顶级膜拜!!诺奖大佬与中国博士联手,发表两篇重磅Nature!“无中生有”地创造出了尺寸逼近天然病毒、超大型自组装蛋白质纳米笼
发布时间:2026-05-25来源:生物通
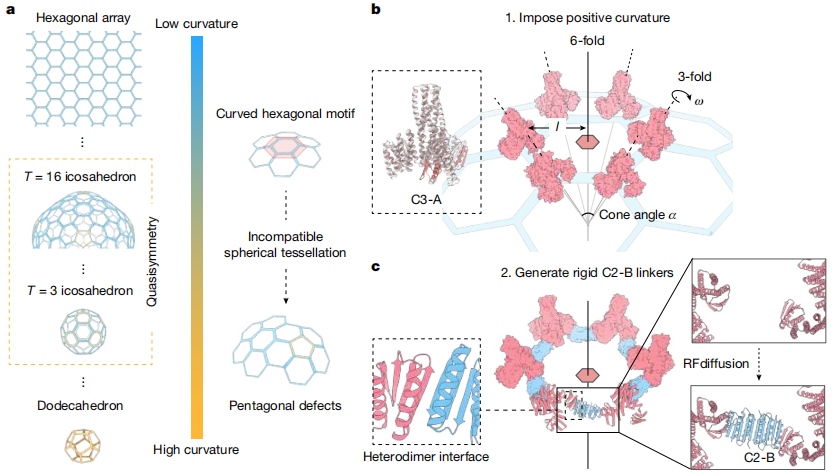
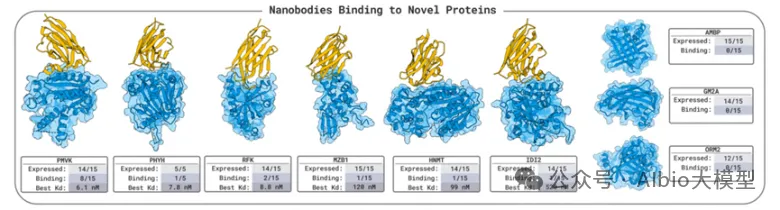
2026年5月20日,国际顶级学术期刊《Nature》同时刊登了两篇来自计算蛋白质设计泰斗、华盛顿大学 David Baker 教授团队的重磅论文。他们借助大模型AI,彻底打破了这一局限,成功在实验室里“无中生有”地创造出了尺寸逼近天然病毒、甚至细胞器级别的超大型自组装蛋白质纳米笼!
在第一项研究中,David Baker 作为最后通讯,王顺智博士为第一作者兼共同通讯作者。在这项研究中,他们通过计算蛋白质设计实现了令结构生物学家着迷的准对称性,并成功将其应用于生物制剂递送和分子细胞生物学领域。
传统蛋白笼设计往往受限于高度对称的组装模式,难以突破 60 个亚基的尺寸上限。为克服这一瓶颈,研究人员提出一种基于几何挫败的计算设计策略:通过预先设定三聚体(C3-A)与二聚体(C2-B)之间的锥角,迫使六边形局部单元在球面上无法完美平铺,从而自发诱导五边形缺陷的形成并驱动球状闭合。借助这一原理,团队成功构建了一系列直径可从 40 nm 连续调节至 200 nm 以上的双组分准对称笼状颗粒,其亚基数涵盖 180 至 2160 个,分子量最高超过 50 MDa,可与天然病毒衣壳相媲美。
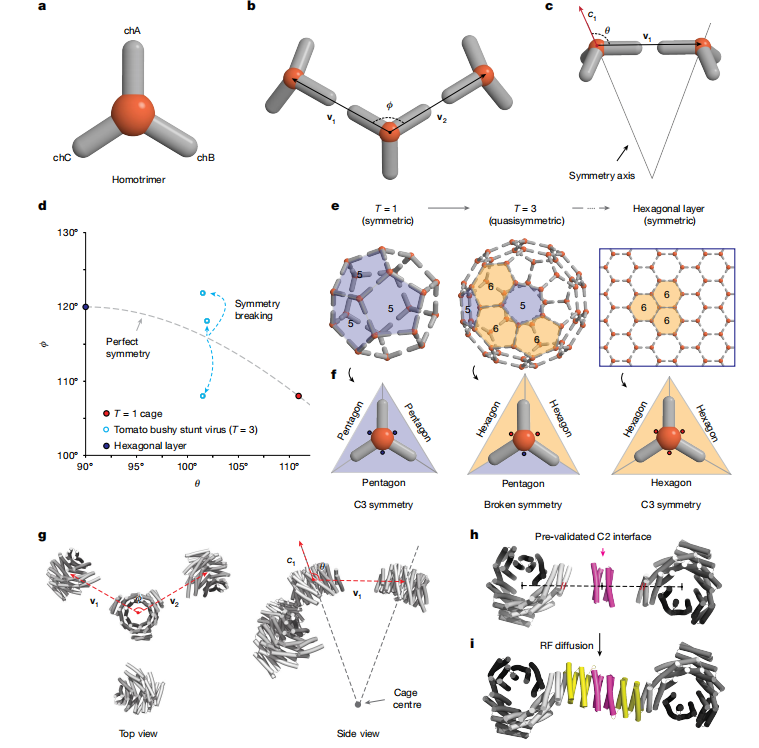
在第二项研究中,David Baker 团队仅仅使用了一种蛋白,就成功构建出复杂的准对称结构。
单组分准对称组装体在生物制剂递送方面具有显著优势,因为仅需一种构件就能实现较大的内部容积。然而,设计这类结构极具挑战,这主要是因为不仅要设计出化学结构相同的亚基,还要使其在对称性不同的位置上既呈现不同的构象,又发生不同的相互作用。
在过去,要想用同一种蛋白造出大的空心球体,最高只能做到 60 个亚基组成的二十面体,如果再大,就需要蛋白在球面上不同位置「变形」成不同样子,而这极难设计。在这一研究中,他们提出了一种新策略:不再死抠每个位置的精确构象,而是通过控制整体物理规律,比如曲率、接触角以及能量分布,让系统在组装过程中自动发生「对称性破缺」。这种在具有编程化曲率的强相互作用构件体系中,自发对称性破缺可以产生准对称性。
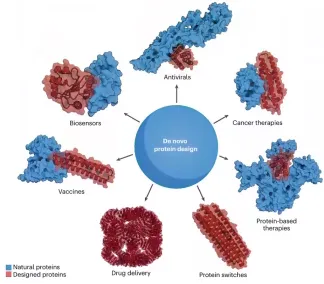
01. AI蛋白质设计
02 AI+多肽设计
03. AI+抗体设计
04. AI+基因编辑
05.AI构建虚拟细胞
主讲老师在学术界和工业界都有丰富算法开发和应用经验,博士毕业于国内顶尖课题组,从事蛋白质结构预测和蛋白质设计的研究工作,相关工作成果已在Cell Systems、Angew. Chem. Int. Ed.、JCIM等国际知名期刊发表论文。目前在知名药企担任高级研究员,主导AI驱动的大分子药物设计平台开发与团队管理。
1.环境搭建:Linux,VS code,Jupyter notebook*b)Linux系统的常用shell命令:vim, ls, cd, less, rm等;c)一些package安装的常用命令:pip, conda, source等。 d)Jupyter notebook的安装和使用。e)VS code的基本配置:连接服务器;选择不同python版本的Interpreter;debug模式的使用等。i.蛋白质定向进化(directed evolution)ii.固定蛋白质主链的序列设计(Fix-backbone protein design)iii.蛋白质的从头设计(De novo protein design)b)关键数据库:RCSB PDB, SCOPe, CATH, UniRef, BFD等c)常见概念和名词: rotamer, scaffold, motif,domain,backbone,side-chain,apo和holo结构,d)使用的不同模型的原理,transformer,diffusion模型,Flow Matching等。3. Rfdiffusion3+ProteinMPNN生成序列a)Rfdiffusion3生成蛋白质骨架结构,ProteinMPNN精细的生成氨基酸序列。f)Rfdiffusion+ProteinMPNN生成序列,AphaFold2筛选序列。整体实操流程:i.计算SAP(Spatial Aggregation Propensity)的值,选择3-6个氨基酸作为hotspot,即结合位点;这里需要使用Rosetta进行计算,首先将安装rosetta,准备蛋白,再计算每一个氨基酸的SAP值,将SAP数值映射到结构上。选择hotspot位点。ii. Rfdiffusion结构设计,生成~10000个蛋白质主链结构;根据上面挑选得到的hotspot位点,更改相应的hotspot参数,生成新的结构iii.ProteinMPNN-FastRelax进行序列设计,每一个主链结构两个对应的序列,共设计~20000个序列;iv.筛选:使用AlphaFold2预测设计结构,预测的置信度pAE<10,预测结构与设计结构的RMSD<1A,从中挑选95个进行实验验证。a)BindCraft——序列生成和筛选的自动化实现BindCraft相比于Rfdiffusion+ProteinMPNN更加用户友好,一站式设计流程,序列的生成和筛选自动化实现。将讲解其中参数的设计和选择,如过滤序列条件、生成氨基酸的偏好性等。使用包括置信度评分(如AlphaFold2预测得到的pLDDT、ipTM)、物理指标(如Rosetta界面能量)和序列特征(如疏水性比例)进行筛选。b)MIT开发的Bolzgen方法原理、安装使用讲解。 安装和使用boltzgen讲解,将详细讲解yaml配置文件的写法,以一个靶点为例,从头生成VHH与该靶点结合。c)PPIFlow:基于flow-matching的生成方法,原理,安装和使用方法。1)从CASP比赛结果来简述蛋白质结构预测方法的发展。基于能量函数 -> 接触图的应用 -> 端到端的预测结构(AlphaFold2)。2)AlphaFold2的模型相比于以前的方法有什么改进a)将基于MSA和基于模板的方法整合,使用注意力机制进行MSA信息和模板信息的相互交流。b)以前提取MSA信息为计算协方差矩阵 ,AlphaFold2创造性的直接将MSA信息作为输入,将图像识别的算法转变成了自然语言处理算法,减少了中间处理过程中的信息损失。3)AlphaFold3相比于AlphaFold2改进了什么,还有什么不足。a)扩展到了多种生物分子的复合物结构预测,包括蛋白质-DNA、蛋白质-RNA、蛋白质-小分子,并使用扩散模型。b)复合物组装与动态预测缺陷,抗体-抗原复合物结构准确度有待提高。4)运行网页server上的AlphaFold3预测结构5)如何使用AlphaFold3预测蛋白质的糖基化,不同糖基化的类型的输入方法。6)AlphaFold3输出结果分析,各项置信度指标的含义,以及如何判断预测的准确度,如pLDDT,ipTM,PTM,PAE。7)本地部署和运行ColabFold,由于AlphaFold3在安装过程中需要下载大量资源,且不能商用,因此不演示AlphaFold3的安装过程,如有问题可以帮助解决。1)pdb文件的解读,每一行中的内容代表什么含义。