五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库十张图拆解存储全球产业链(解读版)
近日笔者看到一篇行业优质图文作品,已主动联系原作者并征得授权,特此转载分享。
原作仅以图片形式呈现,无文字表述,笔者仅结合自身行业认知,尝试解读作者创作立意与背后产业逻辑。若理解有偏颇、解读有不妥之处,恳请各位业界同仁与读者不吝批评指正。
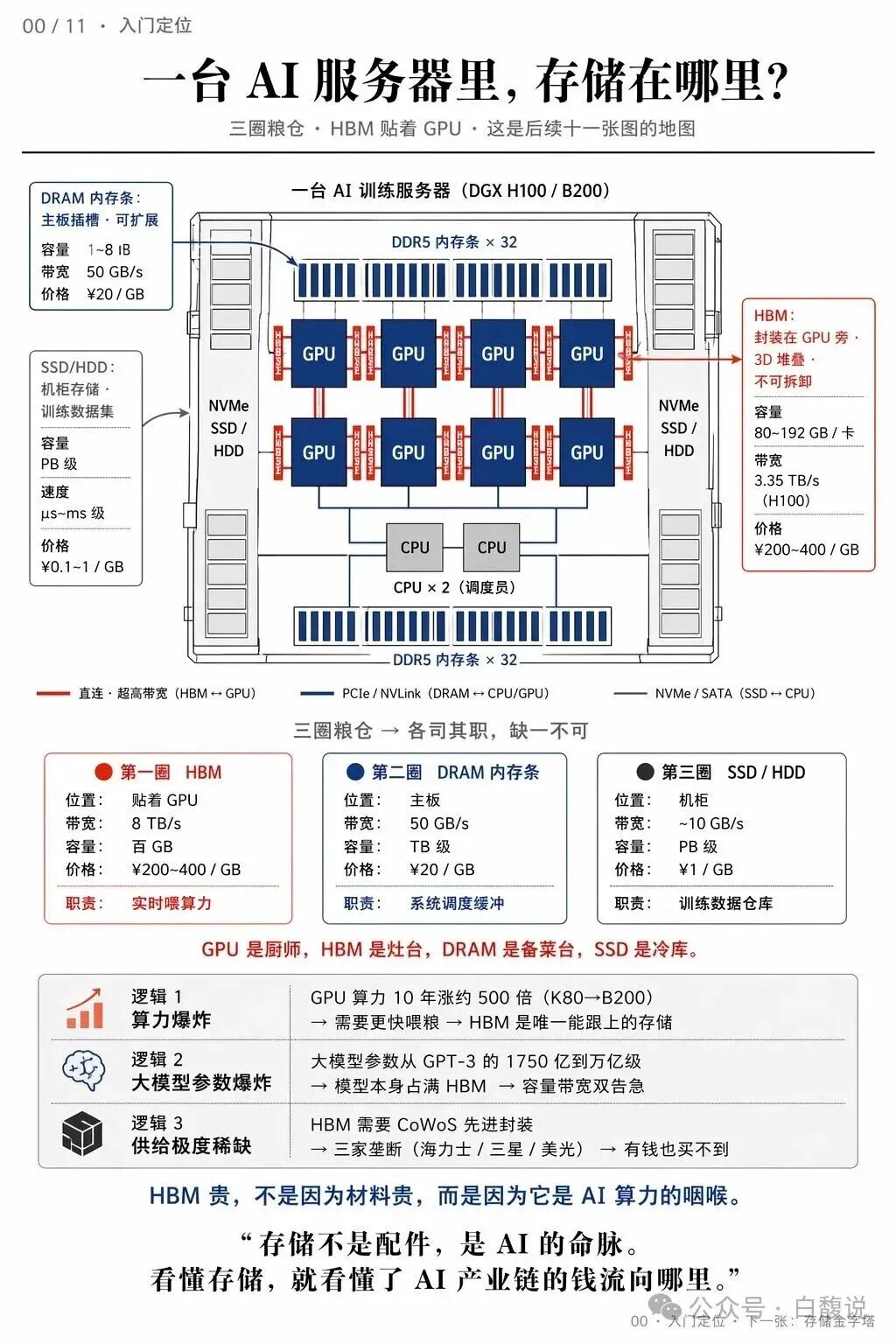
AI服务器的存储并非单一设备,而是分为“三圈粮仓”:HBM紧贴GPU,负责实时喂算力;DRAM内存条位于主板,承担系统调度缓冲;SSD/HDD在机柜中,存放PB级训练数据。