五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库8家国产芯无缝衔接DeepSeek-V4,中国AI算力生态的拐点来了!
4月24日,DeepSeek-V4预览版正式发布。DeepSeek自V3起便以高频迭代著称,V4的到来只是节奏延续。
但真正引发行业震动的是:华为昇腾、寒武纪、海光信息、摩尔线程、沐曦股份、百度昆仑芯、阿里平头哥、天数智芯等八家国产AI芯片厂商,在模型发布的同一天,集体完成了全链路适配与性能优化。
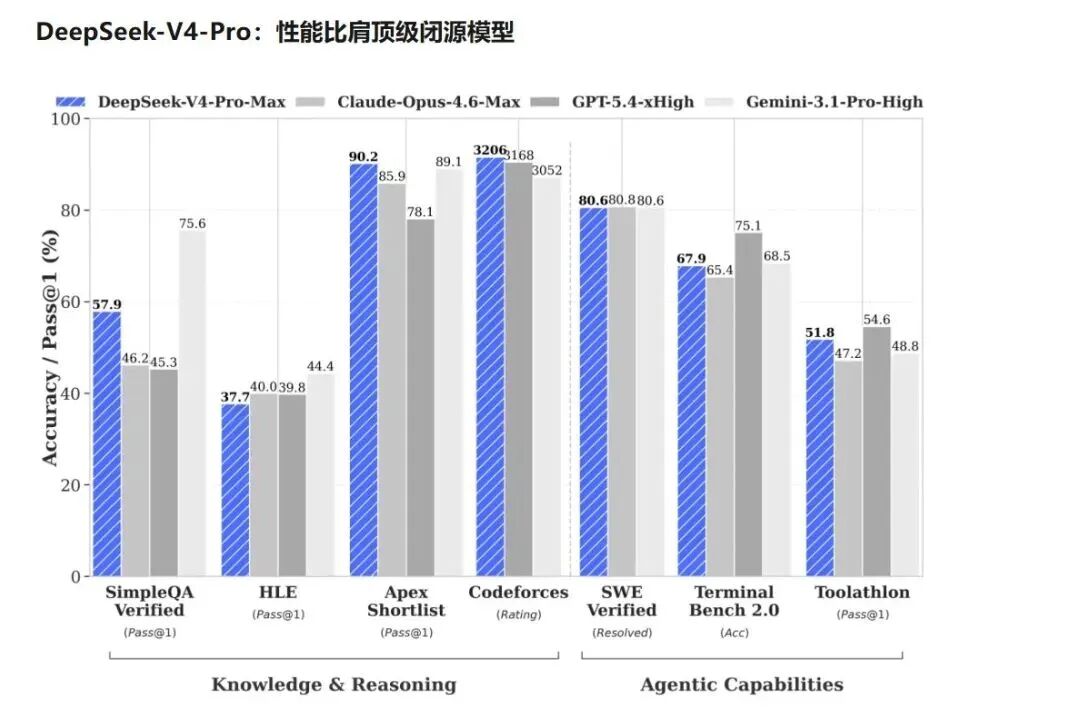
(图源:DeepSeek)

Day 0 意味着什么
Day 0适配,是指在大模型正式发布当天,算力侧已完成全链路兼容验证、性能调优与稳定性测试,开发者开箱即用,无需等待适配窗口。这个概念之所以稀缺,是因为它代表的不是某一个技术环节的突破,而是整个软硬件协同体系的成熟度验证,拗口芯片微架构、固件层、驱动、编译器、推理框架、算子优化等,每一层都必须提前完成对接,任何一个环节存在短板,Day 0都不可能实现。
放眼全球,真正掌握这一能力的,唯有英伟达。凭借CUDA生态和cuDNN、TensorRT等完善的底层库,英伟达与大模型发布方之间形成了高度默契的协同节奏。模型上线之日,也是GPU最优路径打通之时。对开发者而言,这意味着零摩擦的部署体验,是英伟达生态最具粘性的护城河之一。
DeepSeek-V4发布的这一天,这一局面被打破了。

八家厂商Day 0适配
在这批Day 0适配名单中,华为昇腾的覆盖范围广、技术纵深较深。昇腾A2、A3、950全系列同步完成适配,Pro与Flash两个版本均获支持。技术路径上,昇腾通过融合kernel与多流并行技术针对性优化Attention计算的访存开销,结合多种量化算法实现高吞吐、低时延的推理部署。昇腾超节点同步释出了训练参考实现,适配不只覆盖推理,还延伸到了模型微调环节,覆盖了从部署到训练的全流程。