b)如何将实验值投影到结构图的颜色上,如何画出发表文章中好看的图1)了解不同蛋白质序列库,如UniRef90,UniClust30,Pfam等2)了解不同工具原理并使用:NCBI BLAST,Jackhmmer,HHblits3)给定一条蛋白质序列,比对序列库,生成多序列比对(MSA)*3)绘制序列Logo,可视化的展示每个位点的氨基酸频率和保守性 1)不同同源性的计算方法及应用情景,氨基酸序列的identity和Similarity,BLOSUM62的介绍。1)为什么要做?防止过度学习某一类序列特征,消除序列偏差;也能防止训练过程中数据泄露。2)聚类方法的选择,CD-HIT、MMseq2和Linclust4)实际复现S2ALM这一模型文章中的聚类方法。mmseqs easy-cluster examples/DB.fasta clusterRes tmp --min-seq-id 0.7 -c 0.8 --cov-mode 11)介绍蛋白质的语言模型(26字母语言模型->20氨基酸字母表,上下文依赖->氨基酸的共进化)2)为什么要开发蛋白质大语言模型?1. 相比于结构或功能信息,序列信息更加海量;2. 蛋白质序列通过进化而来,可以学习蛋白质基本规律,折叠,共进化等3)模型架构和基础理论:transformer,多头注意力机制,Bert,GPT,T5等1) ESM系列(ESM-1b、ESM-1v、ESM2、ESM C)3)使用抗体序列库训练的语言模型:Ablang,AntiBERTy1)36层Transformer解码器架构,包含12亿参数2)引入“控制标签”(如蛋白质家族ID、功能属性)作为输入,生成蛋白质序列空间以外的新的蛋白质序列3)基于多模态提示(序列、结构、功能关键词)设计新的蛋白质序列1)获得序列embedding以构建下游模型(Cell systmes文章举例),从文章github仓库中提炼序列embedding的代码并学习使用。2)使用不同的蛋白质语言模型,零样本的预测蛋白质突变效应。3)给定少量的突变效应数据作为训练数据,训练模型,预测新的突变效应值。酶的过渡态理论,theozyme,fitness landscape,epistasis3.CLEAN:基于对比学习的EC号预测挖掘稀有脱卤酶2.利用MutCompute改造PETase(Nature)4.从Frances H. Arnold(2018年因在酶的定向进化领域的贡献获得诺贝尔化学奖)的工作看酶的定向进化方法的发展2.MLDE(Mechine Learning Directed Evolution), 学习序列与酶性能之间的映射关系,推荐新的突变组合(PNAS文章)3.ftMLDE(focused training MLDE),主动学习流程,构建informative的训练数据(Cell Systems文章)。零样本突变效应预测挑选数据集,再通过小样本数据训练的策略微调。a)基于Rosetta的Inside-out策略(Science文章)b)通过Foldit蛋白质折叠游戏改善结构问题(Nat. Biotechnol.文章);2.从头设计荧光素酶,Family-wide hallucination,基于该酶家族的结构幻化出新的结构(Nature文章)3.RFdiffusion+PLACER从头设计丝氨酸水解酶(Science文章)6. 利用预测结构的相似性,挖掘序列的新酶功能(复现顶刊cell文章)*六、蛋白质功能与互作预测;实验验证与AI模型训练预测闭环a)基因本体论(Gene Ontology, GO),b)MF/BP/CC,MF Molecular Function分子功能;BP Biological Process生物过程;CCCellular Component 细胞组分。c)GAF (GO Annotation File) 文件。2)DeepGO-SE,通过蛋白质的语言模型提取序列嵌入,预测蛋白质的功能3)DPFunc:先用蛋白语言模型提取残基特征,再在接触图上用 GCN 学习结构信息,并引入结构域(domain)指导,最后把多层特征映射到 GO 图上,显著提升对罕见功能项和低序列相似蛋白的预测精度4)Prot2Text-V2模型。Prot2Text-V2将图神经网络(Graph Neural Network, GNN)与大型语言模型(Large Language Model, LLM)融合到同一个编码器-解码器框架中,有效整合了包括蛋白质序列、结构和文本注释在内的多种数据,以自由文本形式输出蛋白质功能预测结果5)ProteinKG65构建蛋白质知识图谱,基于Gene Ontology (GO) 和 UniProt 等权威知识库,将蛋白质的功能、结构、相互作用等知识组织成图谱形式,支持下游的机器学习任务,如蛋白质功能预测、表示学习、药物靶点发现等Science文章:使用更深的进化信号:omicMSA+新的深度学习网络:RF2‑PPI。在全人类蛋白质组中筛出一批高置信度的互作,用于补齐人类互作图谱、解释疾病突变和蛋白功能。从约 30 PB 的未组装基因组/转录组数据里挖人类蛋白的同源序列,而不仅仅依赖 UniRef 等传统数据库。构建omicMSA,使得每个蛋白的深度比常规模板 MSA 深 7 倍左右,协同进化信号显著增强。多种蛋白质设计方法、深度学习酶设计、深度学习抗体设计等流程!让学员快速学会David baker核心方法!培训理论结合实操!提供服务器使用!通过详细讲解实操AlphaFold2、AlphaFold3以及pymol和Foldseek等软件让学员学会蛋白质结构预测!通过详细讲解实操ESM系列(ESM-1b、ESM-1v、ESM2、ESMC、ESM3)、GPT的生成模型ProGen让学员学会蛋白质大语言模型!通过详细讲解实操ProteinMPNN、LigandMPNN、ThermoMPNN、Rfdiffusion等软件让学员学会多种蛋白质设计方法!最后通过深度学习酶设计与深度学习抗体设计让学员通过不同方向不同方法更全面的了解蛋白质设计当下的全面性!六天培训流程循序渐进!知识点全覆盖!更是讲解十篇顶刊文献,让学员更好的知道当下蛋白质设计的核心热点以及优势
主讲老师在学术界和工业界都有丰富算法开发和应用经验,毕业于南开大学院士课题组,从事AI多肽设计、抗菌肽设计以及蛋白质设计的研究工作,相关工作成果已在New England、Plos one等国际知名期刊发
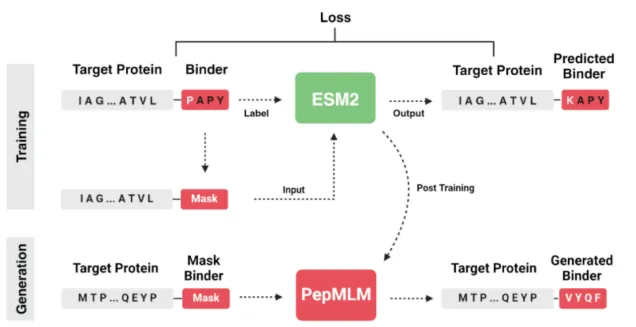
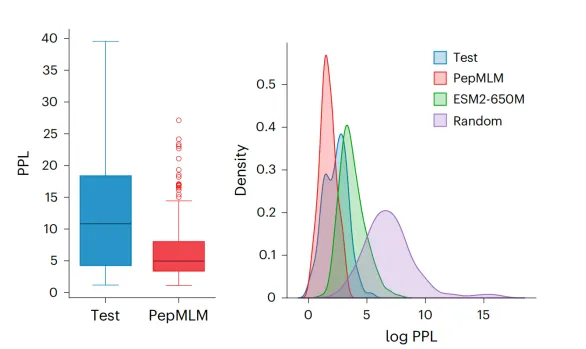