三者的带宽、容量、价格差异巨大——HBM带宽可达TB/s级,但容量仅百GB;SSD容量大但速度慢。GPU算力十年涨500倍,HBM是唯一能跟上的存储,成为AI算力的“咽喉”。
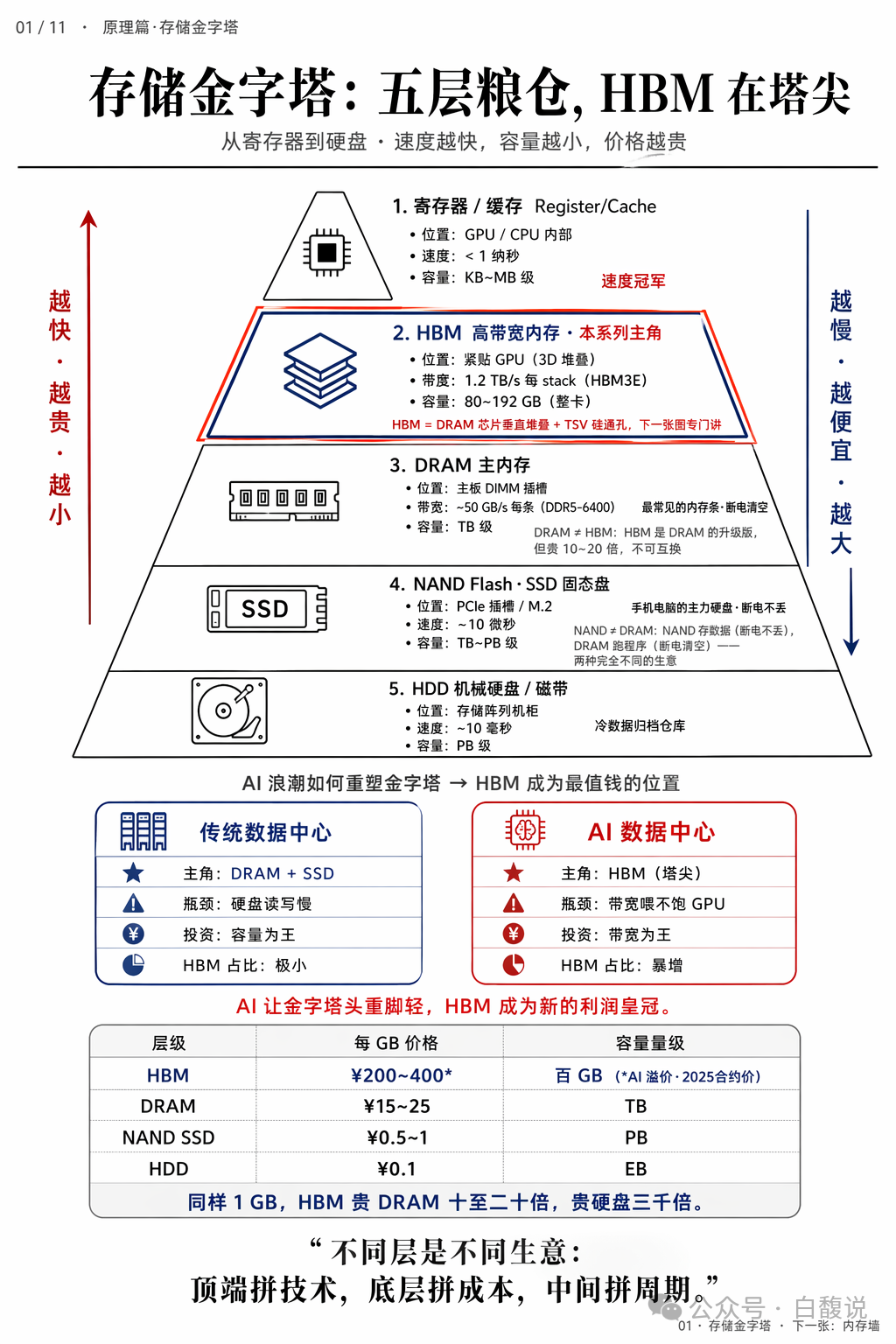
从寄存器到硬盘,存储呈现“速度越快、容量越小、价格越贵”的金字塔结构。HBM位于金字塔第二层,仅次于片内缓存,带宽远高于普通DRAM,但价格贵10~20倍。AI让金字塔“头重脚轻”:传统数据中心以DRAM/SSD为主,AI数据中心则以HBM为核心,投资逻辑从“容量为王”转向“带宽为王”。
