 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库深圳国产芯片成功训练万亿级AI大模型
发布时间:2026-06-06来源:集成电路前沿

📢 一、重磅突破:1.6万亿参数大模型,国产算力全参数训练成功
近日,深圳河套学院AI训练平台项目团队,联合哈尔滨工业大学(深圳)、深圳市大数据研究院、华为等团队,依托昇腾910C国产AI算力集群,完成1.6万亿参数大模型DeepSeek-V4-Pro全参数后训练。
这是全球第三方机构首次在国产算力平台上完成该级别模型训练,打破了万亿级大模型训练长期依赖海外高端算力的局面。
🧠 二、为什么这件事很难?万亿参数训练到底难在哪?
万亿参数大模型是当前AI领域最前沿的方向,在逻辑推理、数理计算、代码编写、长文本理解等方面表现突出。但全参数训练对算力、集群稳定性、算法适配的要求极其严苛。
长期以来的行业现实是:
这次训练的DeepSeek-V4-Pro采用混合专家模型(MoE)架构,后训练时"专家们"之间的通信量是普通模型的几十倍,加上动态注意力机制,对算力调度和显存管理提出了极限要求。
打个比方:以前国产算力是给模型修了条单行道(推理),这次是在单行道上又建了复杂立交桥+多条反馈回路(全参数后训练),计算量和通信量翻了好几倍。
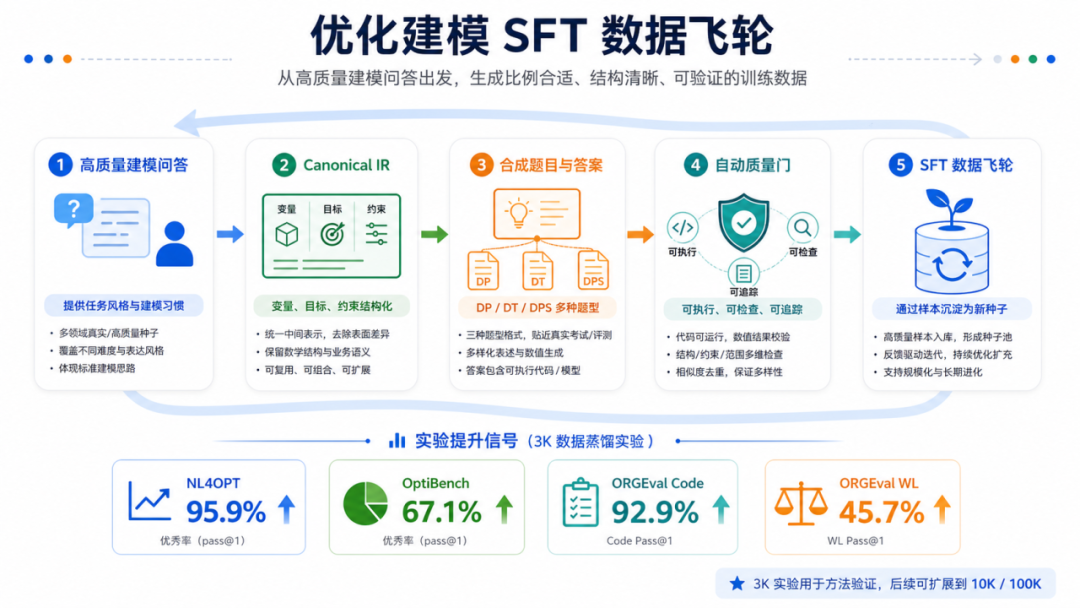
🔧 三、三大硬核突破,让国产算力"跑得稳"
面对极限挑战,团队在国产AI算力集群上实现了三大关键突破:
| 1500多步训练零中断零报错 |
最终成绩单:
📊 模型算力利用率(MFU):超过30% 📈 关键训练算子效率:提升14% ✅ 各项指标均达到工业级运行标准
🎯 四、这次突破意味着什么?
对产业:
国产AI芯片已可承担顶级大模型训练任务,技术路径具备可行性 有助于提升国内AI产业链自主化水平,降低行业应用成本 推理≠训练,这次证明国产算力不只是"能用",而是"能扛"
对人才:
河套学院将万亿级训练作为"练兵场",学生直接嵌入真实训练场景 已培养学生42名,形成"青年教师指导+博士生攻坚+工程团队支撑"的协同机制 探索"顶尖人才培养、基础模型研发、国产生态建设"三位一体的新型平台模式
🔮 五、下一步:长文本、AI智能体,国产算力还能走多远?
深圳河套学院表示,接下来将联合生态伙伴持续优化算力集群性能,围绕长文本处理、AI智能体等方向开展技术探索,持续挖掘国产算力应用潜力。
从推理到微调,再到全参数后训练——国产算力正在一步步啃下最硬的骨头。
万亿参数大模型训练,曾经是国产算力的"禁区"。这一次,禁区被打开了。

集成电路行业交流群

免责声明:本文内容来源于网络,除原创作品,本平台所使用的文章、图片等相关内容,属原权利人所有。集成电路前沿转载仅作为行业信息及新闻分享,不代表集成电路前沿支持或赞同本文观点,若有任何异议或侵权,敬请联系集成电路前沿,我们会及时处理,谢谢!






集成电路前沿每日为大家奉上最新的集成电路行业资讯,欢迎扫描下方二维码关注
|


转载说明:本文系转载内容,版权归原作者及原出处所有。转载目的在于传递更多行业信息,文章观点仅代表原作者本人,与本平台立场无关。若涉及作品版权问题,请原作者或相关权利人及时与本平台联系,我们将在第一时间核实后移除相关内容。