Day 1:短肽设计基础、结构数据库与PyMOL可视化一、短肽设计的生物学基础1.1 短肽分类与生物医学功能:系统讲解结合肽(binder)、功能肽、抑制肽、细胞穿膜肽(CPP)的定义与功能差异;重点阐述8–30个氨基酸线性短肽的优势(易合成、易修饰、适合蛋白-蛋白相互作用界面)与局限(稳定性差、蛋白酶易降解、细胞通透性低)。1.2 短肽-蛋白结合界面的结构特征:介绍短肽在结合界面上的典型构象:α-螺旋、β-折叠、polyproline II螺旋、无规卷曲。1.3 Hotspot残基与相互作用类型:深入讲解PPI界面中的hotspot理论:芳香族残基(Phe/Trp/Tyr)的π-π堆积、疏水残基的疏水作用、带电残基(Arg/Asp/Glu)的盐桥与氢键。1.4 短肽设计的策略框架与流程概览:展示从“靶点选择”到“候选推荐”的完整闭环:靶点序列获取 → 候选生成(PepMLM/LigandMPNN)→ 性质筛选 → 结构评估(AF2)→ 界面分析 → 实验验证概念。2.1 UniProt数据库:序列、功能域与注释检索:演示如何在UniProt中搜索靶蛋白、获取标准FASTA序列、查看功能结构域(Pfam)、亚细胞定位与疾病关联信息。2.2 RCSB PDB数据库:结构检索与质量评估:讲解PDB数据库的搜索策略:按靶点名称、关键词、序列相似性检索;重点教授分辨率(resolution)判断、生物组装体(biological assembly)选择与实验方法(X-ray/Cryo-EM/NMR)差异。2.3 FASTA与PDB文件格式解析:通过文本编辑器直接打开FASTA和PDB文件,讲解文件头信息、序列记录、ATOM记录、链标识(chain ID)与残基编号规则。2.4 Linux基础命令与服务器连接:SSH连接方法、文件系统导航(cd/pwd/ls)、文件查看(cat/head/tail)、路径概念(绝对路径vs相对路径)。三、PyMOL三维结构可视化实操3.1 PyMOL核心概念与界面导航:讲解Object、Chain、Residue、Atom、Selection的层级关系;演示GUI界面与命令行双模式操作,加载示例结构1YCR(p53-MDM2复合物)。3.2 复合物结构加载与多样化显示:练习cartoon、surface、sticks、spheres、lines等多种显示模式的切换与组合;按chain着色(color by chain)、按B-factor着色(反映pLDDT质量)。3.3 结合界面识别与距离测量:使用PyMOL selection语言选取短肽链(如chain B)及其周围5 Å范围内的靶蛋白残基;使用distance命令测量关键原子间距离,识别hotspot相互作用对。3.4 高清图片渲染、标注与结果保存:学习ray渲染、标签添加(label)、视角保存(scene)与高清图片输出(png 300dpi);输出1张带标注的p53-MDM2结合界面图。Day 2:蛋白质语言模型、ESM2原理与Jupyter入门一、从自然语言到蛋白质语言模型1.1 机器学习基本概念:输入、模型、输出、训练与推理:用“识别手写数字”到“ChatGPT对话”的类比,讲解机器学习四要素:输入数据(features)、模型架构(architecture)、参数(parameters)、损失函数(loss);区分训练(training,模型学习参数)与推理(inference,模型预测新数据)两个阶段。1.2 自监督学习与掩码语言建模(MLM)原理:解释“没有人工标签时如何学习”:MLM通过随机遮盖输入序列中的部分token,让模型根据上下文预测被遮盖的内容;在蛋白质中,即遮盖某个氨基酸,根据周围残基预测该位置的氨基酸类型。1.3 Transformer架构与注意力机制:用可视化图示讲解Self-Attention的核心思想:序列中每个位置都能“看到”其他所有位置,并根据相关性分配注意力权重;解释为什么Transformer能捕捉蛋白质中远距离残基的共进化关系。1.4 蛋白质序列的Token化与上下文学习:将20种标准氨基酸对应为20个token(加特殊token共约33个);蛋白质序列即“句子”,同源家族即“语法规则”,保守位点即“高频词”,让学员建立直观的NLP→蛋白质类比。二、ESM2蛋白质语言模型体系2.1 ESM系列模型演进:回顾ESM-1b(650M参数)→ ESM-2(8M到15B多规格)→ ESMFold(结构预测)→ ESM-IF(反向折叠)的发展脉络;说明ESM-2是当前蛋白质序列表示的state-of-the-art模型。2.2 ESM2-650M架构解析:讲解33层Transformer、1280维embedding、约6.5亿参数的规模;说明ESM2在UniRef50上自监督预训练,蛋白质家族的进化约束与结构倾向。2.3 ESM2在短肽评估中的应用:Perplexity打分:讲解perplexity(困惑度)的直观含义:模型认为该序列“像不像”天然蛋白质;perplexity越低,序列越符合天然蛋白质的统计规律,可作为短肽“天然性”的初筛指标。2.4 从ESM2到PepMLM:微调策略与条件化生成:解释PepMLM如何在ESM2-650M基础上,使用PepNN和Propedia数据库中的肽-蛋白配对数据进行微调;核心变化:将靶蛋白序列作为条件(condition),强制模型学习“给定靶点,生成结合肽”的映射关系。3.1 Jupyter Lab界面导航与单元格操作:演示启动Jupyter、浏览器访问、新建notebook、代码单元格(code cell)与Markdown单元格的区分;讲解运行(Run)、中断(Interrupt)、重启内核(Restart Kernel)的操作场景。3.2 Python基础:变量、字符串、列表与print输出:教授当天必需的Python最小知识集:变量赋值(sequence = "ACE")、字符串拼接、列表创建(["A","C","E"]);所有概念均与ESM2评分脚本中的实际代码对应。3.3 ESM2评分脚本运行与参数修改:打开教师提供的esm2_score.ipynb,演示加载transformers库、加载ESM2-650M模型、输入FASTA序列、获取per-sequence perplexity的完整流程。3.4 Perplexity结果解读与对比分析:分别对3条天然结合肽、3条随机打乱序列、3条全丙氨酸序列运行评分,记录结果并对比;讨论:为什么天然肽perplexity最低?随机序列为什么分数高?全丙氨酸序列说明什么?Day 3:PepMLM短肽生成、PPL评估与Python数据处理一、PepMLM短肽生成核心原理1.1 PepMLM方法概述:靶序列条件化的掩码语言模型:系统讲解PepMLM的输入输出:输入 = 靶蛋白序列(≤500 aa)+ 目标肽长度参数;输出 = N条候选肽序列 + 对应的PPL分数;强调PepMLM是“完全基于序列”的设计工具,无需结构输入。1.2 核心创新:肽区域全掩码与条件概率重建:深入解析掩码策略:将靶蛋白序列与肽序列拼接,对肽区域全部设为[MASK],模型需要根据靶蛋白上下文重建整个肽序列;这种“条件化重建”迫使模型学习靶点-肽的配对关系。1.3 Top-k采样策略:平衡多样性与生成质量:讲解解码策略:在每个氨基酸位置,模型输出20种氨基酸的概率分布;top-k采样(论文使用k=3)指从概率最高的3个候选中随机选择,而非总是选概率最高的;k值越大,多样性越高,但可能引入低质量残基。1.4 伪困惑度(PPL)评估体系与阈值解读:详细讲解PPL的数学定义与生物学意义:PPL反映模型对“该肽作为靶点结合剂”的置信度;1.5 PepMLM的方法边界与适用范围:PepMLM计算候选(in silico),de novo设计等。2.1 Python字典与列表:理解结果数据结构:讲解列表(有序集合,用于存储多条序列)和字典(键值对,用于存储序列-分数映射)的基本操作;查看PepMLM输出的JSON/CSV文件,识别其中的列表和字典结构。2.2 YAML配置文件格式与参数读写:介绍YAML的语法规则(缩进表示层级、键值对格式);识别target_fasta、peptide_length、num_sequences、top_k等关键参数的含义与修改方法。