今天,黄仁勋“重新发明”芯片,捅了英特尔AMD老巢
发布时间:2026-06-01来源:芯东西

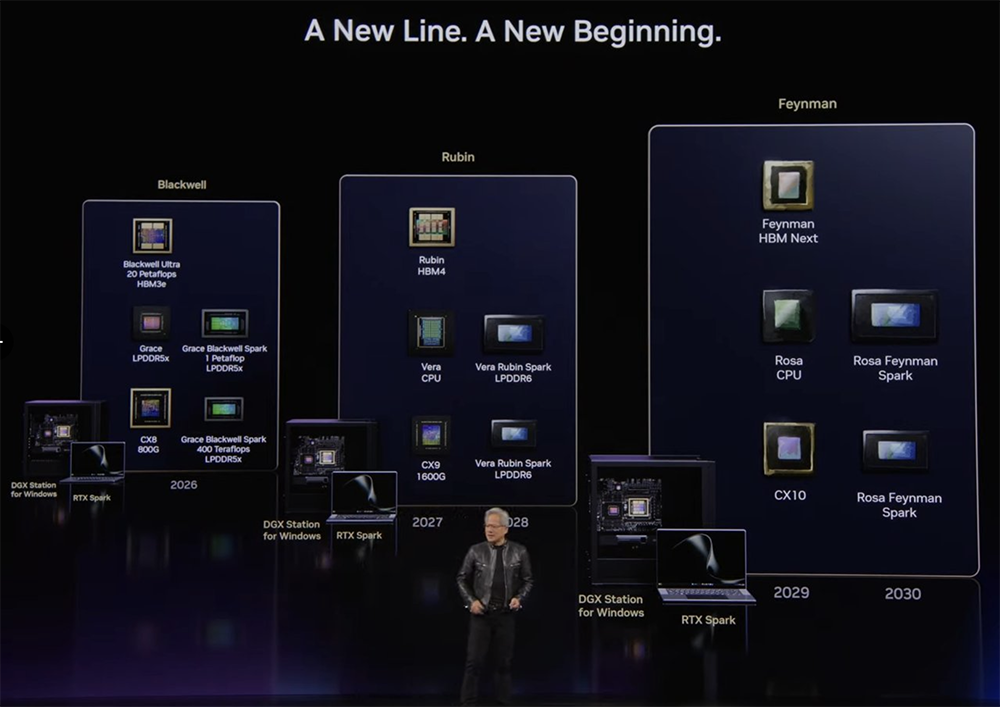
芯东西6月1日报道,今日,在GTC台北大会上,英伟达创始人兼CEO黄仁勋穿着闪亮的黑色皮衣发表主题演讲,发布英伟达首款Arm架构PC芯片RTX Spark超级芯片,以及英伟达豪赌2000亿美元市场的大招——专为智能体设计的Vera CPU。黄仁勋宣布与微软推出全新PC产品线,并称“这是40年来PC产品线首次全面革新”,同样的智能体处理模式还将延展到各种设备上。他说,计算机的这次革命,重要程度不亚于普通手机演变为智能手机,英伟达已为此制定产品路线图,每一代架构(Grace Blackwell、Vera Rubin、Rosa Feynman)都将配备台式机、笔记本和工作站。在Q1财报期间,英伟达曾透露全新Vera CPU将开启一个价值2000亿美元的市场,预计Vera芯片收入将在本财年末达到200亿美元,成为“第二大销售贡献者”。今日,黄仁勋称Vera CPU具有革命性意义,其产能爬坡令他非常满意,“目前的订单量已注定它将成为我们公司历史上最快速、最成功的产品发布。”Anthropic、OpenAI、马斯克旗下SpaceX三家AI巨头均率先部署Vera CPU。“NVIDIA Vera是英特尔和AMD x86_64处理器有史以来最强大的竞争对手。”Phoronix CPU Benchmark Suite作者Michael Larabel评价说。Vera CPU与英伟达今日发布的全球最强大Windows平台桌面AI超级计算机DGX Station,正是英伟达为智能体运行开拓的两大全新市场。DGX Station for Windows由微软合作开发,基于英伟达DGX Station系统设计,搭载英伟达GB300 Grace Blackwell Ultra桌面级超级芯片,提供最高748GB统一内存、20PetaFLOPS FP4算力、800Gbps ConnectX-8 SuperNIC网络,与所有Windows软件兼容,可运行万亿参数级AI模型,并可同时运行数百个智能体。