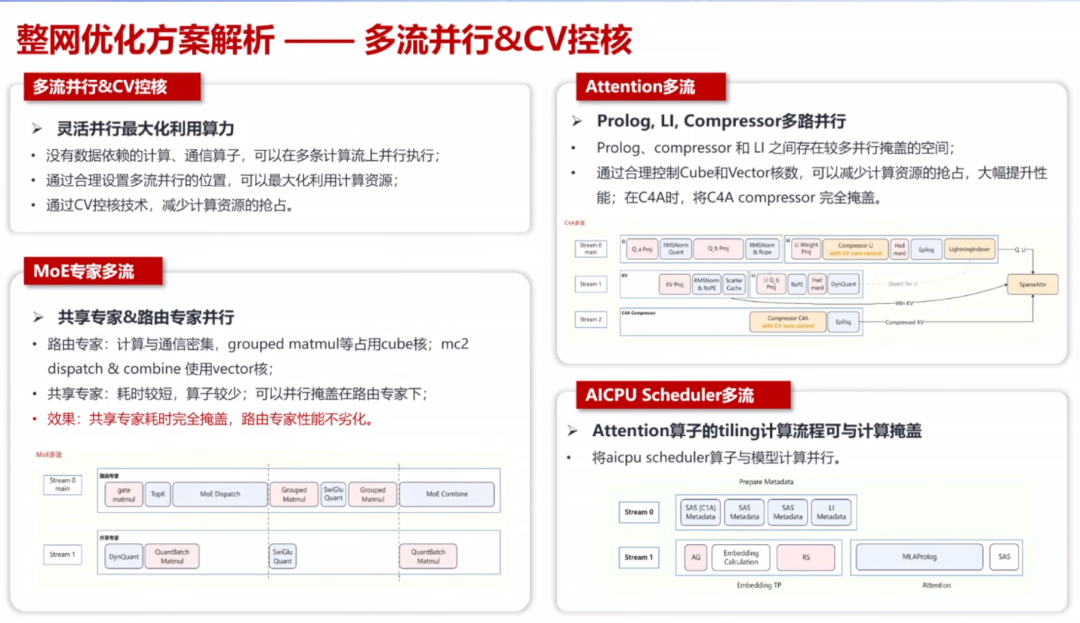
2、昇腾同步开源DeepSeek-V4复杂稀疏注意力+mHC续训实现华为昇腾通过TorchTitan-NPU插件与Autofuse自动融合技术协同,实测模型吞吐量最高达到1100 tokens/p/s,实现模型训练性能开箱即优。极简分布式并行架构: 突破传统复杂的混合并行设计,采用超节点亲和的大EP+纯FSDP的极简并行切分策略。▲并行策略
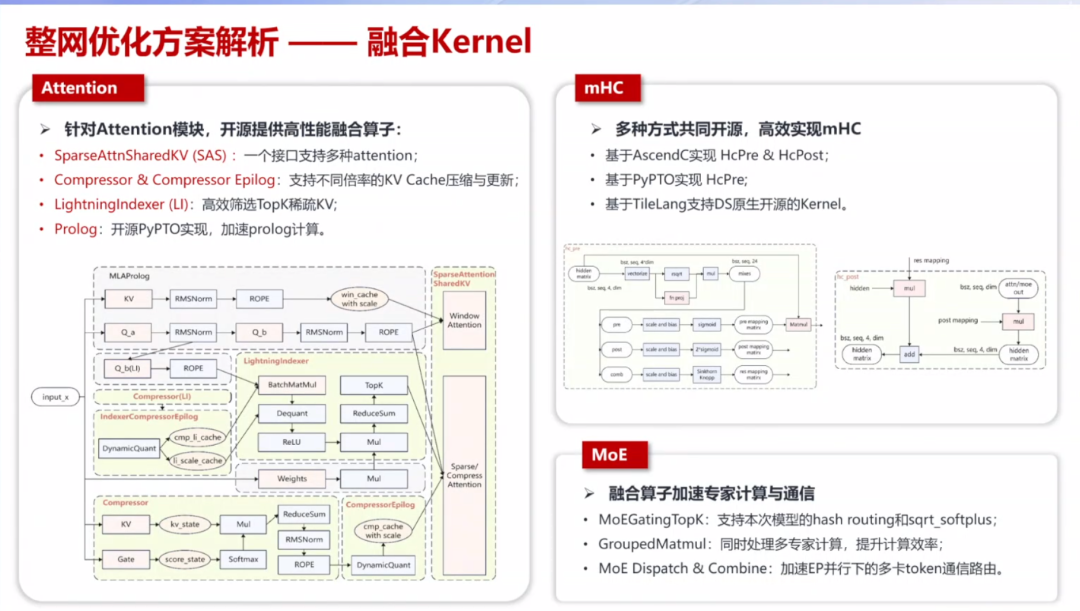
原生“入图”与自动融合:TorchTitan-NPU深度适配torch.compile机制,使能训练入图技术,依托Inductor+AutoFuse(基于Ascend C的Codegen后端)实现端到端的Vector算子自动融合,为整网带来高达31.8%的开箱即用性能收益。稀疏Attention高效融合算子: 针对稀疏注意力等复杂结构,开发SparseAttnSharedkv、LightningIndexer 等多个高效的NPU融合算子,释放芯片稀疏算力。3、推昇腾PyPTO编程范式,让大模型算子开发轻量化此外,昇腾CANN还推出PyPTO编程范式,解决自定义算子开发门槛高、周期长的痛点。该范式提供完善的Python API,使开发者能够以符合Python习惯的语法进行算子开发。
首先是高效的算子开发,PyPTO依托内置高级编译优化,可自动完成流水编排与内存管理,使开发者无需关注硬件细节而专注于计算流表达,实现DeepSeek-V4新一代模型算子开发周期可缩短至天级。
其次是高性能Kernel自动生成,针对Attention、Compressor、mHC等复杂逻辑算子,PyPTO可自动生成高度优化的Kernel,避免开发者手动处理繁琐的同步与数据搬运,缩短从算法验证到部署落地的开发周期。
▲融合Kernel
第三是PTO ISA虚拟指令集跨代兼容,PyPTO基于PTO虚拟指令集(PTO ISA),实现了对硬件新特性的“零感适配”,针对不同代际芯片统一指令接口,同一套算子代码可在不同代际芯片上的兼容实现。
