扒完DeepSeek-V4技术报告,我看到了异构内存的含金量
发布时间:2026-04-25来源:芯东西

DeepSeek-V4以算法革新打破内存墙,倒逼硬件升级。芯东西4月25日报道,本周五,“国产大模型顶流”DeepSeek-V4开源,其产业影响力火速蔓延:DeepSeek-V4-Pro登顶Hugging Face开源模型榜,A股和港股的AI算力板块全线飘红,国产AI芯片厂家、云巨头、服务器厂家开启密集适配、接入……DeepSeek-V4两款模型DeepSeek-V4-Pro与DeepSeek-V4-Flash,采用MoE架构,总参数规模达到1.6T(激活49B)与284B(激活13B),均支持最长百万Token上下文。昨日,DeepSeek还亮出核心技术底牌,正式发布新模型技术报告,全面拆解新一代架构升级内核、深度优化预训练与后训练全流程体系,公开了全套核心算法与迭代秘籍。扒完这份报告不难发现,DeepSeek-V4以CSA、HCA混合注意力、异构KV Cache、FP4量化感知训练等系统性创新,从算法根源打破“内存墙”,让百万Token长上下文推理真正走向低成本、可规模化的工程落地。算法层面的突破背后,DeepSeek-V4更是用极致压缩架构,反向定义了下一代AI芯片必须走的硬件升级方向:通过差异化存算方案,适配不同数据在带宽、延迟、存储容量上的多元需求。
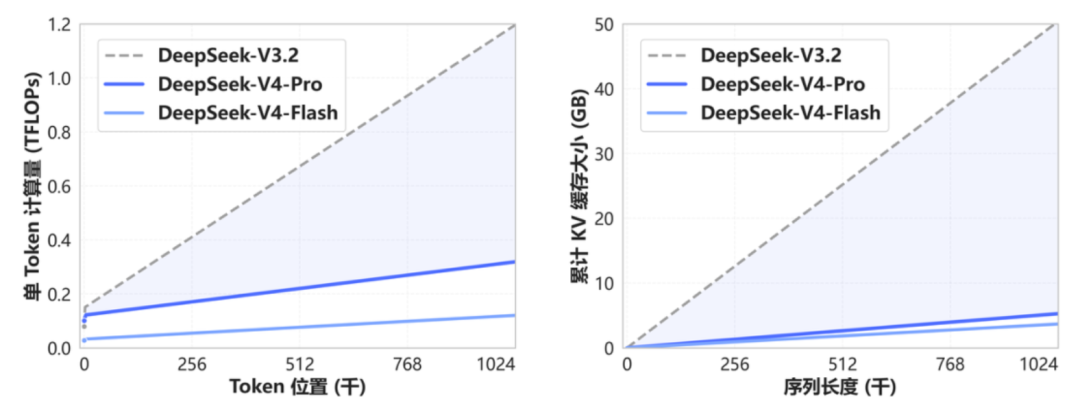
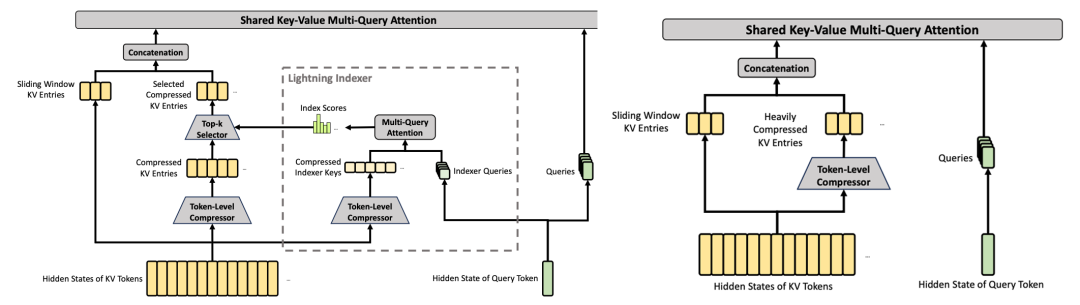
DeepSeek-V4全系标配百万Token超长上下文,其上下文长度达到上一代DeepSeek-V3.2模型的近8倍。首先,DeepSeek-V4采用了混合注意力架构。DeepSeek结合了CSA(压缩稀疏注意力)和HCA(高度压缩注意力),使DeepSeek-V4-Pro在100万Token的上下文设置下,相比DeepSeek-V3.2仅需27%的单Token推理浮点运算量,KV Cache占用量降至前代模型的10%。更轻量的DeepSeek-V4-Flash将效率推至更高水平,其单Token浮点运算量仅为DeepSeek-V3.2的10%,KV Cache占用容量更是低至后者的7%。这一架构升级的核心思路是,CSA先将KV Cache沿序列维度进行压缩,再在压缩后的条目上执行稀疏注意力,仅关注最相关的压缩块。HCA则采用更大压缩率,将每128个Token的KV信息融合为一个条目,但保持稠密注意力,两种机制交替,底层使用CSA保持精细的局部依赖,高层使用HCA大幅压缩远端上下文。▲CSA核心架构(左)、HCA核心架构(右)