该超算预计将于今年第四季度上市。英伟达还与宇树科技联合发布了集成宇树H2 Plus机器人、Sharpa Wave五指灵巧手、英伟达Jetson Thor处理器的全新NVIDIA Isaac GR00T人形机器人参考设计。
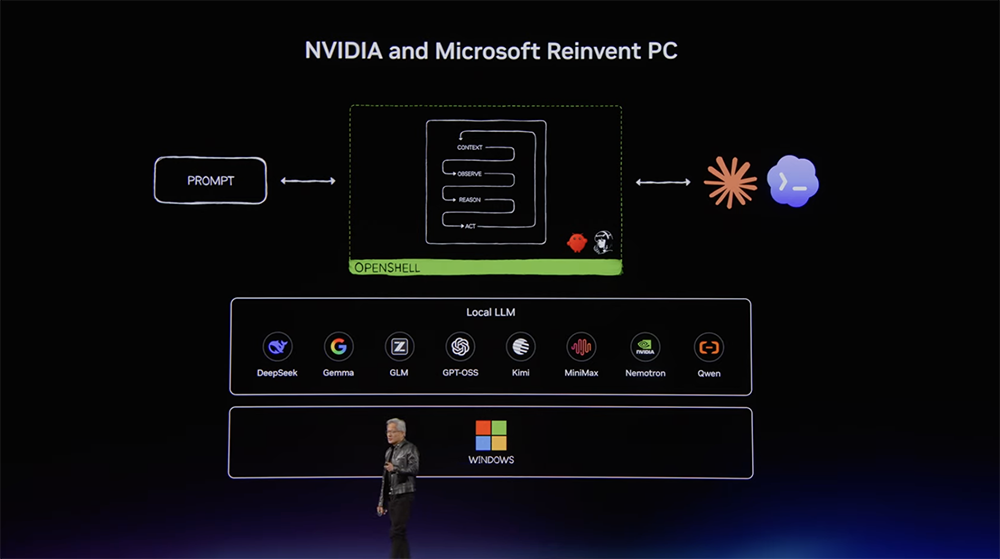
“时隔40年,微软与英伟达将重新发明PC(个人计算机)。”黄仁勋宣布,英伟达与微软面向个人智能体时代重新构想PC,推出为游戏和智能体而生的RTX Spark超级芯片。RTX Spark超级芯片采用台积电3nm工艺,内置700亿颗晶体管,提供128GB LPDDR5X统一内存和1PetaFLOPS FP4 AI算力,号称是“史上能效最高的RTX芯片”。其中,Blackwell RTX GPU有6144个CUDA核心和第五代Tensor Core,并通过NVLink C2C芯片间互连技术连接到与联发科合作开发的定制20核Grace CPU。黄仁勋将RTX Spark称作“世界上制造过的最神奇的芯片”,“英伟达100%的软件栈都在其上运行”。RTX Spark融合了英伟达33年的创新成果,为全球首款专为个人智能体打造的Windows PC提供动力。英伟达CUDA可在RTX Spark上原生运行。搭载RTX Spark的PC,可以使用OptiX和DLSS渲染90GB超大型3D场景,使用英伟达Blackwell解码器编辑12K 4:2:2视频,运行具有100万个token上下文的1200亿参数大语言模型,以及使用光线追踪、DLSS和Reflex以1440p分辨率和每秒100帧以上的速度玩3A游戏。以前使用PC,用户要启动应用程序,点击鼠标,输入文字。现在使用RTX Spark和微软Windows,用户只需提出请求,电脑就能完成工作。