其借助毕昇编译器的VF(Vector Fusion)自动融合能力,可在micro kernel级别实现更优融合。
最后是TileLang社区生态,TileLang-Ascend是TileLang针对华为昇腾平台深度优化的实现,分别对应Tilelang-Ascend的Expert和Developer开发模式,提供AscendC基础指令和PTO AS两种对接层次,为各种编程前端语言和编译器提供多层开放接口。
DeepSeek-V4模型相关实现已在TileAI开源社区正式发布,后续将持续推进性能优化与功能迭代。
DeepSeek-V4模型发布后,寒武纪、华为昇腾、海光信息、摩尔线程火速官宣适配,拉开国产AI芯片支持DeepSeek系列模型的大幕。
寒武纪基于vLLM推理框架完成对DeepSeek最新开源模型285B DeepSeek-V4-flash和1.6T DeepSeek-V4-pro适配,适配代码已开源到GitHub社区。
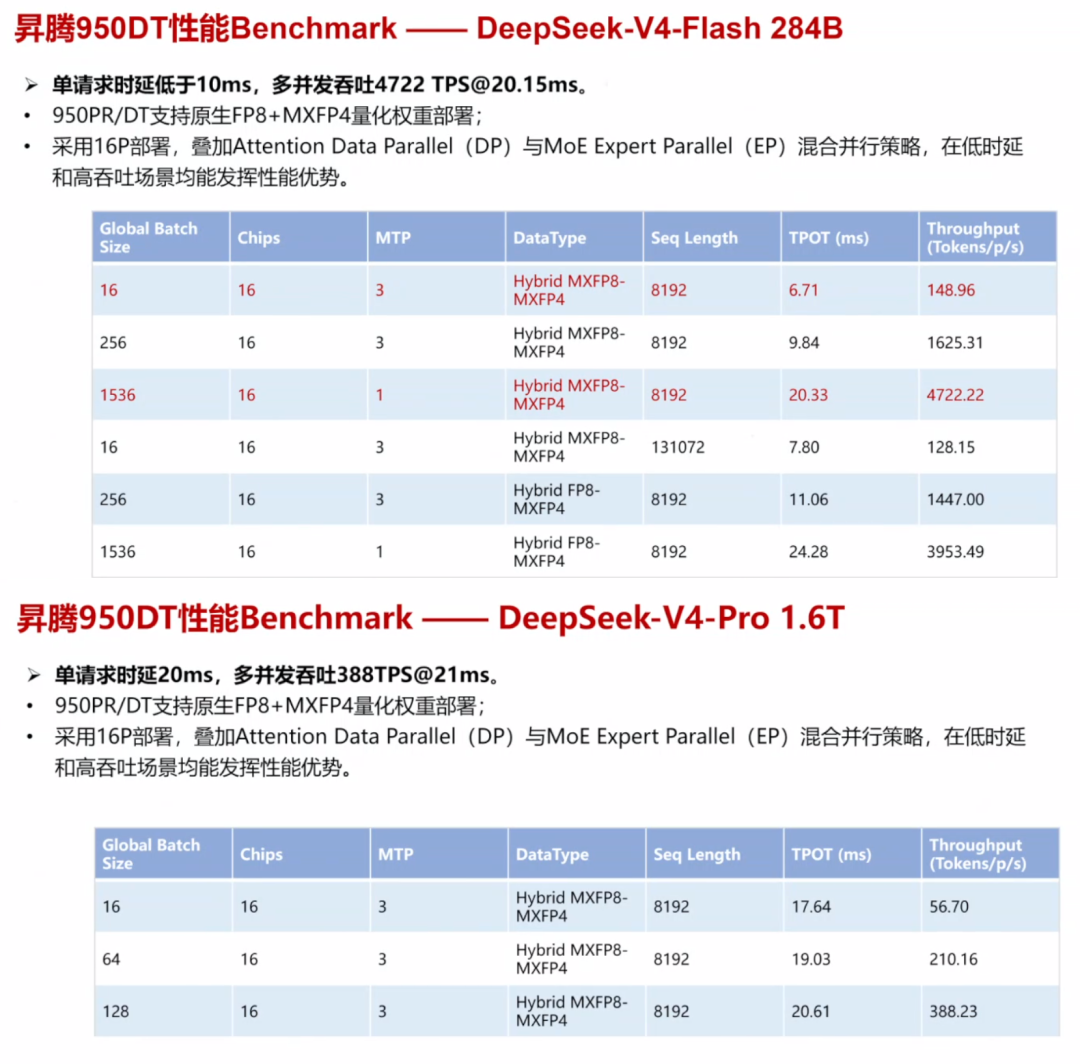
华为昇腾超节点全系列产品支持DeepSeek-V4系列模型。基于DeepSeek-V4-Pro模型,在8K输入场景,昇腾950超节点可实现TPOT约20ms时单卡Decode吞吐4700TPS。DeepSeek-V4-Flash模型,8K长序列输入场景下可实现TPOT约10ms时单卡Decode吞吐1600TPS(注:上述Benchmark数据均基于Offine推理模式采集,不包含Serving调度和框架负载均衡影响)。
基于昇腾A3 64卡超节点结合大EP模式部署,DeepSeek-V4-Flash模型,8K/1K输入输出场景,基于vLLM推理引擎可实现2000+TPS的单卡Decode吞吐。针对DeepSeek V4-Pro模型,昇腾A3正同步支持推理部署,性能持续优化中。