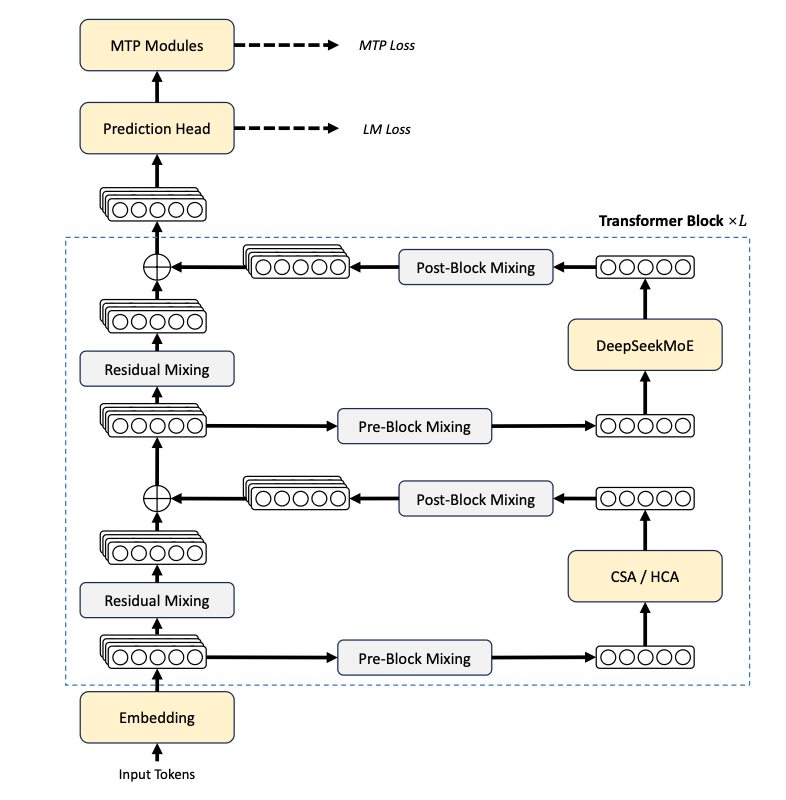
其次,DeepSeek引入了mHC(流形约束超连接)以及Muon优化器,mHC结构能在保留模型表征能力的同时提升多层网络间信号传播的稳定性;Muon优化器可帮助实现更快的收敛速度和更高的训练稳定性。最后是升级版DeepSeekMoE,DeepSeek-V4保持每层384个路由专家+1个共享专家,每Token激活6个的DeepSeekMoE框架,并将初始层的密集FFN替换为Hash路由的MoE层,提升稀疏激活效率。此外,DeepSeek-V4还设计了异构KV Cache与磁盘缓存机制:压缩后的CSA/HCA条目存盘,滑动窗口SWA未压缩KV支持全缓存、周期检查点、零缓存三级策略,灵活平衡存储与计算,实现共享前缀请求零重复预填充。▲DeepSeek-V4整体架构
DeepSeek-V4的技术革新背后,是万亿参数模型普遍面临的推理效率困局。算力是最近几年大模型产业的焦点话题,从算力供给、GPU紧缺程度,再到超算集群的规模化扩张,始终是行业热议焦点。但伴随大模型进入商业落地、实际部署的关键期,产业界愈发意识到,即便算力问题得到阶段性缓解,系统层面的瓶颈并未消失,而是悄然转移到了另一个核心环节——内存。伴随大模型参数规模卷上万亿、上下文长度达到百万,AI推理产生的中间过程数据体量急剧膨胀,对内存承载上限与读写访问效率形成严苛考验。以英伟达H200为例,其配备141GB HBM3E显存和4.8TB/s传输带宽,但算力与内存带宽仍存在明显差距。AI解码时数据搬运速度跟不上运算节奏,大量计算单元空转闲置,既浪费硬件性能也加剧高功耗问题。当前场景下,GPU算力并未充分闲置,但显存装不下、数据传太慢拖了后腿,会引发功耗飙升、整机部署成本大幅攀升等一系列连锁问题。在这样的背景下,AI芯片的竞争逻辑正在重构:不单纯比拼“运算速度”,而是延伸至内存容量、数据吞吐、能耗控制的综合较量。此前不少厂商依靠堆砌高规格内存,以硬件冗余掩盖架构短板保障推理运行,代价是功耗与硬件成本持续走高。但这种治标不治本的方案,已无法适配长期产业发展。因此,当下AI芯片厂商正面临双重挑战:内存墙瓶颈持续加剧,且DeepSeek-V4算法迭代提速,倒逼硬件同步进化。正如前文所述,DeepSeek-V4通过几项关键架构创新攻克“内存墙”难题,真正实现了百万Token长文本推理的规模化落地。但矛盾的是,当前多数AI芯片仍采用同质化存算设计,难以适配新一代大模型的分层运行逻辑与异构数据特征。这也意味着,这样的AI芯片会抵消模型算法升级换来的压缩优势、成本优势与性能增益,成为制约大模型推理效能释放的核心瓶颈。