 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库英特尔发布288核CPU,推出三款“芯”品

其实早在2025年的Hotchips,英特尔就发布了其首款全E核(Efficient-cores )至强(Xeon)处理器。据当时介绍,这款名为Clearwater Forest的处理器是公司首款采用18A工艺制造的至强处理器。
据当时介绍,该款处理器拥有 288 个能效核心。从纸面参数来看,这是英特尔在数据中心领域的一次野心勃勃的尝试。
正因如此,该芯片自发布以后,受到了大家的广泛关注。在今天,英特尔终于彻底披露了这颗芯片——全新英特尔至强6+处理器的详细面纱。与此同时,英特尔还发布了以太网800系列新成员—英特尔以太网E835控制器及网络适配器,以及AI加速器路线图的最新进展,包括Crescent Island的更多信息,向大家展现了智能体AI时代,英特尔的全栈赋能能力。
负载变了
CPU也变了
在过去很长一段时间,英特尔都是死磕极致单核主的主要代表
一方面,摩尔定律正值红利期,靠缩小晶体管、无脑堆高主频就能轻松提升性能;另一方面,当时的软件和系统全是单线程设计,空有多核也无法调用。在“天下武功,唯快不破”的串行计算时代,提升单核主频是完美统治市场、满足用户需求的最直接路径。
但后来,无论是芯片还是终端应用,都开始变了。
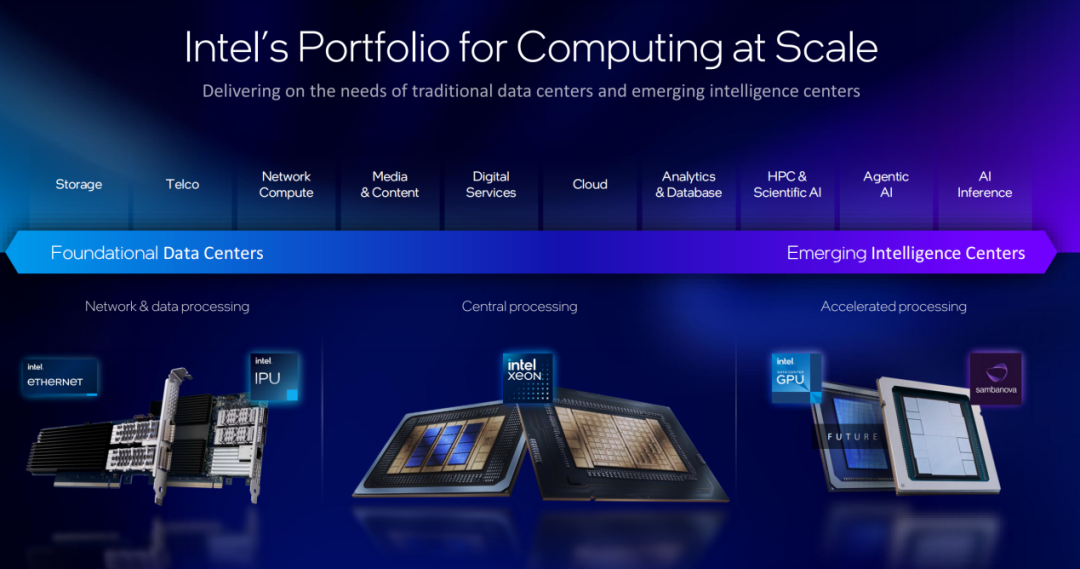
英特尔公司执行副总裁兼数据中心事业部(DCG)总经理Kevork Kechichian此前在一场沟通中也以数据中心为例举例说:从数据中心的角度来看,客户的需求范围十分广泛——从存储和数据库等传统工作负载,到跨系统的数据迁移,再到数字服务、电信和网络。“同时,我们也看到对AI和推理相关工作负载的需求日益增长。对我们而言,将这些需求转化为解决方案至关重要。这为我们应对多样化的市场提供了独特的机会。”Kevork Kechichian接着说。
在他看来,指标因工作负载而异。而根据应用的不同,英特尔也关注从高性能核心到高密度核心的方方面面。按照英特尔观察,数据中心的工作负载可分为三大类:需要高密度计算的横向扩展(Scale-out)工作负载和网络、需要平衡性能和数据吞吐量的通用工作负载以及包括训练和推理在内的计算密集型和AI工作负载。
针对未来的工作负载需求,Kevork Kechichian表示,届时基础工作负载与AI工作负载的增长大致各占一半。其中,传统的基础工作固然会对处理能力提出持续且较高的需求;与此同时,过去很长一段时间依靠专用 GPU 来完成模型训练的场景,因为需要为企业级大规模智能业务提供支撑,如何为此类场景提供针对性的CPU解决方案,也将变得至关重要。
除了基础工作负载以及当前以训练为主的“前沿模型”(主要依赖加速器和GPU进行模型训练)之外,越来越多的需求正在向推理侧迁移。由于推理工作负载与训练工作负载存在显著差异,而这正是英特尔能够发挥自身技术优势的领域。
从Kevork Kechichian的介绍我们得知,到2030年,现有数据中心底层架构仍将持续发挥价值,且会承载近50% 的工作负载。这也让英特尔的产品规划、路线图制定及远期布局具备了延续性。基于这一判断,当前绝大多数工作负载均以x86 架构为核心。“其中一些工作负载(包括推理和智能体 AI)甚至几乎将完全在 x86 上运行。这并非 x86 架构试图取代其他所有架构,而是因为我们 CPU 内置的各类加速器与引擎,性能已能够满足需求,无需额外添置其他的加速设备。”Kevork Kechichian接着说。
有见及此,英特尔针对不同工作负载优化出两类处理器核心。其中一类是被称为P-core(性能核)的高性能内核,该系列优势良好的产品已经部署在至强6中。凭借其突出的性能优势,至强6获得客户的高度认可。与此同时,按照Kevork Kechichian所说,还有一类全新核心正在逐步兴起,那就是能效核(E-core)。因为从智能体工作流的角度来看,这些核心正变得至关重要。
正是基于这些见解,英特尔推出了全新至强6+处理器——
发布288核处理器
18A首次走向数据中心
在正式介绍至强6+前,英特尔至强产品总监Kira Boyko对当前的市场给出了他的判断。如他所说,现代5G 核心网与云原生工作负载,正对基础设施提出前所未有的严苛要求,进而催生三大核心诉求:提升性能密度,在减少机架空间的同时处理更多的任务;提升每瓦性能,降低TCO;为关键业务部署提供高可靠性保障。
至强 6+ ,正是为解决这三个关键问题而设计的。作为至强6家族的新成员,至强 6+ 专为云原生、智能体AI以及网络密集型工作负载提供卓越的性能密度、能效与运营扩展。
从配置上看,至强6+提供业界最高的内核密度,拥有多达288个E-core(能效核)。与上一代产品相比,性能提升高达2.5倍。与同类产品相比,每线程每瓦性能提升高达45%,可为云原生、电信和智能体AI驱动的工作负载提供高并发和快速响应能力;12通道DDR5内存,具有可扩展带宽,适用于高密度系统;96通道PCIe Gen 5和CXL支持,加速跨异构基础设施的数据流动。