海光DCU同步完成对DeepSeek-V4的Day0适配,其中,DTK(异构计算平台)可为DeepSeek-V4提供完整的软件生态支撑,DAS(人工智能基础软件系统)集成超2000个算子,提高DeepSeek-V4微调与推理性能,DAP(人工智能应用平台)内置知识库引擎、智能体编排引擎等高阶模块,可将DeepSeek-V4便捷集成到主流AI平台。摩尔线程联手智源众智FlagOS社区,在旗舰级AI训推一体全功能GPU MTT S5000上,实现对新一代大模型DeepSeek-V4-Flash的Day-0极速适配,并完成全量核心算子的深度优化与部署支持。DeepSeek-V4模型首次采用“FP4+FP8”混合精度策略,当前国内主流AI芯片仍普遍以BF16为主。摩尔线程具有原生FP8支持优势,能够高效承载DeepSeek-V4的精度设计。摩尔线程与FlagOS社区正持续推进拥有1.6T旗舰模型(1.86万亿参数)的DeepSeek-V4-Pro在MTT S5000上的迁移适配工作。
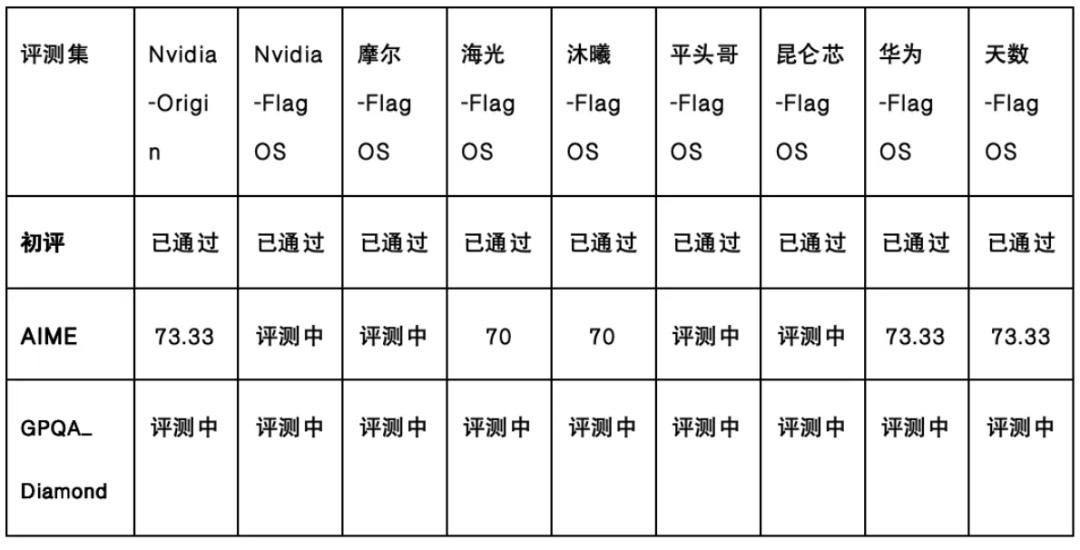
智源研究院众智FlagOS社区宣布将对DeepSeek-V4模型进行全量适配,目前其已完成DeepSeek-V4-Flash在8款以上AI芯片上的全量适配与推理部署,包括海光、沐曦、华为昇腾、摩尔线程(FP8)、昆仑芯、平头哥真武、天数、英伟达(FP8)等芯片,正在推进DeepSeek-V4-Pro模型在多个芯片的迁移适配。本次DeepSeek-V4-Flash的适配,全球最大的Triton单一算子库FlagGems实现了模型推理链路中全部算子的替代。在40个主流模型上,推理任务算子覆盖度达到90%~100%,能完整支持DeepSeek-V4-Flash的全部计算需求。这意味着彻底脱离CUDA算子依赖、无需芯片厂商逐一适配、新算子即时可用。(1)独立的并行策略:独立于已有的张量并行通信组之外,为o-group单独构建所需要的张量并行通信组,确保其他模型结构张量并行切分超过8的情况下,o-group的张量并行在8以内。