此外,Adobe为RTX Spark重新设计了Adobe Photoshop和Premiere的架构,新版本在创意工作流程中,可将AI、编辑、调色和特效的处理速度最高提升至2倍。微软与英伟达正在对整个PC进行全面重塑,发布了面向智能体的全新三大Windows产品线,涵盖笔记本电脑、台式机、桌面超算。搭载RTX Spark的笔记本电脑和紧凑型台式机将于今年秋季推出。笔记本电脑厚度仅为14mm,重量仅3磅,有14至16英寸多种尺寸选择,可以24小时不间断本地“养龙虾”。
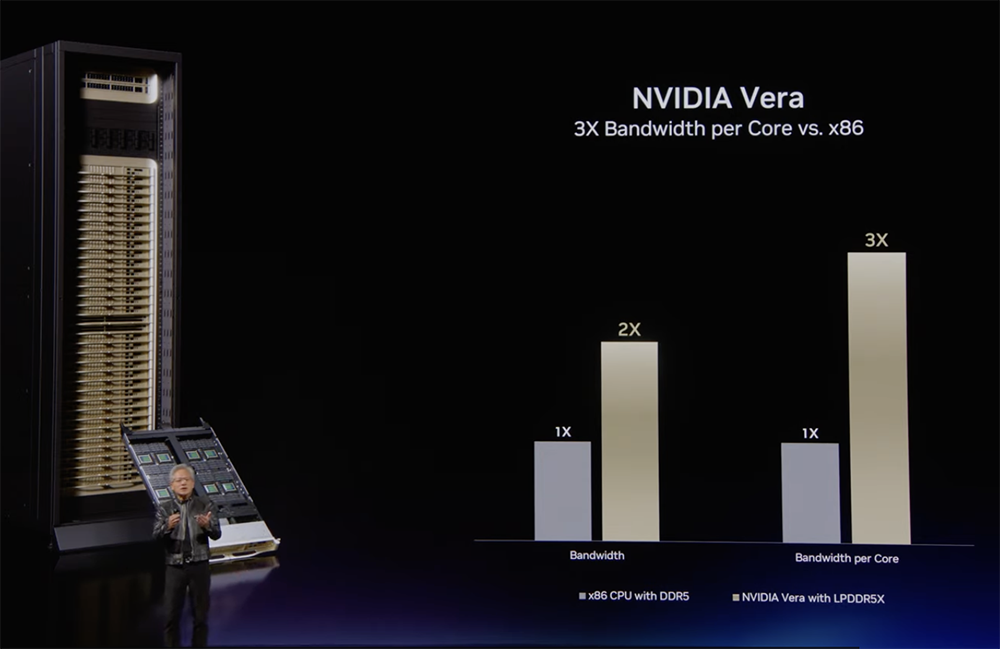
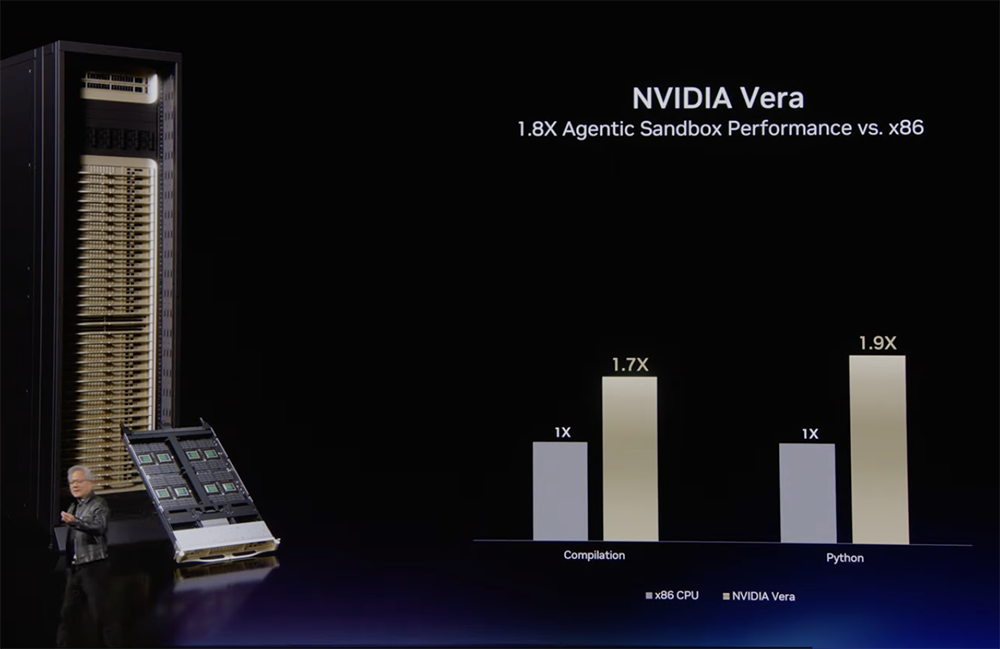
传统CPU追求每颗插槽的核心数,切片、虚拟化、按小时出租。在智能体时代,CPU已成为GPU利用率的瓶颈,直接影响token吞吐量、时延与用户体验。对此,英伟达推出其最先进的CPU——专为智能体而生的Vera CPU。Vera CPU采用LPDDR5X内存(带宽1.2TB/s)、支持PCIe Gen6,内外带宽均达同类最高性能CPU的2至3倍,也是首款在纠正多位错误的同时不损失带宽的CPU。它基于英伟达第二代可扩展一致性架构,将88个英伟达定制Arm核心Olympus统一在一个单片Mesh网络上,在智能体工作负载上实现了最高的单线程性能与最佳能效比。其核心并未分散在多个Chiplet上,核心之间的通信速度比传统CPU快50%。Vera支持内存一致性,NVLink-C2C芯片间互联可将GPU直连到架构,还可以将Vera扩展到多个插槽,在CPU之间实现巨大频宽。与Grace CPU相比,Vera的每个核心每时钟周期可多执行50%的指令。与配备DDR5的x86 CPU相比,Vera每个核心的带宽多达3倍;与x86 CPU相比,峰值内存延迟降低了40%,在检索分析与沙箱执行中保持核心供给及时。在Python代码分析、代码编译等常见智能体工具的行业标准基准测试中,Vera的智能体沙箱性能是与x86 CPU竞品性能的1.8倍。