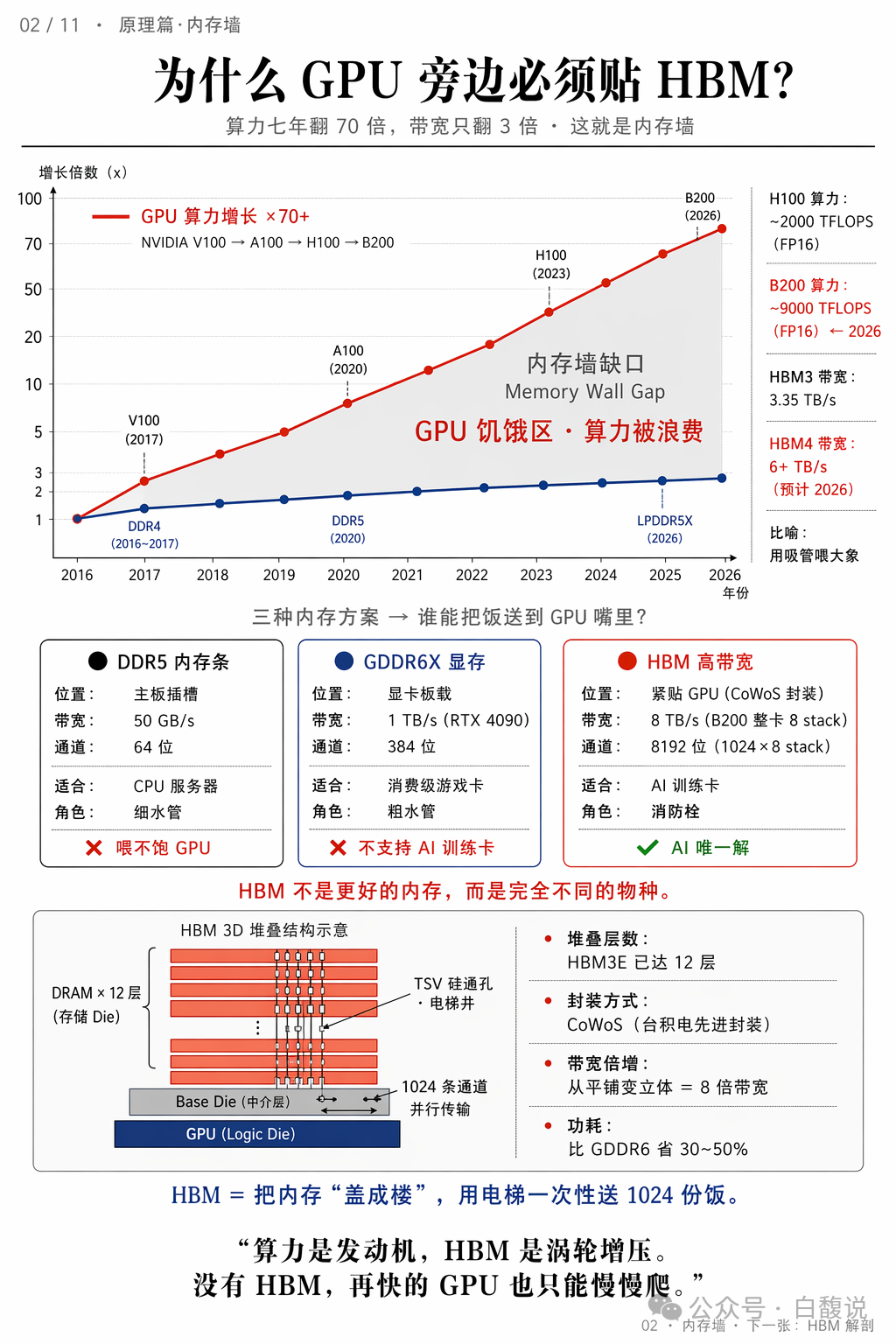
过去七年GPU算力翻了70倍,而带宽仅增长3倍,形成“内存墙”。DDR5带宽仅50GB/s,GDDR6X约1TB/s,而HBM可达8TB/s(如B200),通道宽度达8192位。HBM不是普通内存的升级,而是通过3D堆叠+TSV硅通孔,把内存“盖成楼”,用“电梯”一次性送1024份数据,是AI训练卡的唯一解。
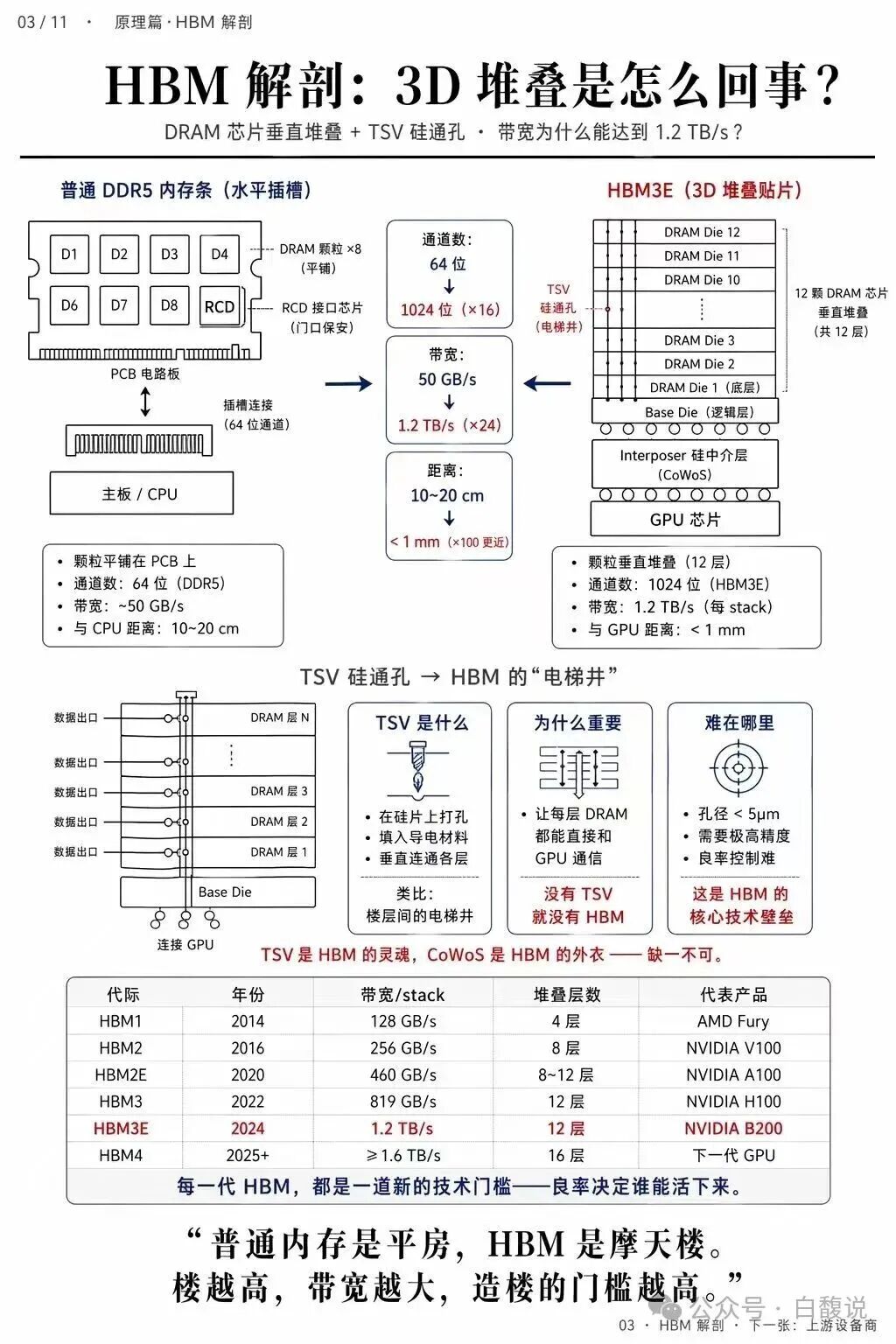
HBM将DRAM芯片垂直堆叠12层,通过TSV(硅通孔)实现层间通信,带宽达1.2TB/s,而普通DDR5仅50GB/s。