刚刚,小扎的千亿闭源AI终于交卷!当场被痛批「图表犯罪」,28岁话事人火速道歉
发布时间:2026-04-08来源:APPSO
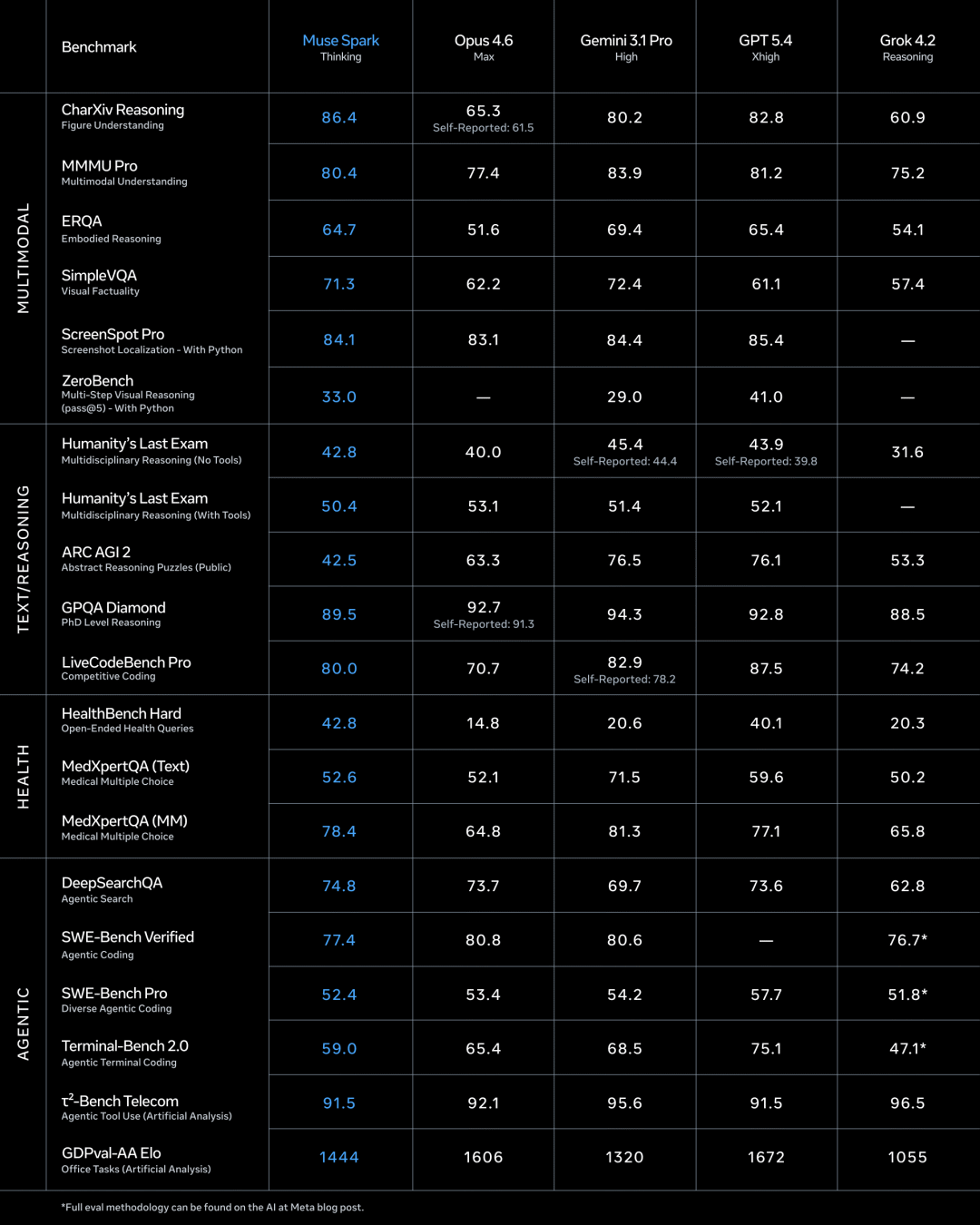