2.3 Pandas表格操作:读取、排序、过滤与统计:演示pandas.read_csv()读取结果、sort_values()按PPL排序、条件过滤(如去除含Cys过多的序列)、基本统计(mean/median/count);完成从原始结果到筛选表的转换。2.4 Matplotlib基础:PPL分布直方图绘制:绘制PPL分布图、标记阈值线、直观判断生成质量。三、PepMLM短肽生成与筛选实操3.1 配置靶点FASTA、肽长度与采样参数:选择标准靶点,修改config.yaml中的目标序列路径、肽长度(默认12 aa)、生成数量(50条)、top-k值(3)。3.2 运行生成脚本与实时监控输出日志:在命令行执行python pepmlm_generate.py,观察终端输出的进度条、每条生成肽的序列与PPL值。3.3 结果清洗:去重、去除非标准氨基酸与长度过滤:运行清洗脚本,去除重复序列、含非标准氨基酸(B/J/O/U/X/Z)的序列、与设定长度不符的序列;统计清洗前后的序列数量变化。3.4 PPL排序、性质统计与Top 20候选输出:使用pandas按PPL升序排列,计算每条肽的净电荷(pH 7)、疏水氨基酸比例、芳香族残基数量、半胱氨酸数量;综合PPL与性质指标,人工精选Top 20候选,导出为CSV备用。Day 4:复合物结构预测评估、PyMOL界面分析与批量处理一、深度学习蛋白质结构预测原理1.1 结构预测方法演进:从同源建模到深度学习:回顾SWISS-MODEL、I-TASSER、Phyre2等传统方法的核心思想与局限;讲解深度学习时代AlphaFold2的突破性贡献:Evoformer架构、MSA(多序列比对)与配对表示(pair representation)联合进化。1.2 AlphaFold2与AlphaFold-Multimer的核心差异:明确区分AF2(单链结构预测,输出pLDDT)与AF-Multimer(多链复合物预测,额外输出ipTM与PAE)。1.3 三大评估指标详解:pLDDT、ipTM、PAE:pLDDT(per-residue predicted LDDT)、残基对误差矩阵、界面区域PAE介绍。1.4 短肽-蛋白复合物预测的特殊挑战:讲解短肽复合物预测的三大难点:① 肽链柔性大、构象空间大;② 训练数据中短肽复合物占比低;③ 弱亲和力界面信号弱;说明为什么AF-Multimer对短肽的预测confidence通常低于单域蛋白,以及如何谨慎解读结果。2.1 加载预计算AF2结果:pLDDT着色与质量判断:在PyMOL中加载pdb文件,使用color by b-factor直观展示pLDDT分布,识别低置信度区域。2.2 界面接触残基识别:距离阈值与原子对筛选:使用PyMOL selection命令选取肽链与靶蛋白中距离<5 Å的原子对;利用find_pairs或自定义脚本输出接触残基列表;区分“主链-主链”“主链-侧链”“侧链-侧链”接触类型。2.3 关键相互作用类型判断:氢键、盐桥、疏水堆积:结合PyMOL可视化与距离测量,识别界面上的典型相互作用:氢键(N-O距离2.5-3.5 Å)、盐桥(带电残基对<4 Å)、疏水堆积(芳香环平面间距<5 Å)。2.4 PAE矩阵热图解读与预测可靠性评估:在Jupyter中绘制PAE热图;重点观察肽残基(链B)与靶蛋白残基(链A)交叉区域的PAE值。3.1 Python循环与条件判断:批量处理结构文件:教授for循环遍历文件列表、if条件判断筛选高质量结构,批量读取多个AF2结果的ipTM值,自动筛选ipTM>0.7的候选。3.2 界面接触自动提取脚本运行与结果整理:自动从pdb文件中提取肽-蛋白界面接触残基对;修改脚本中的距离阈值(如从5.0改为4.0 Å),观察接触数变化,理解参数敏感性。3.3 路径A候选肽的结构评估表填写:将Day 3生成的Top 20候选中已预计算AF2结构的肽,逐一填写评估表:序列、PPL、ipTM、pLDDT均值、界面接触数、关键相互作用、综合评级(推荐/保留/淘汰)。Day 5:结构驱动设计、LigandMPNN优化一、结构驱动的短肽设计原理1.1 传统固定骨架设计:Rosetta能量函数与Rotamer库:回顾RosettaDesign的经典流程:输入蛋白质主链骨架 → 能量函数评估 → rotamer库侧链packing → 输出最优序列;说明传统方法依赖物理能量函数,计算成本高且对骨架质量敏感。1.2 ProteinMPNN:图神经网络学习Structure-to-Sequence映射:讲解ProteinMPNN的核心创新:将蛋白质主链看作图(节点=残基,边=空间邻近关系),使用图神经网络(GNN)直接学习“骨架 → 最优序列”的映射;相比Rosetta,ProteinMPNN更快、更准确、对骨架误差更鲁棒。1.3 LigandMPNN:显式建模非蛋白原子与短肽链:在ProteinMPNN基础上,讲解LigandMPNN对非蛋白原子(小分子、核酸、金属离子、肽链)的显式建模。2.1 线性短肽的成药瓶颈:稳定性、通透性、免疫原性:系统讲解短肽面临的三大障碍:胃肠道蛋白酶快速降解、难以穿越肠上皮屏障、潜在的免疫原性反应。2.2 化学修饰策略:环化、订书肽、非天然氨基酸:介绍提升短肽稳定性的常用化学手段:① 头尾环化(end-to-end cyclization)或侧链-侧链环化(如R4-R10内酰胺桥);② 订书肽(stapled peptide,烯烃桥锁定α-螺旋);③ 非天然氨基酸替换(如N-甲基氨基酸、D-型氨基酸抵抗蛋白酶)。2.3 递送策略:细胞穿膜肽融合、纳米颗粒封装:讲解短肽进入细胞的递送方案:与CPP(如TAT、Penetratin)融合、脂质纳米颗粒(LNP)封装、外泌体靶向递送,说明短肽作为蛋白降解靶向嵌合体(PROTAC)配体的应用前景。三、LigandMPNN固定骨架优化实操3.1 复合物骨架PDB准备与链指定:识别靶蛋白链(chain A)与肽链(chain B),确认肽链的残基编号范围;讲解PDB文件格式中链标识与原子坐标的对应关系。3.2 LigandMPNN参数配置:温度、采样数、设计区域:打开config_ligandmpnn.json,讲解关键参数:temperature(温度,控制序列多样性,建议0.1-0.3)、num_seq_per_target(每条骨架输出序列数)、fix_selected_chains(固定靶蛋白链)、redesigned_chains(重设计肽链);学员根据靶点修改参数。3.3 序列重设计与结果对比:原肽vs优化肽:运行python run_ligandmpnn.py,获取LigandMPNN设计的新肽序列;将输出序列与原始PDB中的肽序列进行比对,观察:哪些位置被保守保留?哪些位置发生了突变?突变残基的理化性质变化(如疏水→带电)可能带来什么影响?3.4 优化序列的AF2-Multimer验证与PPL交叉评估:对比原始肽与优化肽的ipTM、pLDDT、界面接触数;同时用Day 2的ESM2评分脚本对优化肽打分,观察perplexity变化;建立“结构优化序列也应具有低perplexity”的交叉验证思维。让学员更好的知道当下蛋白质设计的核心热点以及优势能独立完成蛋白结构可视化:用 PyMOL 加载复合物、识别结合界面、测量相互作用、渲染高清结构图。能使用 ESM2 完成序列评分,用 PepMLM 实现靶标定向短肽生成,并通过 Python 完成数据清洗、筛选与可视化。能用 AF2/Multimer 预测肽 - 蛋白复合物结构,解读 pLDDT/ipTM/PAE 指标,完成界面分析与质量评估。能用 LigandMPNN 基于固定骨架优化短肽序列,结合多指标完成候选肽筛选与成药优化方案设计。建立AI 短肽设计完整思维闭环:靶点选择→候选生成→性质筛选→结构评估→优化验证。具备独立解决实操问题的能力,能合理解读 AI 预测结果、规避模型局限,输出可实验验证的短肽候选。掌握跨工具联用能力,实现 ESM2、PepMLM、AF2、LigandMPNN、PyMOL 的流程化配合使用。
