 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库虚拟细胞研究进入Next Level:中国学者推出“细胞锻造厂”,让AI智能体自主设计优化虚拟细胞模型


撰文丨王聪
编辑丨王多鱼
排版丨水成文
在计算生物学这一融合了生命科学与数据科学的前沿领域,科学家们长期面临一个巨大挑战:如何设计出能精准预测细胞在药物、基因编辑等干预下如何反应的数学模型(即虚拟细胞模型)。这个过程需要同时精通机器学习、统计学和深厚的生物学知识,以同时解决生物学复杂性、多模态数据异质性以及跨学科专业知识,堪称“跨学科炼金术”。
近日,耶鲁大学博士生唐相儒等人联合宾夕法尼亚大学、亥姆霍兹慕尼黑中心、斯坦福大学、谷歌 DeepMind 及哈佛大学等机构的研究人员,在预印本平台 arXiv 上发表了题为:CellForge: Agentic Design of Virtual Cell Models 的研究论文。

虚拟细胞:数字世界里的生命模拟
要理解 CellForge 做了什么,首先要了解“虚拟细胞建模”(Virtual Cell Modeling)这个领域。简单来说,它的目标是在计算机中模拟一个细胞,并预测当这个细胞遭遇“扰动”时会发生什么。
这些“扰动”可以是一次基因敲除、一种新药的刺激,或是细胞因子的作用。通过单细胞 RNA 测序(scRNA-seq)等技术,科学家能获取细胞在扰动前后数万个基因的表达数据,海量而复杂。
传统上,针对每一个新数据集、新扰动类型,研究人员都需要结合领域知识,手动设计或挑选合适的机器学习模型架构,过程繁琐且高度依赖专家经验。这就像为每一位病人量身定制一套完全不同的诊断算法,效率低下且难以推广。
从“单打独斗”到“团队作战”:AI 智能体的科研革命
CellForge 的核心创新,在于它采用了“多智能体”(Multi-Agent)协作框架。可以理解为这是一个高度专业化的 AI 科研团队,而不是一个单一的、试图解决所有问题的“超级 AI”。
这个团队分工明确,配合默契——
1、任务分析模块:相当于团队的“情报官”和“文献调研员”。它首先自动解析用户给的单细胞数据集,理解其中包含的细胞类型、扰动信息、数据特征等。接着,它会自动检索相关的科学文献,从中汲取设计模型的灵感和原则。