寒武纪的适配策略则呈现出另一种姿态:基于vLLM推理框架完成适配后,寒武纪将适配代码开源至GitHub社区,供开发者自由取用。
海光信息的打法强调“闭环”。海光DCU完成Day 0适配的同时,对模型进行了深度调优,形成“模型发布—芯片适配—产业落地”的完整链条。海光强调了“即取即用的部署方案”,面向的是有实际落地需求的行业用户,而非技术验证场景。
摩尔线程基于旗舰级AI训推一体智算卡MTT S5000与FlagOS全栈软件体系完成推理适配。
沐曦股份采取了双线并进的适配策略:一方面携手智源研究院的FlagOS开源软件栈,实现了在沐曦GPU上的全量适配与推理部署;另一方面联合上海人工智能实验室的KernelSwift智能算子迁移系统。
昆仑芯已在发布当天完成了模型兼容性验证与部署链路打通,开发者可以在昆仑芯平台上开箱使用DeepSeek-V4-Flash模型。
平头哥凭借FlagGems全算子替代、独立张量并行策略以及FP4到BF16精度路径转换等三项关键技术突破,真武AI芯片在模型发布当日即完成了对DeepSeek-V4-Flash的推理部署,实现了国产芯片与顶尖开源大模型的同步适配。
天数智芯AI芯片已完成DeepSeek-V4-Flash模型的全量算子适配与推理部署验证。
这八家厂商构成了我国AI芯片产业的一次集体亮相。从通用算力到专用推理,从自主研发到开源生态,这张适配图谱的完整性,本身就是一种有力的行业表达。
值得注意的是,这一批Day 0适配的实现,背后有一个关键平台——北京智源人工智能研究院研发的FlagOS开源软件栈。正是FlagOS提前完成了对DeepSeek-V4的算子兼容、张量并行策略和混合精度转换,才使得这些国产芯片能够在同一天完成全量适配与推理部署。

DeepSeek做对了什么
如果只看芯片厂商的行动,很容易忽略一个关键变量:为什么是DeepSeek,而不是其他模型公司?
答案藏在DeepSeek的战略选择里。
从V3开始,DeepSeek就选择了主动适配多家国产芯片,而非让各家厂商被动跟进。这种“中立适配”的姿态,在商业逻辑上并不显而易见,它在模型发布前便与各芯片厂商建立协同机制,开放底层接口,提供性能基准,让芯片厂商有足够的时间窗口完成准备工作。
这不是单方面的技术服务,而是模型公司与芯片厂商之间的双向选择。DeepSeek需要算力多元化来对冲单点风险,芯片厂商需要DeepSeek的高频迭代来吸引开发者。两者在战略层面形成了相互依存的关系。
对于芯片厂商而言,DeepSeek的开源属性提供了标准化的基准。以往各家芯片厂商适配不同的开源模型,工作量大且难以复用。DeepSeek的统一架构让适配经验可以在不同场景中迁移,降低了每代模型迭代的软件工程成本。换句话说,DeepSeek既是适配目标,也是适配标准。
这也是Day 0能够批量发生的根本原因:不是某一家芯片厂商突然变强了,而是模型层给了整个产业一个可以共同站立的台阶。

真正的竞争才刚开始
Day 0是起点,不是终点。
适配完成意味着“能用”,但“好用”取决于后续的性能优化深度、工具链丰富度与开发者社区活跃度。英伟达的护城河从来不只是硬件性能,而是CUDA生态积累下来的数十年工程经验与开发者习惯。
从已披露的技术路径来看,各家芯片厂商正在形成差异化的竞争方向:昇腾强调高吞吐与低时延的极致性能,寒武纪走开源社区共建的开放路线,海光侧重软硬件深度协同的端到端体验,摩尔线程押注全栈自主的软件栈。这种分化说明,Day 0之后,芯片厂商之间的竞争正在从硬件指标的比拼,转向软件生态完整度的较量。
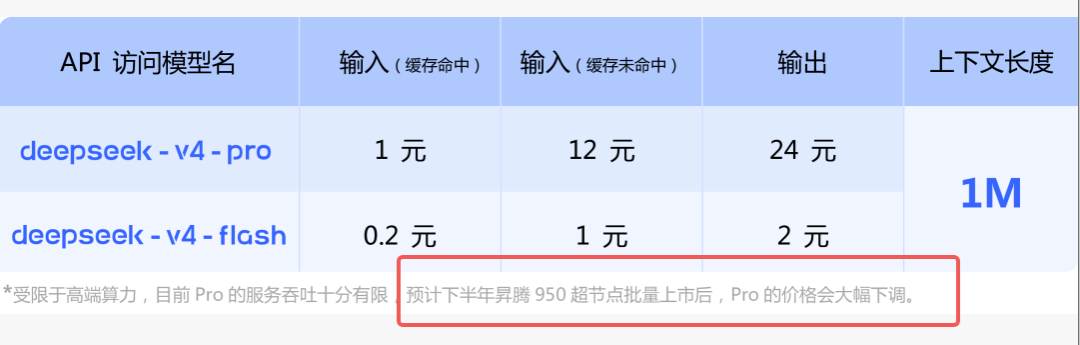
此外,如果DeepSeek保持高频迭代,芯片厂商能否持续跟进?Day 0代表着提前布局,也是持续的工程投入。这场比拼,更像是一场旷日持久的马拉松。
但无论如何,4月24日这一天,已经在国产AI芯片的发展史上留下了一个注脚。这不是某一家厂商的突破,也不是一次偶发的协同,这是中国AI芯片产业链第一次在发布端实现如此规模的共振。
- END -

推荐关注