主讲老师在学术界和工业界都有丰富算法开发和应用经验,毕业于南开大学院士课题组,从事AI多肽设计、抗菌肽设计以及蛋白质设计的研究工作,相关工作成果已在New England、Plos one等国际知名期刊发
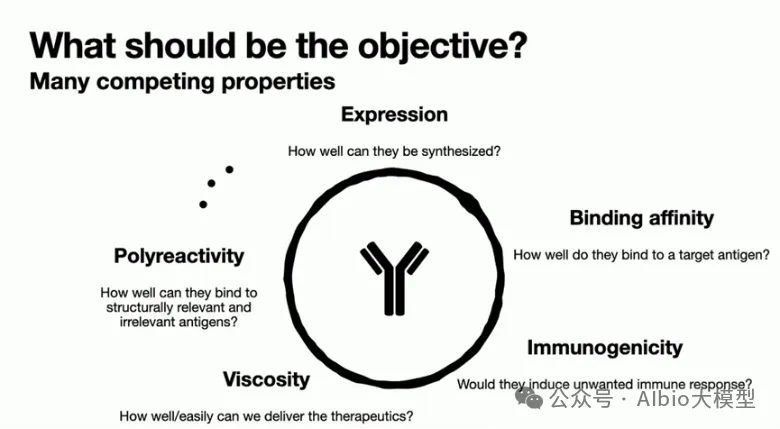
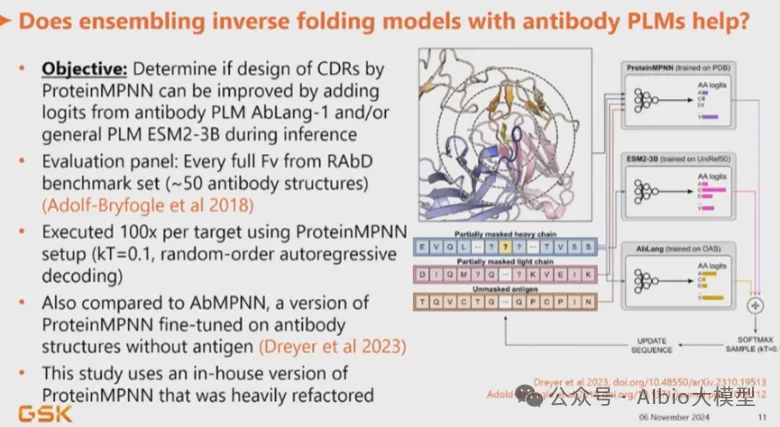
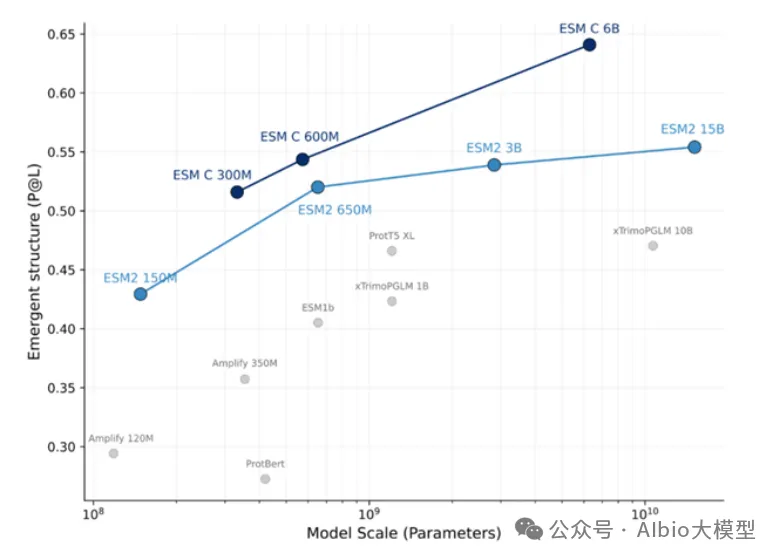
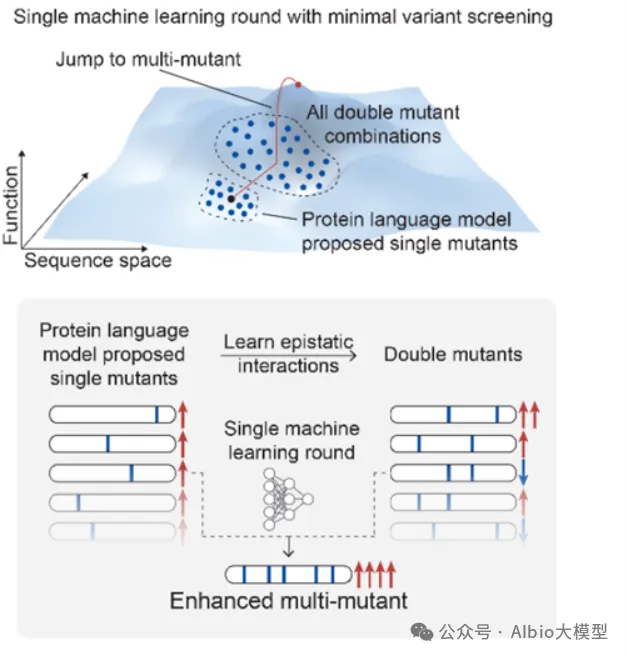
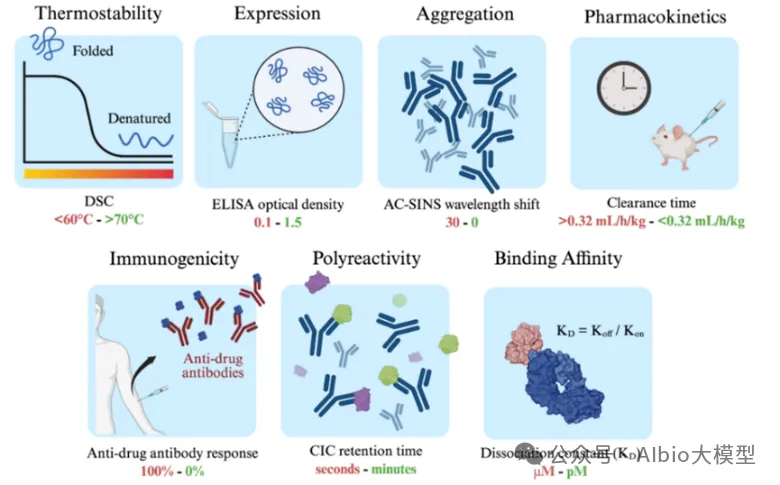
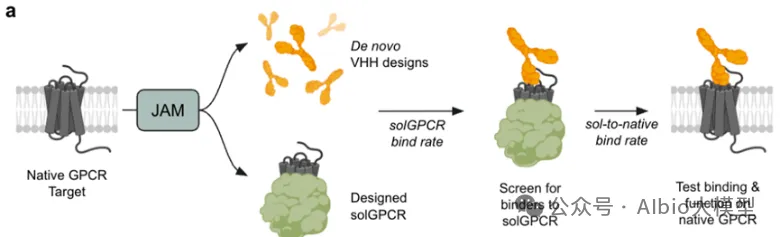
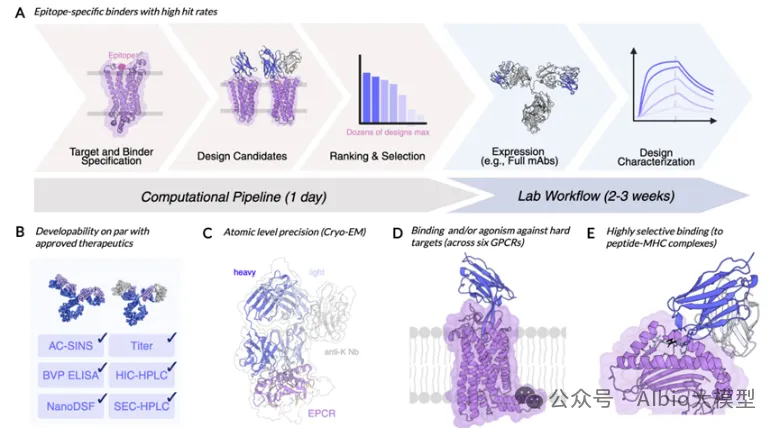
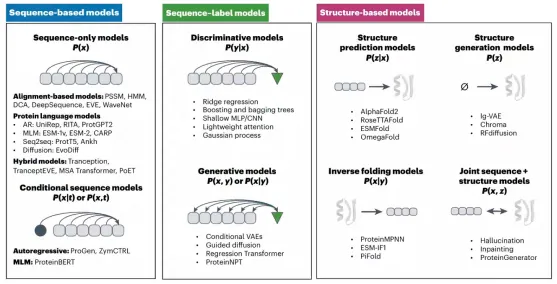
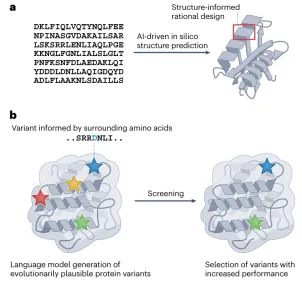
一、代码基础,抗体基础,介绍各大药企在AI辅助抗体药物开发上的布局,复现GSK在抗体亲和力成熟上的工作1. 代码基础知识讲解,环境搭建:Linux,VS code*b) Linux系统的常用shell命令:vim, ls, cd, less, rm等;c) 一些package安装的常用命令:pip, conda, source等。d) VS code的基本配置:连接服务器;选择不同python版本的Interpreter;debug模式的使用等。a) VDJ重排,germline,CDR区域,表位(epitope/paratope),抗体亲和力成熟,抗体的可开发性等概念介绍b) 不同抗体编号方案(Kabat,Chothia,IMGT)讲解,使用python自动化对抗体序列编号,并识别CDR区域*3. 各大药企在AI辅助抗体药物开发上的布局:讲解各大药企公司发表的文献及报告:a) Genetech的lab-in-the-loop,结合了实验和计算方法的迭代优化策略的工作b) Genmab手动建立了多样性的抗体可开发性数据集,以进行可开发性数据的训练和预测.c) GSK、阿斯利康、诺和诺德等在抗体亲和力成熟上做的工作等。1) 通用蛋白结构预测模型:AlphaFold3。u 运行网页server上的AlphaFold3预测结构,https://alphafoldserver.com*u AlphaFold3输出结果分析,各项置信度指标的含义,以及如何判断预测的准确度,如pLDDT,ipTM,PTM,PAE。a) 抗体专用结构预测模型:ImmuneBuilder,IgFold。实操如何在服务器安装和使用。1) 介绍蛋白质的语言模型(26字母语言模型->20氨基酸字母表,上下文依赖->氨基酸的共进化)2) 为什么要开发蛋白质大语言模型?1. 相比于结构或功能信息,序列信息更加海量;2. 蛋白质序列通过进化而来,可以学习蛋白质基本规律,折叠,共进化等3) 模型架构和基础理论:transformer,多头注意力机制,Bert,GPT,T5等1) ESM系列(ESM-1b、ESM-1v、ESM2、ESM C)4) 使用抗体序列库训练的语言模型:Ablang,AntiBERTy3. Adaptyv EGFR Binder比赛——设计靶向EGFR的更高亲和力binder。a) 第一轮比赛,排名第一的方法:BindCraftb) 第二轮比赛,排名第一的方法:Cradle,在Cetuximab的基础上,用的LLM,突变了10个FR的氨基酸c) 第二轮比赛,排名第二的方法:对一个纳米抗体进行人源化改造d) 第二轮比赛,排名第三的方法:保留与结合重要的氨基酸,生成其它氨基酸RFdiffusion+inverse folding1) Efficient evolution,基于序列的语言模型推荐突变点(Nat. Biotechnol.文章) ii. 安装package和模型参数。https://github.com/brianhie/efficient-evolution iii. 运行以推荐突变点:python bin/recommend.py [sequence]2) Structure evolution,基于结构的语言模型推荐突变点(Science文章) i. 了解inverse folding推荐突变点原理2. conda env create -f environment.yml3. conda activate struct-evo4. wget -P ~/.cache/torch/hub/checkpoints5. unzip ~/.cache/torch/hub/checkpoints/esm_if1_20220410.zipiii. 运行以推荐突变点:python bin/recommend.py examples/7mmo_abc_fvar.pdb \ --chain A --seqpath examples/7mmo_chainA_lib.fasta \ --outpath examples/7mmo_chainA_scores.csv \ --upperbound 109 --offset 15. 小样本的抗体亲和力成熟*,在已有少量样本的亲和力数据下训练模型。使用MULTI-evolve的方法预测多点的组合突变。2. 衡量抗体可开发性要考虑的因素,如免疫原性、自聚集性、结合特异性、稳定性等等3. 以一篇专利文件为例讲解AI辅助抗体改造的案例。Patent No.: US12110324B2。Generate:Biomedicines公司通过AI方法在tezepelumab上改成的一种靶向(TSLP)的长效单克隆抗体GB-0895。4. 抗体结构简单物理性质的计算:溶剂可及表面积(SASA)的讲解及计算;等电点的计算;蛋白质表面电荷分布的计算。*5. 讲解Ginkgo举办的抗体可开发性预测比赛的结果。7. 抗体性质预测的模型实践,展示在小样本的情景下训练机器学习模型*2) 模型构建,基于特征工程的机器学习模型(随机森林,XGboost,ElasticNet等);学习根据蛋白质序列和结构信息构建常见特征。seq_features = feature_utils.get_all_seq_features(heavy_seq, light_seq, is_fv=True, isotype='igg1', lc_type='lambda')3) 模型训练和评价,GridSearchCV交叉验证调参等2) 少样本的可开发性预测。给定抗体序列和相应的性质,构建下游模型预测。b) 获得序列embedding以构建下游模型,实现蛋白质序列的不同方式encoding,包括"onehot", "georgiev", “esm”系列模型。c) 深度学习模型的构建。上游的大语言模型+下游简单线性层。d) 模型训练和评价:绘制训练曲线,训练集和测试集的评价指标随epoch的变化,1) 免疫系统介绍,MHC-I和MHC-II,Anti-drug Antibody等基础概念3) 预测免疫原性。