2、设计模块:这是团队的“智囊团”和“辩论会”。系统会动态组建一个专家小组,成员可能包括“数据专家”、“单细胞生物学专家”、“深度学习架构师”等。它们以“角色扮演”的方式,围绕任务展开基于图结构的讨论。
每位专家提出自己的模型设计方案。
一位“评审专家”负责点评每个方案的优缺点并打分。
专家们也会互相评价同行的方案。
通过多轮辩论,方案不断融合、改进,直到所有专家对某个设计达成高度共识。这个过程能催生出人类专家可能想不到的创新架构,例如论文中提到的、用于处理时间动态数据的“轨迹感知编码器”。
3、实验执行模块:这是团队的“工程师”和“实验员”。一旦设计方案确定,该模块会自动将其转化为可运行的代码,并管理整个训练过程。它具备“自我调试”能力,遇到代码错误时会分析问题、自动修补并重新尝试。训练中还能进行轻量的超参数调优,并在完成后自动验证模型性能。
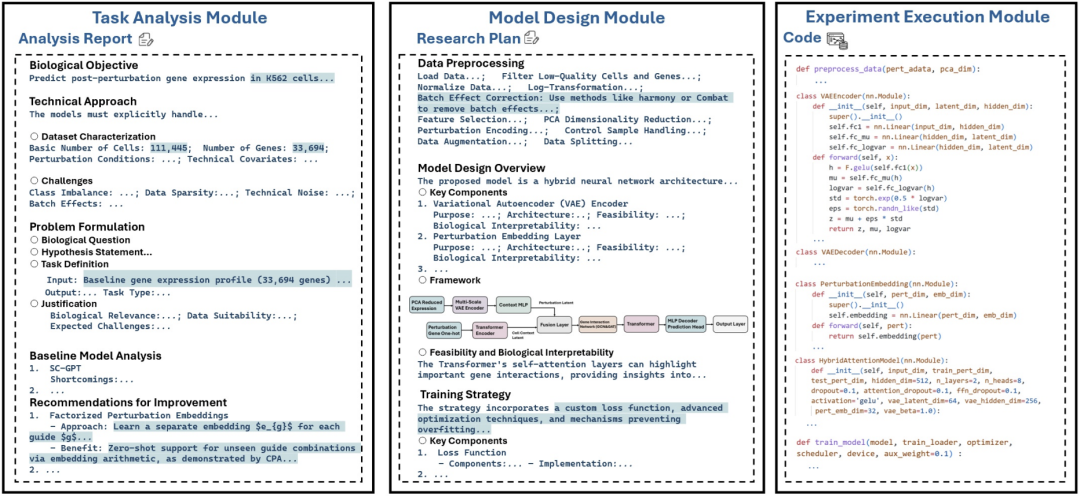
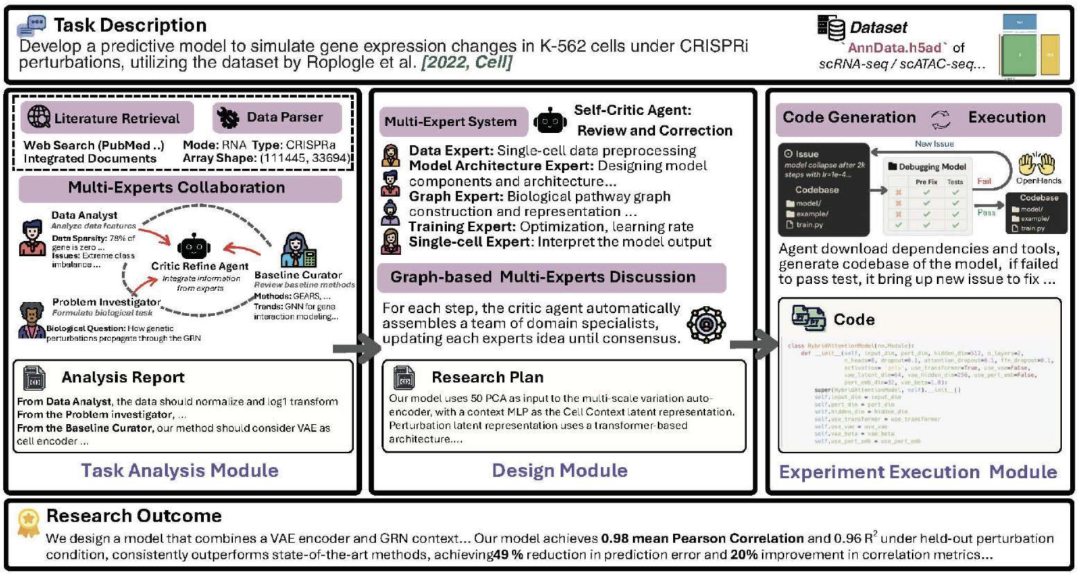
这个框架的魅力在于,它不是从一堆预设的模板中做选择,而是通过智能体之间基于知识的辩论与协作,真正从零开始“创造”出一个新的、针对特定任务优化的模型。这超越了简单的超参数调优,实现了方法论层面的创新。
实战检验:媲美顶尖专家,探索未知领域
研究团队在六个公开的单细胞扰动数据集上对 CellForge 进行了全面测试,任务涵盖基因敲除、药物处理、细胞因子刺激等多种类型,数据模态也包括了 scRNA-seq(用于检测基因表达情况)、scATAC-seq(用于分析染色质可及性)、CITE-seq(同时检测 RNA 和蛋白质)等。
在已知方法较多的领域(例如基因敲除的 scRNA-seq 数据),CellForge 自动设计的模型表现出了强大的竞争力。在 Adamson 和 Norman 这两个经典数据集上,其模型在预测扰动后基因表达的关键指标(例如 MSE、PCC、R²)上,与 CPA、scGPT、Biolord 等人类设计的顶尖模型不相上下,甚至在部分指标上实现超越。