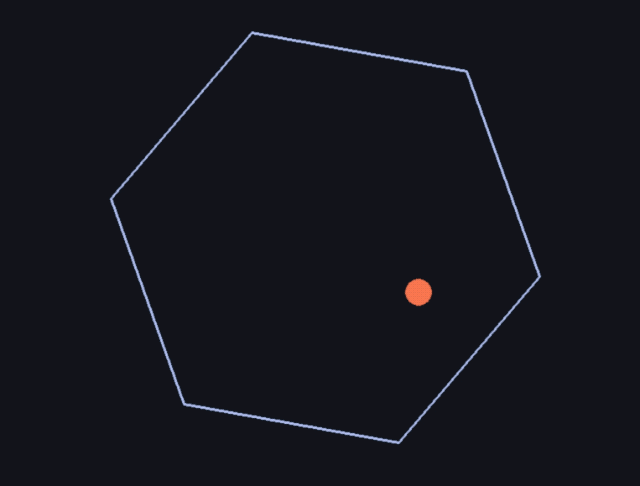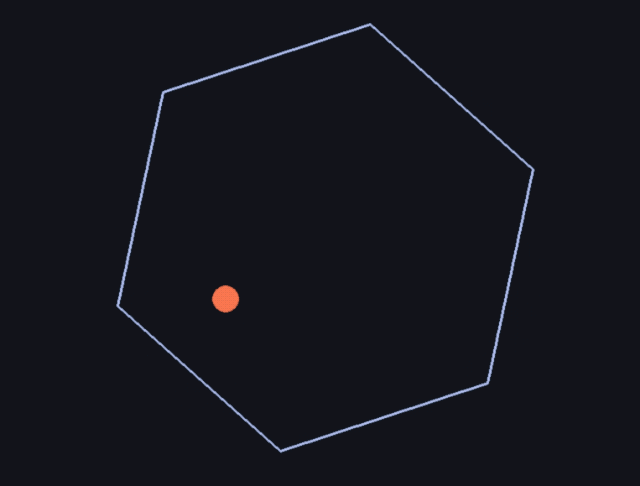