netMHCpan的原理讲解,安装和使用1) 人源化的基础知识和流程。目标:保留亲和力+减小免疫原性+好的稳定性和可开发性。CDR移植到人源框架,回复突变,Vernier Zone,2) Germline的搜索,IMGT/V-QUEST 数据库搜索得到V 基因和J基因相似的人类germline序列。3) 人源化的经典方法biophi的原理讲解、安装和使用。4) 基于AI和基于物理能量(Rosetta)的方法是如何辅助抗体人源化的。1) 跨膜蛋白例如GPCR,难以稳定表达为可溶性蛋白2. 基础模型方法概念介绍:Diffusion模型、 flow-matching、全原子(all-atom)建模等1) Rfdiffusion3+ProteinMPNN生成序列,AphaFold2筛选序列。将学会各个包的安装,不同参数的选择,结合的hotspot位点选择。a) Rfdiffusion3结构设计,生成~10000个蛋白质主链结构;根据hotspot位点,生成新的结构:./scripts/run_inference.py 'contigmap.contigs=[B1-100/0 100-100]' 'ppi.hotspot_res=[A30,A33,A34]' inference.output_prefix=test_outputs/binder_test inference.num_designs=10000b) ProteinMPNN-FastRelax进行序列设计,每一个主链结构两个对应的序列,共设计~20000个序列;c) 筛选:使用AlphaFold2预测设计结构,预测的置信度pAE<10,预测结构与设计结构的RMSD<1A,从中挑选95个进行实验验证。2) Nabla Bio开发的JAM(Joint Atomic Modeling)系统3) Chai2 Discovery开发的Chai-2方法,用以实现抗体的从头生成4) MIT开发的Bolzgen方法原理、安装使用讲解。 安装和使用boltzgen讲解,将详细讲解yaml配置文件的写法,以一个靶点为例,从头生成VHH与该靶点结合。5) PPIFlow:基于flow-matching的生成方法,原理,安装和使用方法。1) 确定纳米抗体序列框架(Framework区域)序列,生成CDR区域序列。分析整理纳米抗体序列,绘制序列保守性的Logo图,以此确定在生成VHH时,哪些位置的氨基酸需要固定。2) 对生成的序列进行筛选。在亲和力、序列稳定性、可开发性等各个方面进行筛选。a) 预测结构与设计结构的RMSD,AlphaFold预测设计结构的置信度pAE等
培训聚焦深度学习驱动的抗体设计为核心方向,以David Baker实验室核心设计方法、主流抗体大语言模型、AI抗体结构预测模型为教学核心,秉持理论夯实、实操落地、科研进阶、工程应用的培训原则。依托高性能服务器实操环境,循序渐进讲解行业主流软件、开源模型、代码实操、数据处理与模型调优,搭配十篇顶刊经典文献深度解析,全方位覆盖当下抗体设计领域前沿技术、研究热点与工业落地方案。助力零基础及进阶学员快速打通理论原理、代码实操、模型应用、科研创新全流程,熟练掌握AI抗体设计全套技术栈,可独立完成抗体结构预测、抗体亲和力优化、可开发性改造、抗体从头设计等科研实操任务,适配药物研发、生物工程、合成生物学等科研与工业应用场景。
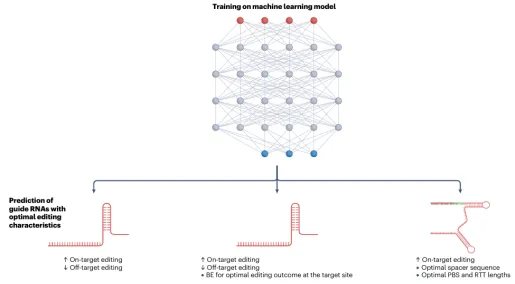
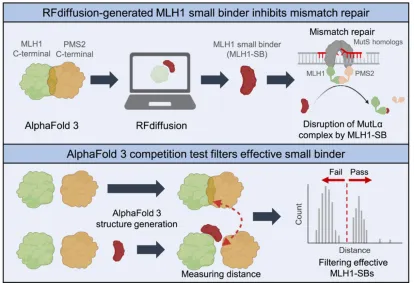
主讲老师在学术界具有多年的研究经历和应用经验,来自于国内顶尖课题组,从事基因组编辑技术与人工智能交叉融合的研究工作,相关工作成果已在Nature Biotechnology、Nature Plants、Trends in Biotechnology等国际知名期刊发表
第一天
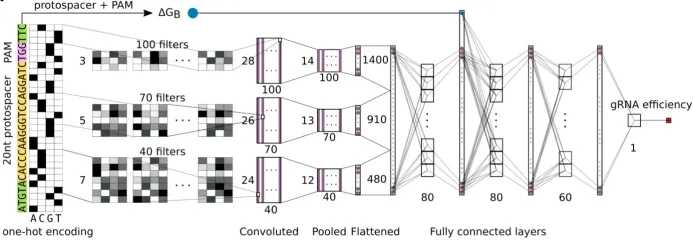
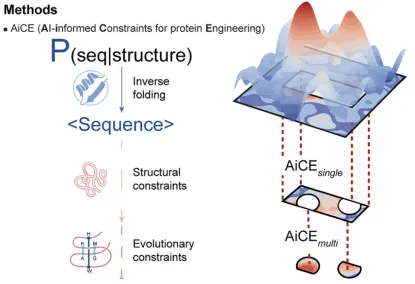
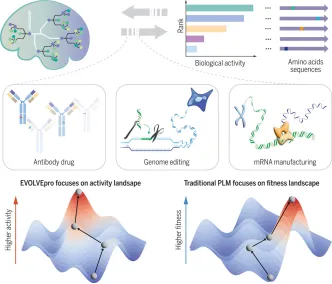
1.1 基因组测序、编辑和读写时代及基因组编辑技术现状简述2.2 ZFN、TALEN和CRISPR/Cas系统的组成和工作原理4. CRISPR/Cas系统介导的DNA编辑工具6. CRISPR/Cas介导的基因调控、细胞成像和核酸检测技术6.1 CRISPR/Cas介导基因调控技术的原理和工具组成6.2 CRISPR/Cas介导细胞成像技术的原理和工具组成6.3 CRISPR/Cas介导核酸检测技术的原理和工具组成1.1 脱靶效应的检测方法:扩增子测序、全基因组测序、GUIDE-seq等3.1 靶位点设计软件Cas-Designer、BE-Designer、PE-Designer等3.2 突变分析软件Cas- Analyzer、BE-Analyzer、PE- Analyzer4.1 基因组编辑技术在基因治疗、免疫学、病毒诊断等方面的应用1.3. 深度学习技术的发展趋势:自监督学习、迁移学习和少样本学习的进展2.2. 零样本预测模型的应用:结构模型、大语言模型、多模态模型、2.3. 少样本预测框架的应用(Design-Build-Test-Learn和Lab-in-the-loop范式)2.1. 配置深度学习环境,安装gRNA活性预测所需的工具2.4. 模型搭建与调试:深度学习模型架构设计(如CNN, RNN)2.5. 模型性能评估:精度、召回率、F1分数等评估指标2.6. gRNA活性预测:实际应用案例演示和预测结果的解读与应用4.3. 逆折叠模型的使用:如何利用AiCE进行高活性突变预测;案例演示与实际操作5. 少样本蛋白质定向进化工具EVOLVEpro实操1. 设计MLH1 binder提高引导编辑编辑(PE)效率1.1. 背景知识:基于RFdiffusion + ProteinMPNN + AlphaFold的binder设计流程1.4. 结构骨架生成:利用RFdiffusion进行结构采样与优化,生成蛋白质结构骨架1.5. 序列设计:基于RFdiffusion生成的结构骨架,进行序列的优化设计1.6.复合体结构预测验证:使用AlphaFold进行binder与目标蛋白复合体的结构预测,验证设计的复合体结构是否符合预期1.7. 结果可视化:使用PyMOL进行结构和设计结果的可视化2.3. 蛋白质设计流程:结合RFdiffusion、ProteinMPNN与AlphaFold设计Cas13抑制剂3.4. 基于ESM语言模型挖掘Cas12家族基因编辑酶4.1. 结构比对的背景知识:结构比对的重要性与应用;比较不同结构比对工具的优缺点4.2. Foldseek系列工具介绍:介绍Foldseek、Foldseek multimer、Folddisco、FoldMason等工具的基本原理和使用4.3. 结构数据库介绍与下载:PDB,AFDB,ESM Atlas4.4. 输入结构准备:准备用于比对的目标蛋白质结构文件4.5. Foldseek网页版使用:演示如何使用Foldseek网页版进行结构比对;讲解如何理解输出结果并进行后续分析4.6. Foldseek本地版使用:本地部署Foldseek并使用命令行工具进行比对4.7. DALI和TM-align工具本地版使用:介绍DALI与TM-align工具本地版的安装与使用4.8. 结构进化树构建:使用FoldMason构建蛋白质结构的进化树