TSV孔径小于5微米,是HBM的灵魂技术。HBM距离GPU小于1mm,而DDR5距离CPU达10~20cm——距离决定带宽。每一代HBM(1→3E→4)堆叠层数和带宽翻倍,良率决定谁能活下来。
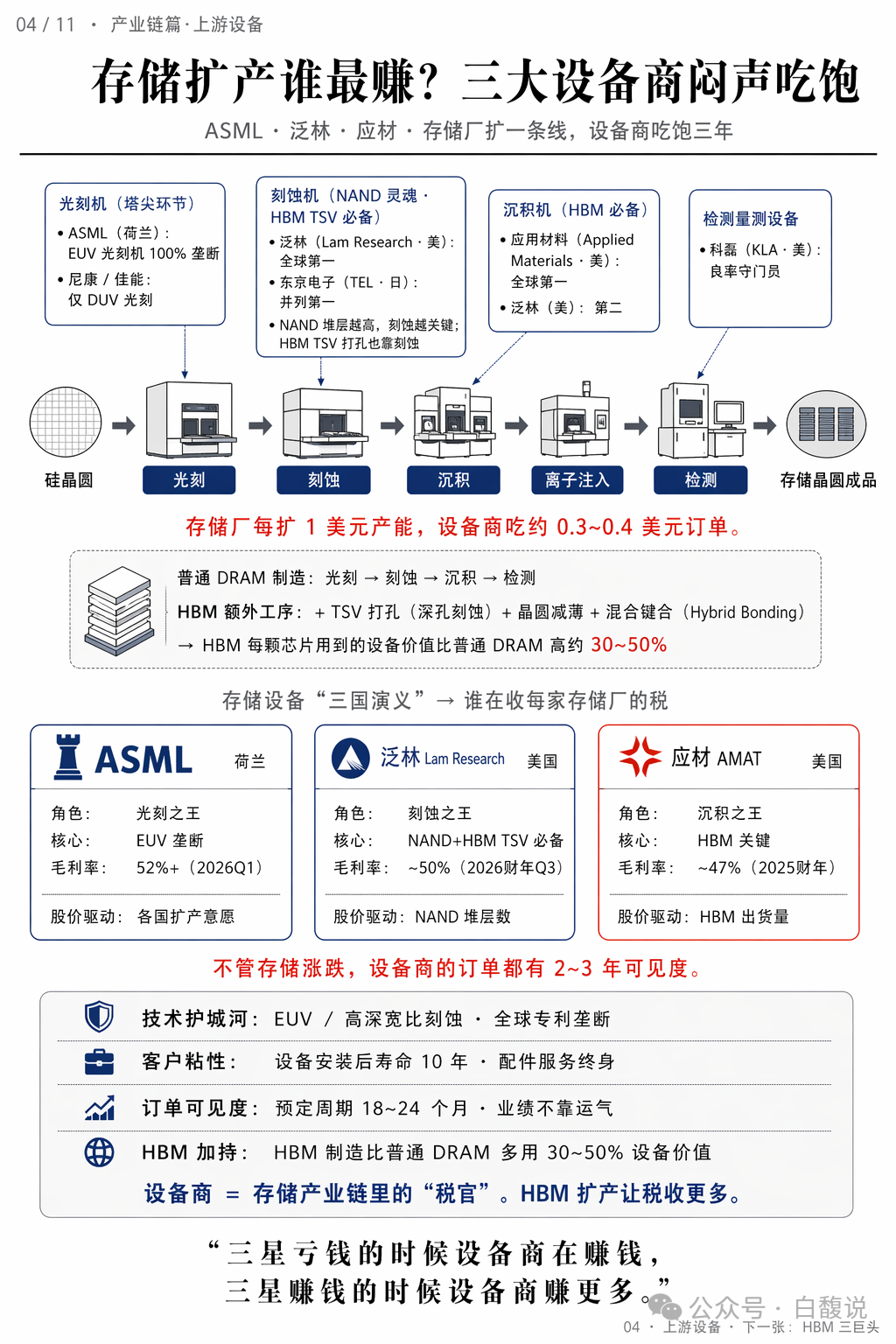
存储厂每扩1美元产能,设备商吃0.3~0.4美元。ASML垄断EUV光刻机(毛利率52%+);泛林主导刻蚀机(HBM TSV打孔必备);应用材料领跑沉积设备。HBM制造比普通DRAM多用30~50%设备价值。设备商是存储产业链里的“税官”,无论价格涨跌,订单都有2~3年可见度。
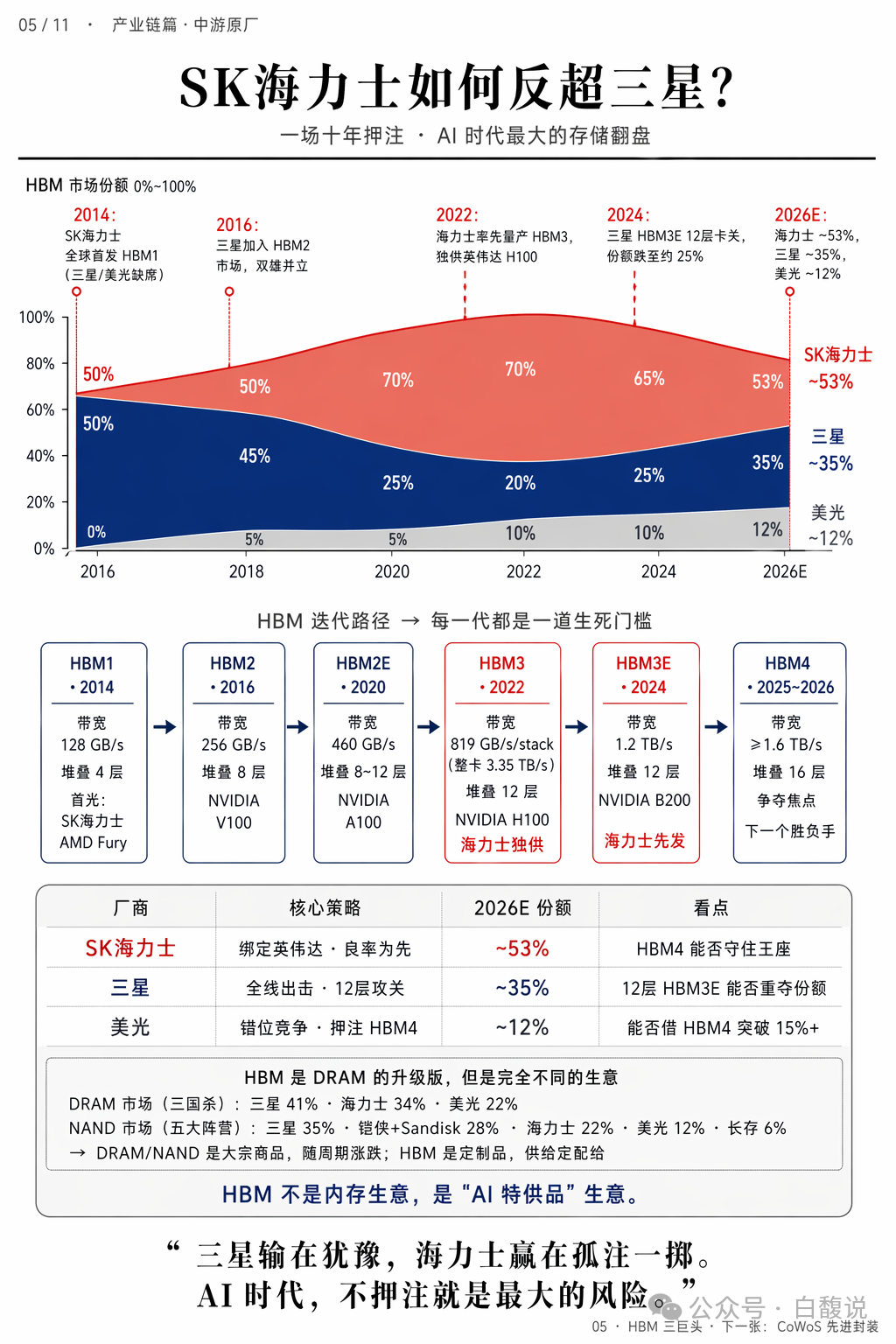