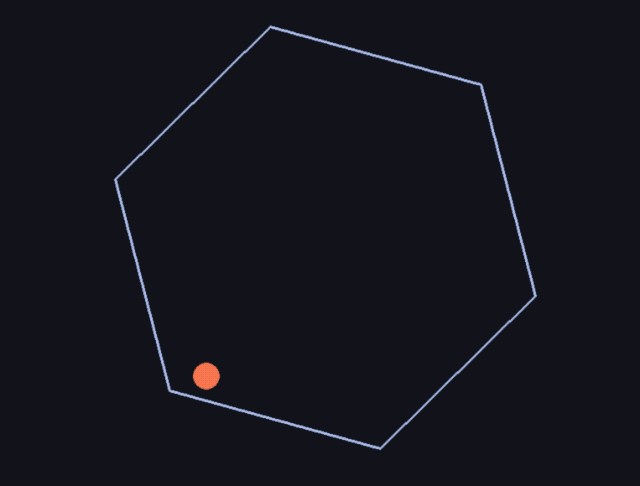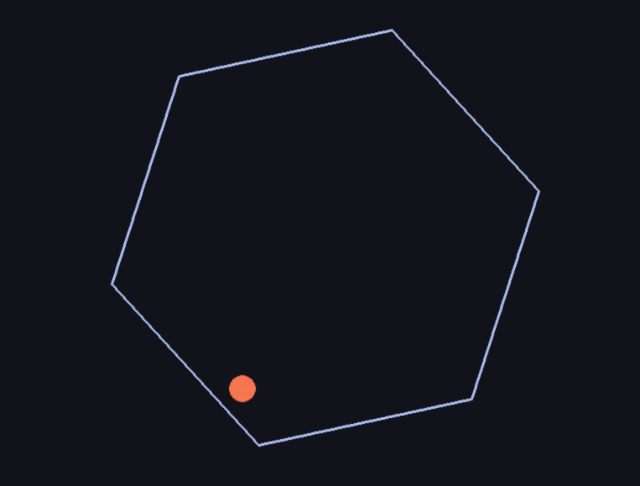