(2)参数转换调整:对o_group相关的参数进行对应单独的张量并行切分处理。(3)覆盖面扩展:这一优化能够将DeepSeek-V4-Flash在单独采用张量并行策略下,把可运行芯片范围从"仅限单机80GB以上显存的个别高端卡“扩展到”多机64GB/32GB的更多主流国产芯片"。3、支持“FP4+FP8混合精度”到BF16的精度转换DeepSeek-V4模型采用FP4+FP8混合精度训练,但当前所有国内非英伟达AI芯片都未能支持FP4+FP8混合精度,只有摩尔线程原生支持了FP8,其余依然以BF16为主。FlagOS完成了从FP4到BF16的完整精度转换,将FP4量化权重转换为BF16格式;FlagOS对推理链路中的GEMM、Attention、MoE路由等关键计算节点逐一适配了BF16路径;经过标准评测集验证,BF16版本与FP4原生版本在核心能力指标上保持对齐,确保精度转换不引入业务层面的效果损失。FlagOS推出了FP8和BF16两种适配版本,让DeepSeek-V4-Flash不再是“只有最新英伟达卡才能跑”的模型,而是真正可以部署在FP8及BF16生态的主流国产芯片上。智源研究院公布的数据显示,经GPQA_Diamond、AIME等评测集验证,FlagOS适配后的DeepSeek-V4-Flash,在语言理解、复杂推理、代码生成、数学计算等核心能力上,可与CUDA原生版本对齐。https://github.com/flagos-ai/DeepSeek-V4-FlagOS
万众期待的“国产大模型之光”DeepSeek-V4正式亮相后,多款国产高端芯片率先完成适配与深度兼容。这也意味着,国产顶级大模型与本土高端算力矩阵实现了全栈深度绑定与协同。此次华为等国产芯片厂商与DeepSeek联合,在技术协同迭代、规模化产业落地、本土生态共建三大维度,都具有里程碑意义。此举有望打破英伟达长期主导的垄断生态,推动国内AI国产软硬一体、自主可控产业链发展。
 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库