该处理器有四大核心设计原则:领先的每时钟指令数(IPC)/ 单线程性能、每核心带宽、总带宽以及能效。Vera每时钟可取指、解码并执行10条指令,IPC全球最高。英伟达Olympus核心专为现代数据中心工作负载、分支密集型Python运行时、工具调用和沙箱代码执行而优化。每颗核心均为吞吐量调优:神经分支预测器可在每个周期评估两个选定分支,10-Wide解码引擎可在每个周期代入更多工作负载,大型乱序执行引擎维持着指令的运作,新型图引擎的高阶预取器可预测下一个数据路径。Vera片上高速互联总线带宽达3.4TB/s,无芯粒税(chiplet tax),无跨片边界损耗,所有核心可与其他任何核心及缓存无延迟通信,不存在调度冲突。该CPU已进入全面量产,并将于今年秋季通过系统合作伙伴正式上市。Anthropic、OpenAI、SpaceX均是Vera CPU的早期采用者。在SQL 1TB基准测试中,Vera CPU的SQL运行速度达到竞品的3倍。Vera CPU正在为纽约证券交易所(NYSE)运行实时流处理,实现了6倍的性能提升。Grace与Vera CPU是AI领域认证程度最高的CPU、每家企业只要与英伟达合作AI,都将认证Grace和Vera。
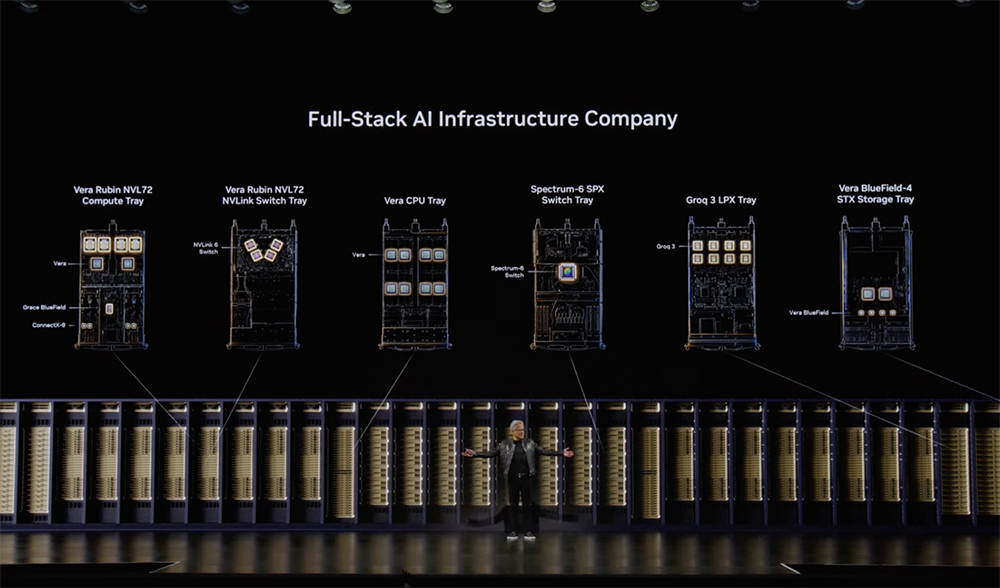
今年年初发布的Vera Rubin,现已全面投产。黄仁勋说,Vera Rubin是英伟达史上最具雄心的项目,全公司40000名工程师都参与其中。Vera Rubin专为运行智能体而生,是一套完整的分解式分布式智能体处理系统,包含Vera Rubin NVL72系统、液冷Vera CPU机架、Vera BlueField-4 STX存储和安全系统、Groq 3 LPX低延迟推理托架和Spectrum-X Ethernet Photonics网络。该平台由中国台湾超过150家供应链生态合作伙伴参与,遍布数百个工厂。所有组件均通过极致协同设计(extreme co-design)打造。英伟达为Vera Rubin打造的供应链,规模是Grace Blackwell的2倍。