 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库Science:AI革新蛋白质工程,开始重编程生命


撰文丨王聪
编辑丨王多鱼
排版丨水成文
蛋白质是生命世界里的“万能工具”。从消化食物、抵抗病毒,到传递信号、构成身体,几乎每一个生命过程都由蛋白质驱动。如果能像工程师一样,随心所欲地设计或改造蛋白质,我们就能创造出全新的药物、更高效的疫苗、能吸收更多二氧化碳的植物,甚至是生物合成的环保材料。几乎没有哪个科学领域比蛋白质工程具有更广泛的社会影响潜力。
自然演化在长达数十亿年的时间里缓慢塑造了生命的蛋白质,但蛋白质工程的任务是在极其压缩的时间尺度上——几年内,甚至借助人工智能(AI)的帮助,可能在几天内——创造出具有特定性质的蛋白质,这显然并不容易。
传统的蛋白质工程主要有两条路径:“定向进化”(directed evolution,DE)和“计算蛋白质设计”(computational protein design,CPD)。前者获得了 2018 年诺贝尔奖,它就像“人工加速的自然选择”,通过反复随机突变和筛选,在实验室里“养”出好用的蛋白,但过程缓慢、昂贵,且离不开一个不错的起始蛋白。而后者获得了 2024 年诺贝尔奖,它则试图用计算机模拟和物理定律,从头“计算”出理想的蛋白质结构,虽然搜索速度快,但依赖的理论模型太过简化,难以模拟复杂的生物化学反应。
这两条路径真正的挑战在于,蛋白质的可能性实在太多了。每种蛋白质通常由 20 种氨基酸组成,因此,一个仅由 100 个氨基酸组成的小型蛋白质,其可能的序列数量就高达 20100 种,这已远超宇宙中的原子总数。在这样一片浩瀚的、未知的海洋里,如何精准、高效地找到那条“能完成特定任务”的稀有序列?
近年来,人工智能(AI)通过实现对具有所需特性的蛋白质在高维序列空间中的更高效搜索,进一步推动了蛋白质工程的发展。AI 正在成为这场寻宝之旅的终极“导航系统”和“探测雷达”,它不仅能绘制地图,还能指明航线。
近日,国际顶尖学术期刊 Science 上发表了题为:How artificial intelligence is reengineering protein engineering 的综述论文,该论文系统阐述了 AI 如何从根本上改变了蛋白质工程这一领域。