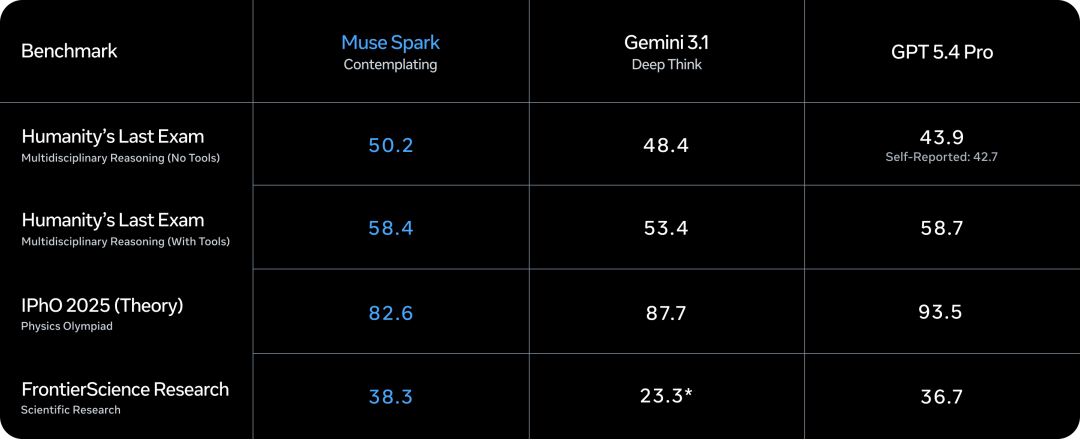
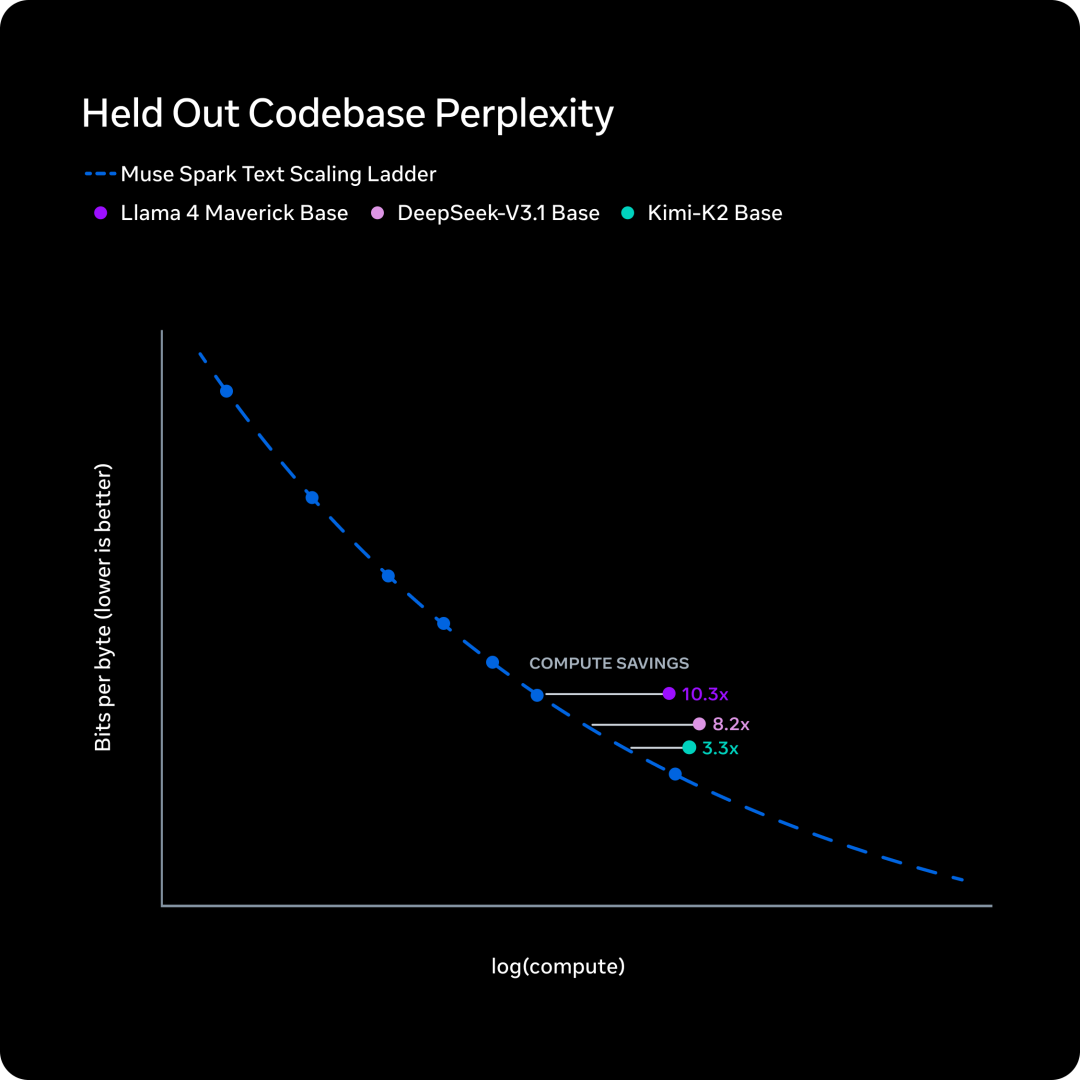
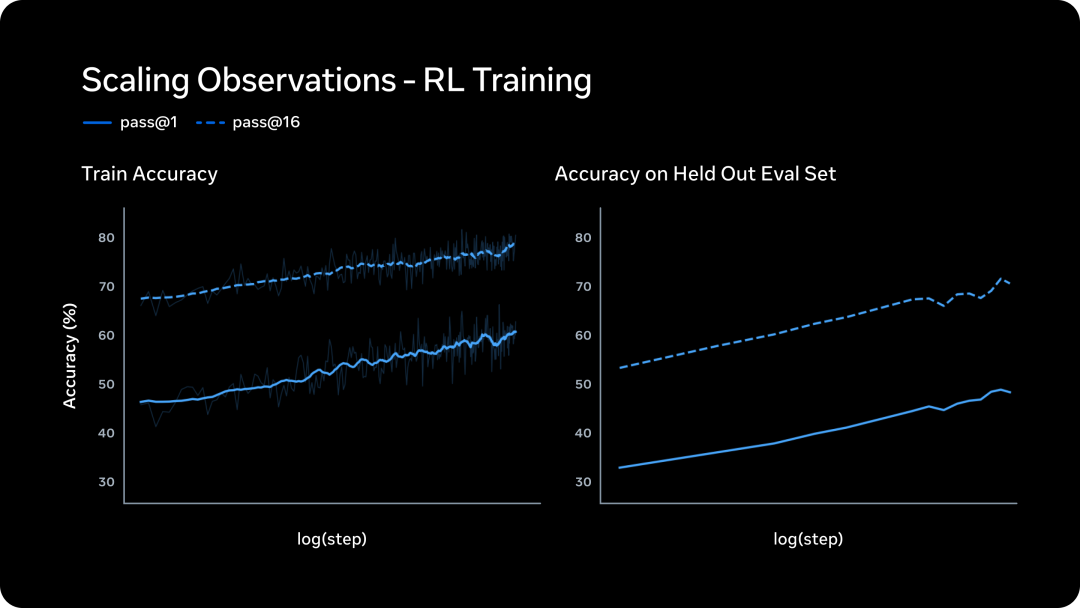