以前组装一个 Grace Blackwell机架需要2小时,现在只需5分钟。产能更高,出货速度也大幅提升。单个液冷Vera CPU机架容纳256颗CPU,负责模型编排、内存调度与工具调用。在富士康与广达,Groq LPX逐步成形。256颗Groq LPU分布于16个托盘,片上静态随机存储器(SRAM)带宽高达40PB/s,实现超低时延。Spectrum-X Ethernet Photonics是全球首款采用共封装光器件的200Gb/s SerDes以太网交换机,现已投入生产。Vera BlueField-4 STX由BlueField-4加速,在芯片层面处理安全问题:DOCA Argus可将威胁检测时间从分钟缩短至毫秒;DOCA Vault可在机架规模上保护AI数据。
2026年正成为AI发展史上极为重要的一年。智能体的拐点正在推动生产力大幅提升,创造巨大的商业机遇。1、首个Token时延、首次推理启动时延、训练启动时延都更短。2、每瓦吞吐量、每瓦Token数是世界顶级。仅仅因为芯片更便宜就选择错误的架构,这不划算。每瓦Token数才是关键,买得越多,赚得越多。3、可靠性。英伟达已经在超大规模下运营很久,这些经验非常宝贵。4、系统使用寿命。每隔几个月,软件行业就会涌现出新技术。英伟达的系统遍布全球,软件开发者从英伟达CUDA起步,因此生态系统和资产的有效使用寿命自然会更长。如果资产寿命长,则总拥有成本(TCO)低。正如黄仁勋强调的,英伟达已经不仅仅是一家GPU公司和系统公司,而是一家基础设施公司,一切都是为了帮客户实现最大营收、最高利润,并尽快实现目标。
转载说明:本文系转载内容,版权归原作者及原出处所有。转载目的在于传递更多行业信息,文章观点仅代表原作者本人,与本平台立场无关。若涉及作品版权问题,请原作者或相关权利人及时与本平台联系,我们将在第一时间核实后移除相关内容。
 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库