海力士从2014年首发HBM1,到2022年独供英伟达H100的HBM3,再到2024年HBM3E先发,市场份额从5%飙升至2026年预计53%。三星因HBM3E 12层卡关,份额跌至约35%。HBM不是大宗商品,而是定制品,供给定配给。海力士赢在“孤注一掷”绑定英伟达,三星输在犹豫。

HBM造好了还不够,CoWoS先进封装才是出货的真正瓶颈。台积电通过硅中介层(Silicon Interposer)将GPU和HBM连接在同一块硅片上,线宽<1μm,带宽提升数倍。CoWoS产能极度受限,扩产周期18~24个月,2026年仍供不应求。买HBM等于买台积电的CoWoS产能——两个瓶颈,缺一不可。

长鑫存储DRAM全球份额约3%(目标2026年8%),长江存储NAND份额约6%(目标12%),澜起科技为DDR5接口芯片全球三强之一。但中国HBM量产能力为0。DRAM是HBM的基础,国产替代从配套先行(接口芯片、模组)到颗粒突围,还需攻克EUV禁运、专利壁垒、TSV+CoWoS工艺三大挑战。
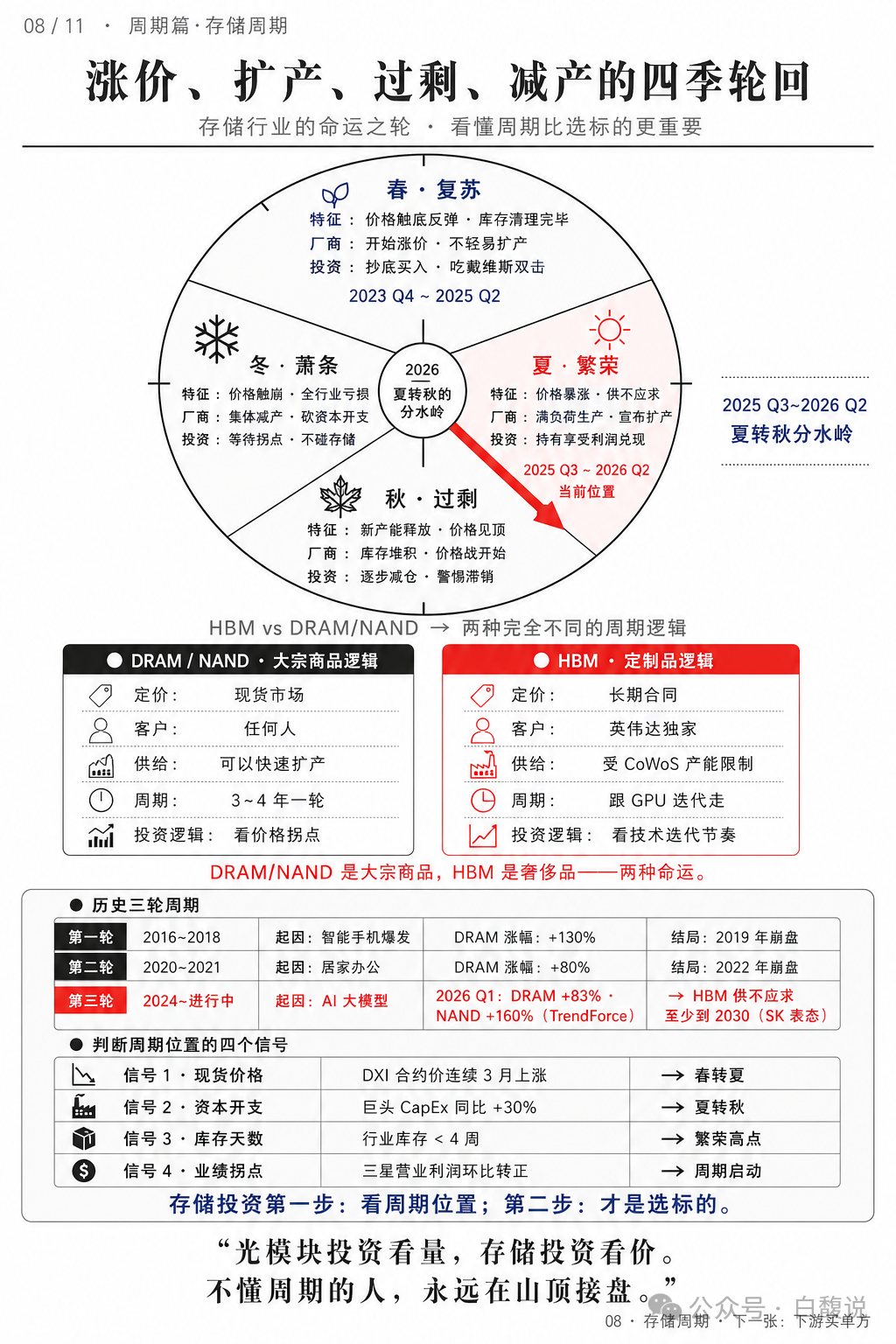
DRAM/NAND是大宗商品,每3~4年一轮周期;HBM是定制品,跟随GPU迭代,受CoWoS产能限制,不存在传统周期。当前(2026Q2)处于“夏转秋”分水岭,价格见顶、新产能释放。投资存储第一步是看周期位置:春复苏买入,夏繁荣持有,秋过剩减仓,冬萧条等待。