AI 的“炼丹炉”:条件生成模型
当有一本记载了自然界所有已知蛋白质的“天书”(一个通用 AI 模型),它描述了蛋白质序列的普遍规律。现在,你想从这本书里,“炼”出一种新的蛋白酶,它需要满足几个特定条件:在 80°C 高温下依然稳定,并且能高效催化某类化学反应。
AI 蛋白质设计的终极目标,就是计算出“在给定一系列设计条件(Y)下,一个蛋白质序列(s)出现的概率分布”——即 p(s | y∈Y)。 然后,从这个概率分布中采样,就能直接得到符合要求的候选蛋白序列。这就像在“天书”上施加了一个精确的“过滤咒”和“引导术”。
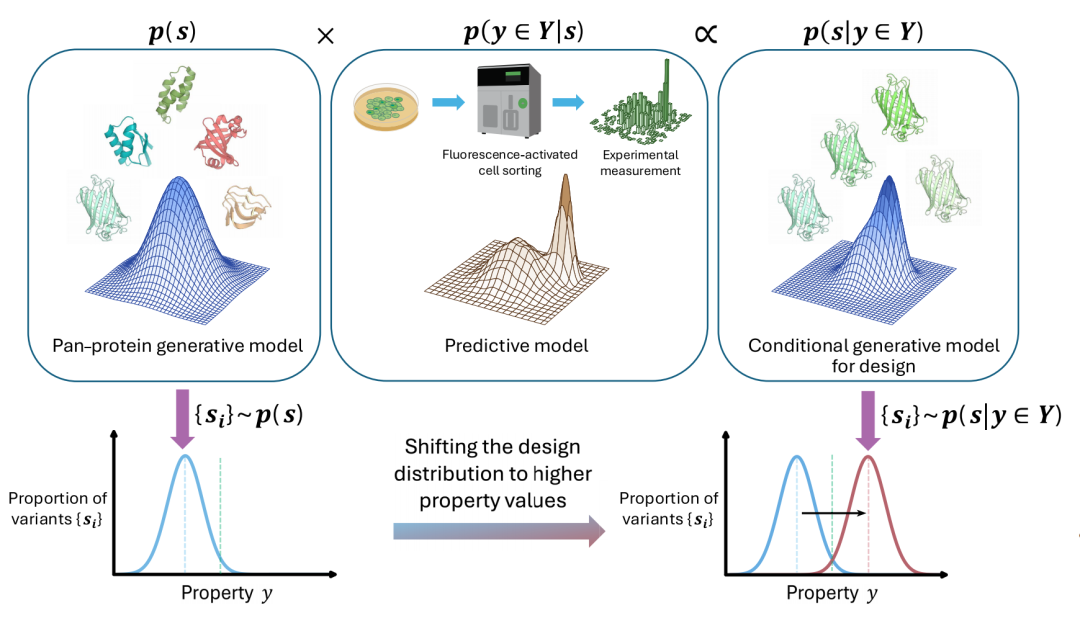
从统计学视角看基于人工智能的蛋白质工程
这篇综述论文指出,实现这个“咒语”主要有三大策略——
预设条件:在训练 AI 模型之初,就把“高温稳定性”、“催化效率”等条件作为“配方”直接“烘焙”进模型。这样做针对性强,但每次想要新条件,就得重新“烤”一个模型,成本高,不灵活。
组合模型:不重新训“天书”,而是给它配上一个“说明书”——一个能预测特定性质的 AI 模型。用数学方法将两者结合,动态地聚焦于我们关心的性质。这种方法灵活,可以利用最新的数据和模型,但计算上可能更复杂。“适应性条件采样”(CbAS) 是此策略的代表。
即时引导:不改变模型本身,而是在模型“生成”新序列的每一步,都用“说明书”去实时“引导”生成过程,使其偏向满足条件的序列。扩散模型等常用此方法,优雅但生成速度可能较慢。
AI “炼丹”实战:从“骨架”到“血肉”
理论框架之下,AI 在蛋白质工程中正以几种具体方式大展拳脚:
骨架生成:先让 AI 想象出一个新的、稳定的蛋白质骨架结构。例如 RFdiffusion 和Chroma,能从一团“噪音”开始,逐渐“雕琢”出全新的、可设计的蛋白质三维骨架,并可以“即时引导”其包含特定的功能位点(例如药物结合口袋)。
逆折叠:有了骨架,下一步是“填充血肉”。逆折叠模型(例如 ProteinMPNN、ESM-IF1)能根据给定的骨架结构,设计出能折叠成这个形状的氨基酸序列。这是目前从头设计蛋白质流程中的关键一步。
联合生成:更前沿的研究试图让 AI“一蹴而就”,同时生成序列和结构,甚至直接精确到原子级别。这对于需要精确控制活性位点原子排布的酶设计,尤为重要。
评分与特征学习:一些生成模型本身不用于“创造”,而是用作“裁判”或“特征提取器”。它们能判断一个给定序列“像不像”一个天然、稳定的好蛋白,或者从序列中提取深层特征,用于预测其结构或功能。
成就、挑战与未来
AI 的引入,已带来实质性的突破。 在蛋白质结合剂设计方面,成功率(命中率)从应用 AI 前的不到 0.05% 提升到了可观的百分比级别,使得许多设计可以通过微量反应板进行表征,而非依赖劳动密集型的高通量筛选。
然而,挑战依然严峻:
数据饥渴:设计能结合小分子、DNA/RNA(而不仅仅是另一种蛋白质)的蛋白,仍然困难,因为蛋白质与这些分子复合物的结构数据稀缺。
柔性难题:目前最成功的模型擅长设计由规则螺旋和折叠片构成的、刚性的“小球型”蛋白。但对于像抗体这样,依赖柔性环区进行分子识别的蛋白质,还缺乏通用的强大设计工具。
“圣杯”尚远:酶设计可能是最难的高峰,它需要精确到原子级别的活性位点化学知识。目前,AI 模型多是在已知酶活性位点的基础上“重塑”其周围结构,还难以从头设计针对全新化学反应的高效催化剂。
评估困境:如何公平地评估和比较不同的 AI 蛋白质设计方法?湿实验验证成本高昂,而依赖 AlphaFold 等结构预测模型又可能偏向于天然蛋白质的“舒适区”,限制了设计的创新性。因此,建立包含真实实验验证的基准测试,是推动领域发展的关键。
结语
总而言之,人工智能(AI)正在将蛋白质工程从一门依赖大量试错和物理近似的“技艺”,转变为一种基于概率模型和数据驱动的、可预测性更强的“工程科学”。它通过条件生成模型这一核心思想,统一了搜索与设计,让我们得以在蛋白质的浩瀚宇宙中进行“智能导航”。
尽管在酶设计、柔性蛋白设计等方面仍面临“硬骨头”,且 AI 模型的通用性和评估体系有待完善,但 AI 无疑已为这个领域装上了强大的引擎。未来,随着更多高质量数据的积累、模型与生物物理原理的更深融合,我们有理由期待,定制具有任何我们所能想象功能的蛋白质,将不再是遥不可及的梦想。
论文链接:
https://www.science.org/doi/10.1126/science.aec8444








点在看,传递你的品味