本次培训聚焦基因组编辑技术体系与人工智能辅助基因编辑设计前沿方向,系统讲解CRISPR基因编辑全套技术原理、编辑工具、脱靶检测、实验流程、主流设计分析软件;深入剖析深度学习在gRNA优化、编辑活性预测、编辑酶改造、新型编辑系统挖掘中的核心应用。培训秉持理论扎实、通俗易懂、实操落地、案例复刻、科研进阶的教学理念,依托高性能GPU服务器,手把手完成Linux环境配置、深度学习模型搭建、AI蛋白进化、从头设计、结构比对、新型CRISPR挖掘等高阶实操。结合当下主流AI生成模型、大语言模型、结构比对工具,复刻多篇顶刊经典研究案例,使学员能够完整掌握传统基因编辑+人工智能基因编辑全流程技术栈,具备独立开展基因编辑载体构建、gRNA智能优化、编辑酶定向进化、新型编辑元件挖掘、人工设计结合蛋白等科研能力,适配植物育种、基因治疗、生物医药、分子诊断等科研及工业研发场景。
主讲老师来自浙江大学,主要研发方向为组学算法开发与虚拟细胞建模,以第一作者(含共同)发表高水平期刊会议论文数篇,包括Nature Communications,ISBI等,承担各层次研发课题3项,领导共创开源社区搭建,github star数百,具有丰富的科技成果转化落地经验,讲课一致受到学员高度评价。
第一天| 细胞数据数字化与基础表征
上午:理论讲解(第一、二阶段)第一阶段:细胞数据数字化(Data Representation)核心目标:解决"如何让细胞被AI理解"• 细胞多组学数据的复杂性(RNA、ATAC、Protein、Spatial)• 数据标准化与质量控制的最佳实践• 从原始数据到机器可读结构的核心逻辑配套模型理论:• MultiVI:RNA+ATAC多模态统一表征(重点讲解)• totalVI:RNA+Protein联合编码• MOFA+:多组学因子分析• OmniReg-GPT(新模型,NC2026):DNA序列基础表征,基因组位点识别与表达预测第二阶段:细胞状态建模(State Learning)核心目标:解决"如何识别细胞处于什么状态"• 从"细胞数据"到"细胞状态"的转化逻辑• 潜变量空间的生物学意义• 细胞亚群识别与稀有细胞发现配套模型理论:• scVI/scANVI:单细胞潜变量建模(核心)• β-VAE:解耦表征学习• Contrastive Cell Embedding:对比学习在细胞表征中的应用下午:实操演练(对应上午第一、二阶段理论)实操前置准备:GPU服务器环境适配、Linux与Python环境调试1. Linux 常用命令进阶:细胞数据文件(单细胞RNA、ATAC数据)的批量管理、权限设置、格式转换;2. Python 环境搭建与优化:细胞数据处理相关包(scanpy、torch、scvi-tools)的安装与调试。实操模型讲解(Python代码解析 + GPU服务器上机实操)1. 实操模型1:MultiVI(多模态统一表征)—— 对应第一阶段理论,实现RNA+ATAC数据统一编码,完成数据降噪与批次效应校正,掌握潜变量空间构建方法,理解其作为模型底座的核心作用;2. 实操模型2:scVI(单细胞潜变量建模)—— 对应第一、二阶段理论,基于单细胞RNA数据,完成潜变量建模、细胞聚类初步分析,掌握基础表征模型的训练与评估方法,衔接细胞状态识别的核心需求;3. 实操模型:OmniReg-GPT演示(新模型)—— DNA序列特征提取,基因表达预测,理解基础表征模型在基因组学中的应用,展示Nature Communications论文核心技术。核心目标:解决"细胞在组织中的空间状态"• 空间转录组技术概览(Visium、Stereo-seq、MERFISH)• 空间约束下的细胞状态识别• 组织微环境与细胞通讯配套模型理论:• GraphST:图神经网络空间表征• STAligner:空间转录组跨样本整合• Nicheformer(新模型,2025NM):空间基础模型下午:实操演练(对应上午空间转录组理论)实操前置准备:空间转录组数据预处理与工具包调试1. Python 工具包适配:PyTorch Geometric(图神经网络)、squidpy(空间分析)工具包的安装与调试;2. 数据预处理复习:空间转录组数据格式(Visium、Stereo-seq)的读取与预处理方法。实操模型讲解(Python代码解析 + GPU服务器上机实操)1.实操模型:GraphST实操(空间数据聚类与域识别)—— 基于空间转录组数据,构建空间图网络,完成组织域识别与空间聚类,掌握图神经网络在空间数据中的应用;2. 实操模型:STAligner实操(空间转录组跨样本整合)—— 理解空间转录组的批次效应如何消除,掌握去批次的基本原理与核心方法,理解空间组的建模思路3. 实操模型:Nicheformer实操(空间基础模型)—— 细胞微环境表征,掌握空间基础模型的核心应用,深化细胞状态识别的实操能力。上午:理论讲解(第三、四阶段)第三阶段:细胞调控机制建模(Regulatory Modeling)核心目标:解决"为什么细胞会发生变化"• 细胞调控的底层机制• 从表型识别深入到机制层面• 调控机制建模在药物研发中的核心价值配套模型理论:• GAT:图注意力网络,基因调控网络推理• SCENIC:转录因子调控推断• Gene Regulatory Graph:因果关系建模第四阶段:细胞动态预测(Dynamic Evolution)核心目标:解决"细胞下一步会走向哪里"• 细胞命运轨迹推演的核心逻辑• 动态预测对药物研发(如耐药、复发预测)的重要意义配套模型理论:• CellRank 2:命运概率与轨迹推演• RNA Velocity:转录动力学建模• stVCR(新模型,Nat Methods 2026):空间细胞发育轨迹推断,基于Neural ODE的空间-基因双速度场建模下午:实操演练(对应上午第三、四阶段理论)实操前置准备:图神经网络与动态预测工具包调试1. Python 工具包适配:PyTorch Geometric(图神经网络)、CellRank(动态预测)工具包的安装与调试;2. 数据预处理复习:回顾上午理论相关的基因表达数据、调控关系数据的预处理方法。实操模型讲解(Python代码解析 + GPU服务器上机实操)1.实操模型:SCENIC(调控网络机制推理)—— 对应第三阶段理论,基于基因表达数据,构建基因调控网络,识别关键调控节点,掌握机制推理的核心方法,理解其在药物靶点发现中的应用;2. 实操模型:CellRank 2(命运与轨迹推演)—— 对应第四阶段理论,基于单细胞数据,推演细胞分化轨迹,预测细胞未来状态,掌握动态预测的核心方法,贴合药物研发中耐药、复发预测的需求;3. 实操模型:stVCR实操(新模型)—— 空间轨迹推断,预测细胞分化方向,理解Neural ODE建模空间-基因双速度场的核心原理,展示Nature Methods 2026论文核心技术;上午:理论讲解(第五、六阶段)第五阶段:药物作用建模(Drug Perturbation Modeling)核心目标:解决"药物如何改变细胞命运"• 药物作用于细胞的核心逻辑• 药物扰动建模在药物研发全流程中的应用场景配套模型理论:• ChemCPA:药物剂量-响应建模• scGen:扰动响应生成• CellOT:最优传输扰动预测• scGPT:大模型预测扰动第六阶段:疾病系统建模(Disease System Modeling)核心目标:解决"疾病中细胞网络如何重构"• 疾病状态下细胞网络的变化规律• 疾病系统建模在患者分层、疾病亚型预测中的核心价值配套模型理论:• DeepProg:疾病预后预测• Numbat-multiome:从单细胞多组学数据推断CNV并重建肿瘤系统发育下午:实操演练(对应上午第五、六阶段理论)实操前置准备:药物扰动模型工具包调试1. Python 工具包适配:ChemCPA、scGen等药物扰动相关工具包的安装与调试;2. 