具体来看,DeepSeek-V4推理存在鲜明的数据异构特征:KV Cache、门控路由、注意力与共享专家参数属于高频低延迟的热数据;384个全量路由专家、压缩远端KV、磁盘级冷存KV为低频低时效的冷数据,仅少量专家参与激活计算。并且模型本身已通过量化压缩、分级缓存、冷热分层存储完成精细化设计,天然适配异构内存架构,亟需硬件以差异化存算方案匹配不同数据的带宽、延迟与容量需求。
想要破解这一困局,从系统层面着手的核心思路是:让不同类型的内存各司其职。深耕3D内存领域多年的微珩科技,其底层研发逻辑正与此思路一脉相承。具体来看,针对DeepSeek-V4的异构数据访问特性,微珩扶光芯片摒弃单一内存堆叠设计,融合3D DRAM与2D DRAM,打造了定制化异构内存子系统:该架构的创新性在于,以3D堆叠DRAM替代端侧LPU传统片上SRAM,结合三维堆叠、混合键合封装,缩短数据传输路径,兼顾SRAM低时延与DRAM高密度、低成本优势。基于此,其能解决SRAM容量小、面积与成本高的局限,同等芯片面积存储大幅扩容,适配大参数模型、长上下文推理;避开HBM供应链与高带宽依赖问题。再加上其存算就近互联,权重常驻存储、访存更稳定,能降低功耗与量产成本。其中,3D DRAM依托TSV硅通孔垂直堆叠架构,大幅缩短数据传输路径,兼具低访问延迟、低比特功耗与超高带宽,适配高频热点数据读写;2D DRAM采用成熟平面布线方案,散热表现优异、容量可灵活拓展,且成本可控、供给稳定,适配低频冷数据存储。两类内存形成高速低耗、大容量低成本互补组合。此外,微珩科技自研的数据映射策略,还能适配DeepSeek-V4的分层调度逻辑。对带宽敏感的核心热数据,微珩将KV Cache、MoE门控网络、共享专家、注意力参数,以及已激活路由专家高速缓存,统一挂载至3D DRAM。门控网络需实时完成384个路由专家权重运算,支撑单Token动态调度;压缩后的KV Cache解码阶段仍需逐轮高频调取;共享专家与注意力参数为推理核心高频组件,叠加激活专家缓存的时间局部性访问特征,依托3D DRAM高带宽、低延迟优势,保障核心链路高速读写与高效计算。而带宽需求较低的冷数据,则统一存放于2D DRAM,包含FP4量化全量路由专家、HCA压缩远端KV条目及磁盘下沉冷缓存。模型单Token仅激活6位专家,其余全量参数长期低频驻存,2D DRAM大容量、低成本的特性,可承载384个全量专家参数与低频远端数据存储,基础带宽足以匹配访问需求。这样通过冷热数据分层异构部署的策略,能在控制硬件成本的前提下进一步释放推理性能,以压低万亿参数大模型的落地部署成本与落地门槛。