在缺乏成熟方法的“无人区”,CellForge 的价值更加凸显。例如,在预测染色质可及性变化(scATAC-seq 数据)或蛋白质表达变化(CITE-seq 数据)的任务上,由于没有现成的专用模型,传统的基线方法(例如线性回归、随机森林)表现平平。而 CellForge 能够自主设计出适应这些独特数据模态的定制化架构,取得了显著的性能提升。这证明了其方法具备强大的泛化能力和探索性。
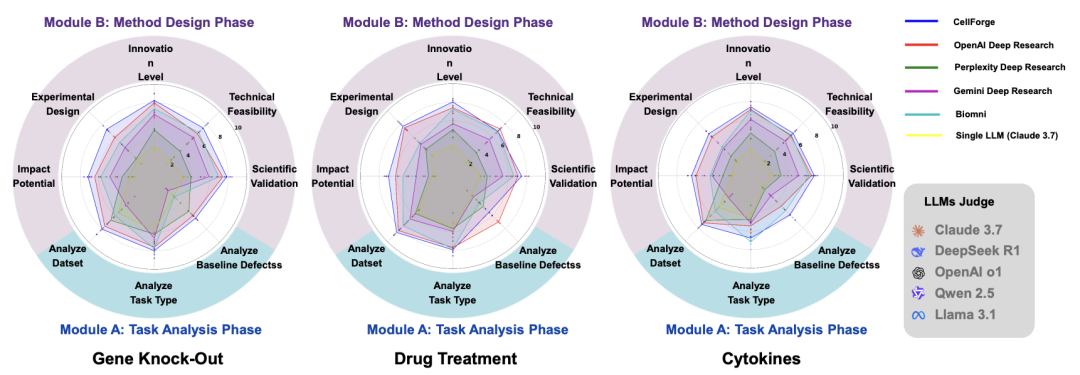
不止于预测:理解生命的“黑匣子”
一个好的模型不仅要预测得准,还要让人类理解其决策。CellForge 的设计也考虑到了生物学的可解释性。
评估显示,其模型能有效识别出在扰动中真正发生关键变化的基因(差异表达基因),并且预测的细胞状态在整体结构上与真实生物学图谱保持一致。通路富集分析也证实,模型捕捉到的信号与已知的生物学通路(例如 NF-κB、p53 信号通路)相符。
未来与挑战:迈向自主科学发现
CellForge 代表了一种科研范式的转变:从人类指导 AI 执行单一任务,转向 AI 自主管理从问题分析到方法实现的全流程。它为计算生物学,乃至更广泛的科学领域,提供了一条自动化方法开发的新路径。
当然,这条路并非一片坦途。论文也诚实地指出了当前局限:
结果可变性:由于自动设计过程的随机性,不同次运行产生的模型性能会有波动,需要多次运行以确保获得稳健的好模型。
计算成本:多智能体的讨论、代码生成与调试、模型训练会消耗可观的算力和 API 调用成本。但相比耗费顶尖科学家数月的人工设计时间,这种成本或许是可以接受的效率交换。
研究团队在论文中分享了一个鼓舞人心的试点案例:两位完全不了解该框架的湿实验室研究人员,仅凭入门教程,就在大约一小时内,成功使用 CellForge 为他们的实际研究问题(免疫治疗和心血管疾病建模)自动设计并训练出了有效的预测模型。
这预示着,此类工具有望极大地降低先进计算建模的门槛,让更多生物学家能将精力聚焦于科学问题本身,而非复杂的编程与算法设计。
CellForge 就像一座刚刚点燃炉火的“锻造厂”,只是,它锻造的不是钢铁,而是探索生命奥秘的智能工具。它的出现告诉我们,AI 在科研中的角色,正从得力的“助手”,向富有创造力的“合作者”悄然演进。
论文链接:
https://arxiv.org/pdf/2508.02276








点在看,传递你的品味