数据准备:药物作用相关数据(药物剂量、细胞反应数据)的预处理与导入方法。实操模型讲解(Python代码解析 + GPU服务器上机实操)1. 实操模型:ChemCPA(药物扰动预测)—— 对应第五阶段理论,构建药物扰动模型,预测不同药物剂量的作用效果、联合用药反应,掌握虚拟筛选的核心能力,理解其在药物研发ROI提升中的作用;2. 实操模型:scGen实操(单药扰动响应生成)—— 基于单细胞数据,生成药物扰动后的细胞状态预测,掌握生成式扰动模型的核心方法;3. 实操模型:DeepProg(疾病预后分析)——基于多组学数据和AI模型,分析疾病状态下患者预后进展。上午:理论讲解(第七、八阶段)第七阶段:数字孪生细胞/组织(Digital Twin)核心目标:解决"如何构建可推演虚拟人体局部系统"• 数字孪生技术在细胞、组织层面的应用逻辑• 其在降低药企湿实验成本中的核心价值配套模型理论:• Virtual cell:虚拟细胞总览• DrugCell:药物反应神经网络•PhysiCell(Cell 2026):细胞仿真引擎第八阶段:虚拟临床与药物研发(Virtual Clinical Translation)核心目标:解决"如何直接服务药物研发和临床决策"• 虚拟临床试验的设计逻辑• 从体外到体内的预测链条• ROI计算与决策支持配套模型理论:• PK/PD Neural Surrogate:药代动力学神经网络• Clinical Response Simulator:临床响应模拟下午:实操演练+ 课程总结实操前置准备:数字孪生与虚拟临床模型工具包调试1. Python 工具包适配:DrugCell、PhysiCell等数字孪生相关工具包的安装与调试。实操模型讲解(Python代码解析 + GPU服务器上机实操)1. 实操模型:DrugCell(产业级药物反应预测)—— 对应第七阶段理论,构建药物反应预测模型,解释药物作用机制,掌握产业级模型的应用方法,理解其在降低湿实验成本中的作用;2. 实操模型:PhysiCell(数字孪生底层仿真)—— 对应第七阶段理论,搭建虚拟细胞仿真环境,完成从虚拟细胞到虚拟组织的仿真闭环,掌握数字孪生底层操作,衔接虚拟临床应用;• 技术栈回顾:从数据→状态→调控→动态→药物→疾病→孪生→临床• 前沿趋势:大模型、多模态、空间组学、虚拟敲除• 职业发展:计算生物学人才需求与能力路径配套资源
• 课程PPT(理论讲解)• 实操代码包(Jupyter Notebook)• GPU服务器账号(云端实操)• 数据集(公开单细胞/空间数据)• 参考文献(最新顶刊论文,基本是2026、2025新文章+少量经典文章)
AI蛋白质设计设计授课时间
2026.6.6-2026.6.7(09:00-11:30--13:30-17:00)2026.6.10-2026.6.11(19:00-22:00)2026.6.13-2026.6.14(09:00-11:30--13:30-17:00)2026.6.16-2026.6.17(19:00-22:00)共计6天的课 通过腾讯会议直播 线上实操 提供全部录播
2026.7.04-2026.7.05(09:00-11:30--13:30-17:00)
2026.7.7-2026.7.8(19:00-22:00)
2026.7.11-2026.7.12(09:00-11:30--13:30-17:00)
共计5天的课 通过腾讯会议直播 线上实操 提供全部录播
AI抗体设计授课时间
2026.6.23-2026.6.26(19:00-22:00)2026.6.27-2026.6.28(09:00-11:30--13:30-17:00)2026.6.29-2026.6.30(19:00-22:00)共计5天的课 通过腾讯会议直播 线上实操 提供全部录播
2026.6.23-2026.6.26(19:00-22:00)2026.6.27-2026.6.28(09:00-11:30--13:30-17:00)2026.6.29-2026.6.30(19:00-22:00)共计5天的课 通过腾讯会议直播 线上实操 提供全部录播
AI构建虚拟细胞授课时间
2026.6.23-2026.6.26晚上(19:00-22:00)
2026.6.27-2026.6.28白天(09:00-11:30--13:30-17:00)2026.6.29-2026.6.30晚上(19:00-22:00) 共计5天的课 通过腾讯会议直播 线上实操 提供全部录播
课程报名费用:
AI多肽设计、AI蛋白质设计、AI基因编辑、AI抗体设计、AI构建虚拟细胞:公费价:每人每班¥6880元 (含报名费、培训费、资料费、提供课后全程回放资料)
自费价:每人每班¥6580元 (含报名费、培训费、资料费、提供课后全程回放资料)
重磅优惠:
报二送一(同时报名两个班免费赠送一个学习名额赠送班任选)
优惠1:
两班同报:10880元 (可学习三个直播课)
三班同报:14880元
四班同报:18880元
特惠一:24880元 (可免费学习一整年本单位举办的任意课程)
特惠二:28880元(可免费学习两整年本单位举办的任意课程)
优惠2:提前报名缴费可享受300元优惠(仅限十五名)
报名学习课程可赠送往期课程回放(报多少赠多少)
(可点击跳转详情链接):
回放一:本课程为视频课!机器学习生物医学培训!
回放二:本课程为视频课!单细胞空间转录组培训!
回放三:本课程为视频课!比较基因组学培训!
回放四:本课程为视频课!机器学习蛋白质组学培训
回放五:本课程为视频课!机器学习微生物组学培训
回放六:本课程为视频课!蛋白质晶体结构解析培训
回放七:本课程为视频课!CRISPR-Cas9基因编辑培训
回放八:本课程为视频课!机器学习代谢组学培训!
回放九:本课程为视频课!深度学习基因组学培训!
1、课程特色--全面的课程技术应用、原理流程、实例联系全贯穿
2、学习模式--理论知识与上机操作相结合,让零基础学员快速熟练掌握
3、课程服务答疑--主讲老师将为您实际工作中遇到的问题提供专业解答
授课方式:通过腾讯会议线上直播,理论+实操的授课模式,老师手把手带着操作,从零基础开始讲解,电子PPT和教程开课前一周提前发送给学员,所有培训使用软件都会发送给学员,有什么疑问采取开麦共享屏幕和微信群解疑,学员和老师交流、学员与学员交流,培训完毕后老师长期解疑,培训群不解散,往期培训学员对于培训质量和授课方式一致评价极高!
腾讯会议实时直播解答|手把手带着操作

![]()
电子邮箱:m15238680799@163.com
发现真的是脚踏实地的同时 需要偶尔仰望星空非常感谢各位对我们培训的认可!祝愿各位心想事成
转载说明:本文系转载内容,版权归原作者及原出处所有。转载目的在于传递更多行业信息,文章观点仅代表原作者本人,与本平台立场无关。若涉及作品版权问题,请原作者或相关权利人及时与本平台联系,我们将在第一时间核实后移除相关内容。
 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库