利润金字塔中,HBM原厂(海力士/三星/美光)毛利60%+,设备商毛利45~55%,DRAM/NAND颗粒厂毛利20~35%,模组厂仅5~20%。英伟达占全球HBM采购约50%,一颗B200含192GB HBM3E,等于6条32GB DDR5内存条。HBM是供给定配给——海力士说了算,有钱也买不到。
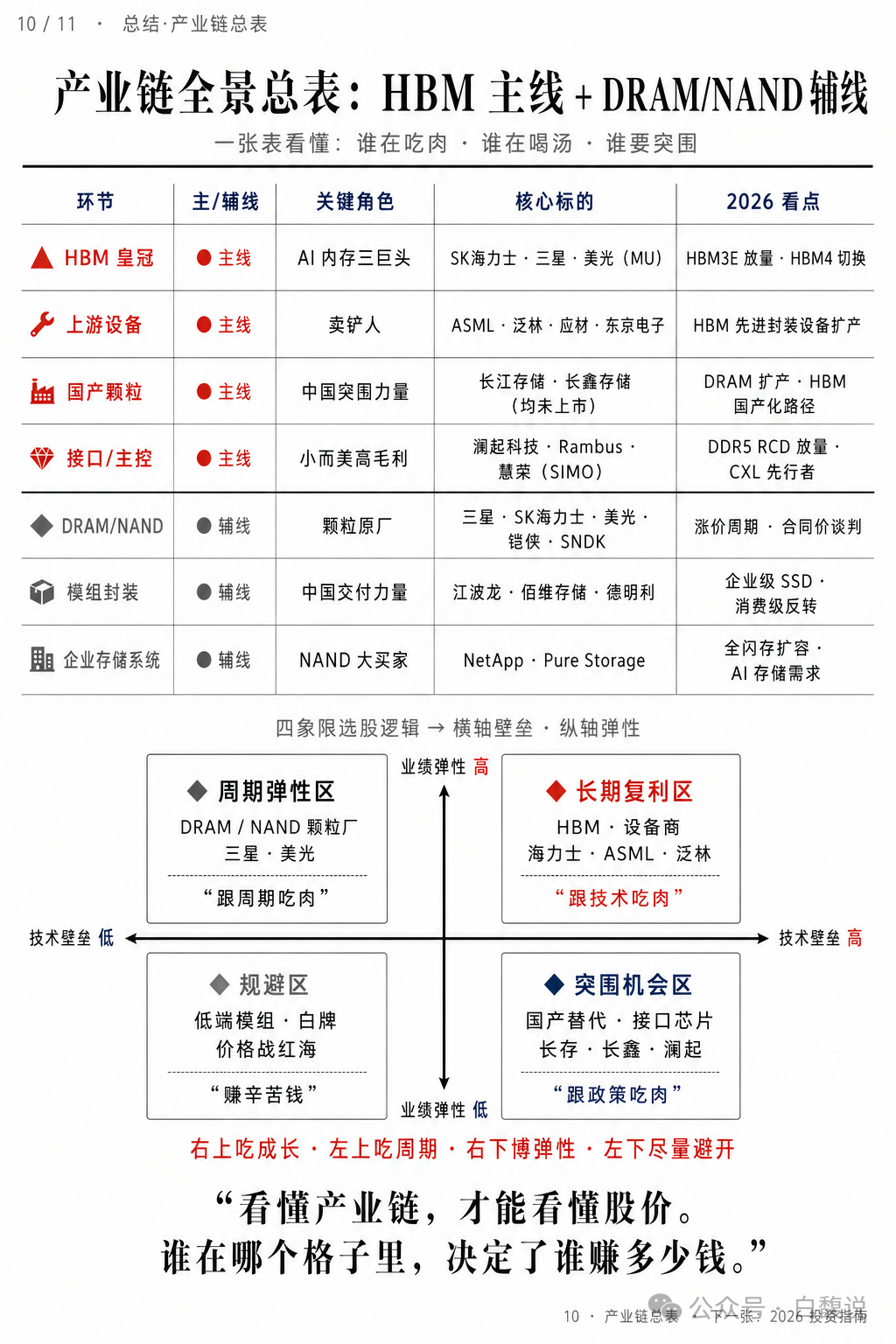
HBM皇冠(海力士/三星/美光)和设备商(ASML/泛林/应材)处于“长期复利区”,靠技术吃肉;DRAM/NAND颗粒厂处于“周期弹性区”,跟周期吃