DeepSeek-V4的问世,不仅是架构层面的创新,更是大模型在端侧落地部署的关键里程碑。桌面一体机、边缘服务器等端侧设备在部署大模型时,往往会受限于高速内存成本高昂且容量有限。根源在于传统架构采用单一内存方案,对所有模型参数进行同质化存储,这样一来,全部署于低速内存会限制推理性能;全部署于高速内存会面临容量不足的问题,都会导致大模型难以在端侧落地。而DeepSeek-V4来自算法层面的核心升级,叠加微珩扶光芯片的2D+3D异构架构,恰好形成一套完整可行的破局方案。在算法端,DeepSeek通过CSA、HCA从算法层压缩计算与显存,搭配异构KV Cache做分级存储、FP4量化压缩参数,三者协同使得仅高频访问的关键参数驻留高速内存,其余海量资源全部迁移至低速内存,为端侧部署扫清算力瓶颈。在硬件端,微珩扶光芯片的2D+3D异构内存架构具有天然优势,对应DeepSeek-V4的分层策略,2D DRAM承接海量路由专家和冷数据,降低硬件成本;3D DRAM保障KV Cache、门控网络等核心数据高速流转,实现推理效率提升。无需堆砌昂贵的HBM,端侧设备即可运行万亿参数级大模型。长期来看,这套算法与硬件一体化的解决方案或能打破超算中心对高阶AI能力的垄断,推动AI算力从高成本云端,大规模下沉至消费电子、智能硬件、边缘终端等全域设备,真正落地端侧普惠、算力平权的产业趋势。微珩科技在3D内存方案的技术革新、商业化方面已经有不少成果。其芯片团队于2021年量产了首款3D内存方案计算芯片,是国内首批开展相关技术方案设计与量产的企业之一,近年来已先后量产两代芯片,累计实现营收超10亿元。身处本轮技术范式迭代的关键周期,微珩科技已成为端侧AI产业化落地的核心推动者。
当大模型竞争从算法参数比拼迈入软硬协同落地的全新周期,单一的架构优化或是硬件堆料,都已无法支撑行业长期发展。可以预见,未来AI产业的核心竞争力,将可能不再局限于云端超算的极限算力,而是落脚于存算异构、分层调度、成本可控的全域部署能力。端侧算力下沉、算力平权普及或将成为不可逆的产业趋势。当下,DeepSeek-V4的算法革新,正倒逼内存架构走向精细化、差异化的分层设计。以微珩扶光芯片为代表的异构内存方案,印证了冷热数据分流、高低速内存协同是突破端侧瓶颈的有效路径。这也意味着,从云端集中式算力,到云边端分布式协同,AI产业正迎来一次底层架构的变革。
转载说明:本文系转载内容,版权归原作者及原出处所有。转载目的在于传递更多行业信息,文章观点仅代表原作者本人,与本平台立场无关。若涉及作品版权问题,请原作者或相关权利人及时与本平台联系,我们将在第一时间核实后移除相关内容。
 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库