除此以外,该芯片还具备以下几个特点。一方面,集成英特尔应用能源遥测技术(AET),能实现实时、工作负载级的CPU能源和活动遥测。从英特尔至强6+处理器开始,该技术可提高工作负载级能耗的可见性;另一方面,高达9:1的服务器整合率,使其与第二代英特尔至强处理器相比,可大幅减少占地面积,降低TCO;此外。内置于芯片、包括英特尔SGX和英特尔TDX在内的的可靠性机制,能以支持机密和多租户部署。
基于这些强悍的配置,至强6+针对包括网络基础设施(如5G核心网的控制面、用户面及下一代防火墙);媒体业务(如CDN内容分发网络、流媒体、实时媒体处理与传输);Web及微服务(如服务网格、代理服务器、网页托管与电子商务平台);以及存储(如分布式冷热数据层)在内的一系列关键基础工作负载进行了优化,并获得了不错的表现。

能取得这样的成绩,架构的领先型功不可没。作为英特尔过去几代处理器设计中解耦式方法设计的新集大成者,至强6+结合了多种制程工艺和封装技术,实现了如此高的核心密度。
据介绍,在至强6+上,英特尔采用了一种称为“Foveros Direct 3D”的3D封装技术,将基于18A工艺制造的计算Tile堆叠在基于Intel 3工艺的底层Tile之上,仍由 EMIB 封装技术完成互联。具体而言,英特尔采用四个基于18A工艺的制程计算芯片构建了至强6+,每个芯片包含了24个核。这些晶片堆叠在 3 颗Active base tiles上方,Active base tiles集成了片上网状互联架构、末级缓存与内存子系统。根据需求,英特尔在这代芯片上海沿用了至强6的I/O tile,并用EMIB技术将所有部分连接在一起,承载裸片之间海量的数据交互。