肉;国产替代(长存/长鑫/澜起)处于“突围机会区”,跟政策吃肉;低端模组为规避区,赚辛苦钱。看懂产业链,才能看懂股价。
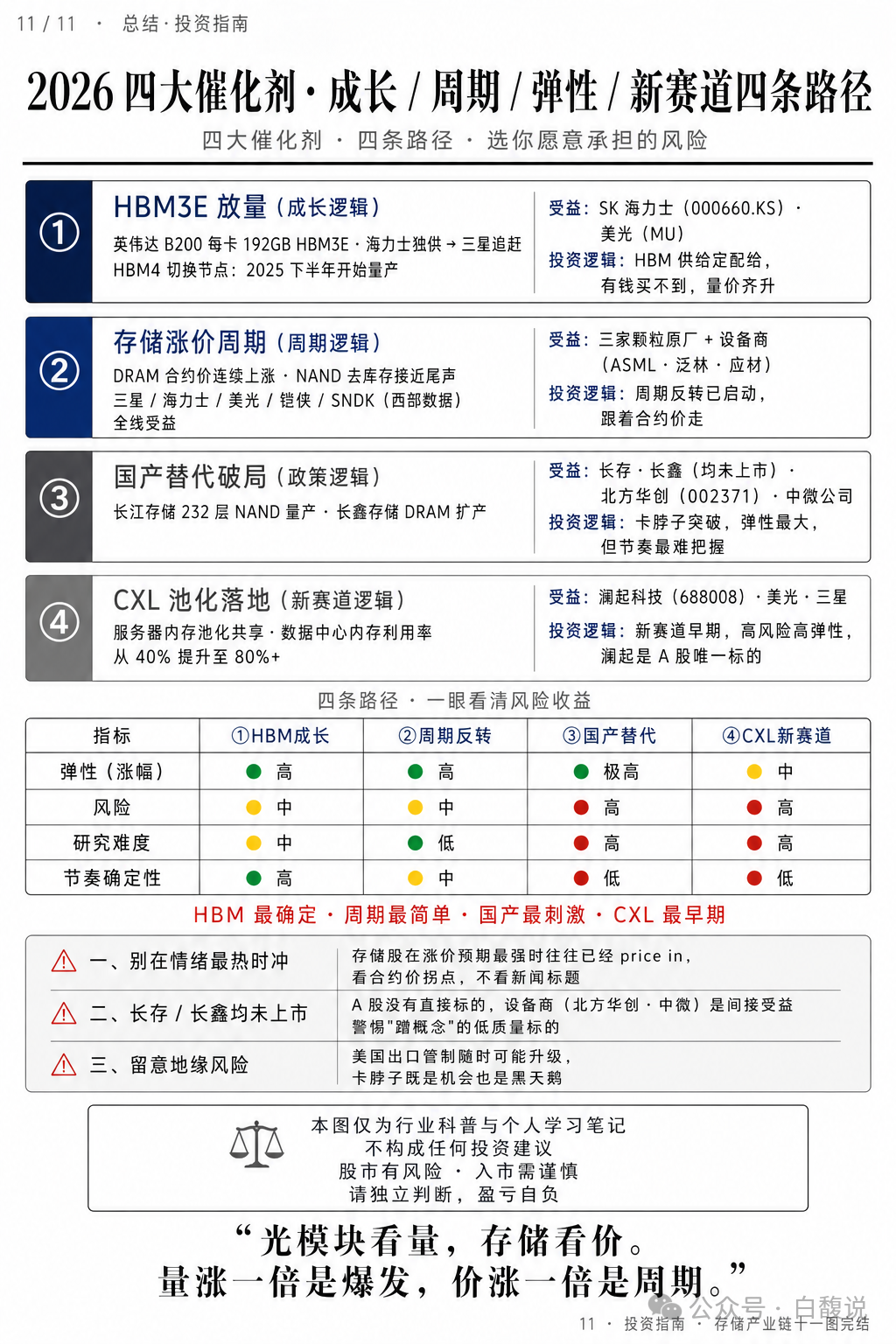
①HBM成长逻辑:B200放量,海力士独供,量价齐升;②存储周期反转:DRAM合约价连续上涨,设备商受益;③国产替代破局:长存232层NAND量产,北方华创/中微间接受益;④CXL新赛道:内存池化提升利用率至80%+,澜起为A股唯一标的。HBM最确定,周期最简单,国产最刺激,CXL最早期。
编辑:是说芯语-小明吧
转自:白馥说

是说芯语原创,欢迎关注分享
合作洽谈,进入公众号:服务—>商务合作