由此可见,应用在CPU上的Intel 18A工艺对这颗芯片的性能起着重要的作用。作为首款采用Intel 18A制程打造的数据中心CPU,至强6+在现实世界的功耗限制下,依然能提供强劲且持续的性能,这精准解决了新兴智能体AI对编排、并发与数据流动的严苛需求。
多款芯片亮相
打造全栈技术赋能
毫无疑问,至强6+拥有很强的性能。但正如英特尔所说,随着AI、云和分布式工作负载持续扩展,网络成为决定整体基础设施性能和效率的关键因素。也就是说想要充分释放产品潜力,就必须依托串联所有硬件的互联交换架构。
英特尔认为,现在的网络早已不能只满足于高速传输,更要成为系统能效的主动支撑单元。于是,在设计以太网产品的时候,英特尔制定的目标是超越单纯的数据传输,而是希望通过提供一个针对工作负载优化的基础架构,确保最关键的分布式系统在基础设施扩展过程中能够以巅峰效率运行,并安全、有效地进行扩展。
基于这样的思考,英特尔推出出全新的以太网解决方案 E835,旨在通过专注于性能、可靠性、灵活性和效率四个关键领域,来提供优化的网络。

据介绍,作为一款专为更高每瓦性能而设计。英特尔E835-CQDA2网络适配器的每瓦性能比同类产品高出多达1.4-1.9倍,从而降低了现代分布式环境的能耗和运营成本;与此同时,E835支持广泛的端口配置,包括2x25GbE、4x25GbE、2x100GbE和1x200GbE,并可通过英特尔以太网端口配置工具(EPCT)启用更多配置。通过多种控制器和网络适配器配置,E835能提供200 GbE的吞吐量,支持10GbE到200GbE的数据速率。
此外,由于采用RDMA (RoCEv2/iWARP)设计,E835能在降低CPU占用率的同事并最大化效率,支持动态设备个性化(DDP)以简化数据包处理流程,并提升应用性能;得益于集成硬件信任根(Root of Trust)和带签名的 SPDM,E835还支持基于DMTF的可管理性,实现可靠、稳定的运营。
该方案还支持包括Linux、ESXi和Windows在内的多种操作系统,拥有10年以上生命周期,能完全满足下一代基础设施所需的扩展性和效率。
凭借思科、戴尔、慧与(HPE)、联想和超微等行业领军企业的广泛支持,英特尔以太网E835构建了高效、易管理的网络架构。无论是AI训练,还是企业云服务,E835都能提供下一代网络所需的卓越扩展性、出色可靠性与高能效表现。
为了进一步满足AI负载的需求,英特尔推出了代号为Crescent Island的新一代数据中心 GPU。作为一款基于Xe 3P架构的产品,该GPU不仅继承了已被验证的Xe架构优势,还在提供更强效率与能效比的同时,确保了对现代AI负载的软件兼容。“这将是公司首款基于Xe3P架构打造的产品,专为AI推理和智能体工作负载进行了优化。”英特尔方面强调。

得益于 LPDDR5x 显存,Crescent Island 拥有高达 480 GB 的海量带宽与容量,在显著降低总拥有成本(TCO)的同时,能够从容应对词元密集型(Token-intensive)的超大规模工作负载。其采用 350W 风冷 PCIe 设计,以出色的能效比为智能体 AI 的高效扩展提供动力。此外,该 GPU 实现了从原生 FP4 到 FP64 数据类型的全覆盖,确保了运行各类应用时的极致灵活性。
作为专为下一代 AI 设计的力作,Crescent Island 充分继承了英特尔 Xe 架构庞大的生态积累,不仅支持 MXFP4 等先进微缩放格式,更在内存性能与可扩展性上实现了跨越。配合英特尔开放式可编程 AI 软件栈,开发者可通过“上游优先”策略享受开箱即用的模型体验,大幅降低迁移成本。基于同源架构的锐炫 Pro 系列则充当了完美的开发基石,让开发者能在熟悉环境下完成构建与优化,并无缝部署至 Crescent Island,实现真正的架构兼容。
英特尔还透露,公司正与 SambaNova 达成了合作,扩展了公司在数据中心中的推理能力,让大规模的极致性能和低延迟成为可能。“我们正在与他们在软件和工作负载上进行合作,并将成果带给我们的客户。他们与我们的 CPU 和 GPU 产品形成互补,为客户在大规模智能体推理需求中提供更多选择。”英特尔方面表示。
写在最后
正如Kevork Kechichian所说,英特尔数据中心战略的核心在于在所有工作负载之间进行扩展。英特尔在数据中心业务上深耕已久。公司也深谙行业基准,拥有庞大的软件开发者群体。公司也积累了足够的数据,能够为各位客户优化解决方案。
“我们致力于提供最适合您需求的产品,为您下一阶段的 AI 基础设施和 AI 发展提供支持。无论未来以何种方式到来,英特尔都已做好准备。”Kevork Kechichian最后强调。
点这里👆加关注,锁定更多原创内容
*免责声明:文章内容系作者个人观点,半导体芯闻转载仅为了传达一种不同的观点,不代表半导体芯闻对该观点赞同或支持,如果有任何异议,欢迎联系我们。
推荐阅读

喜欢我们的内容就点“在看”分享给小伙伴哦~![]()