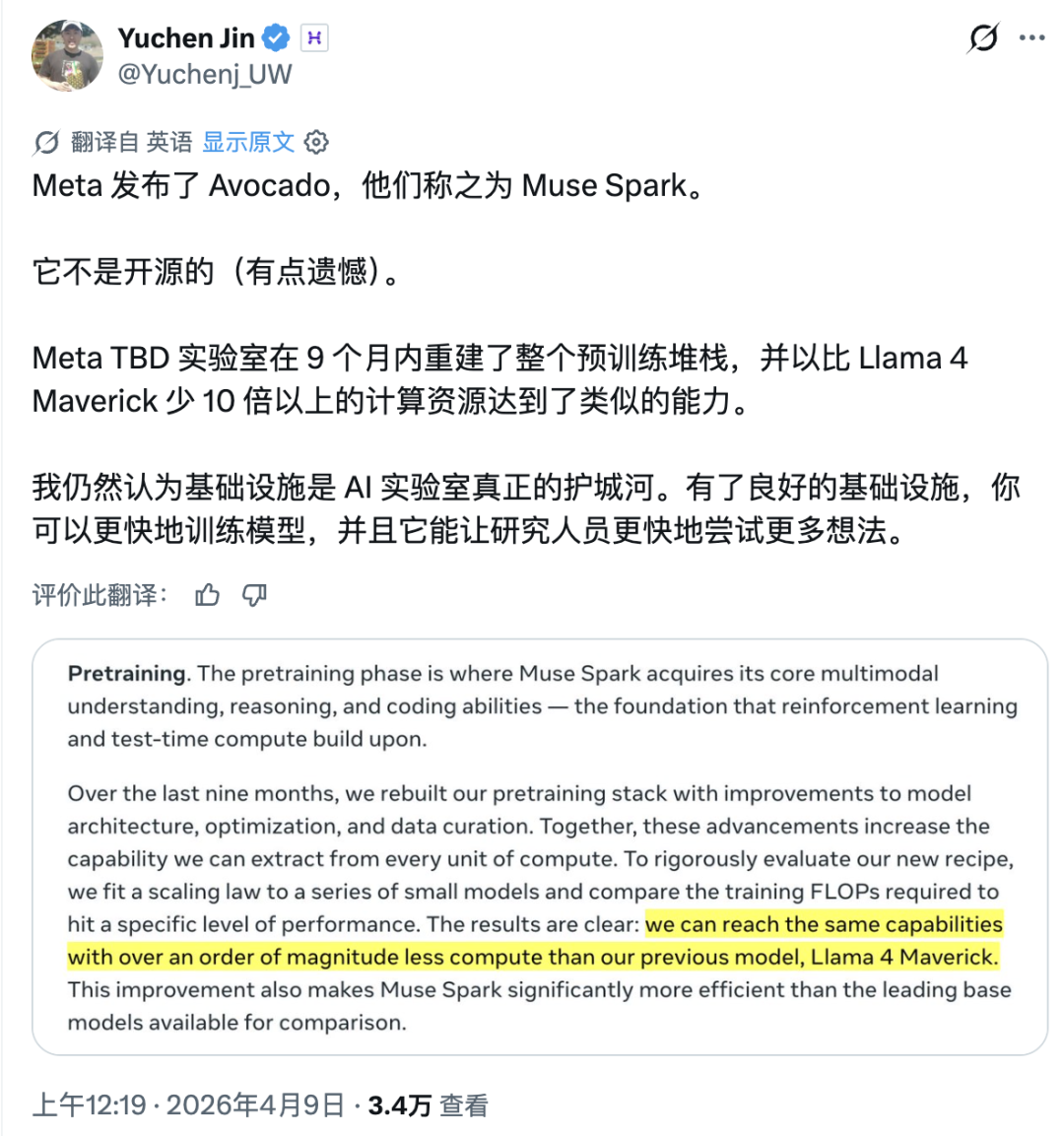
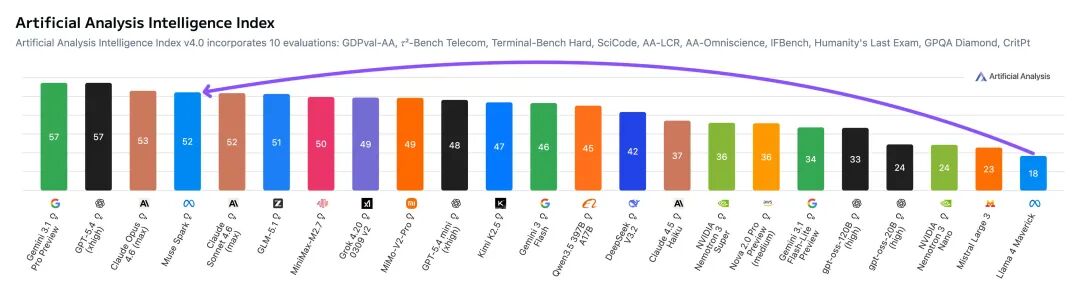
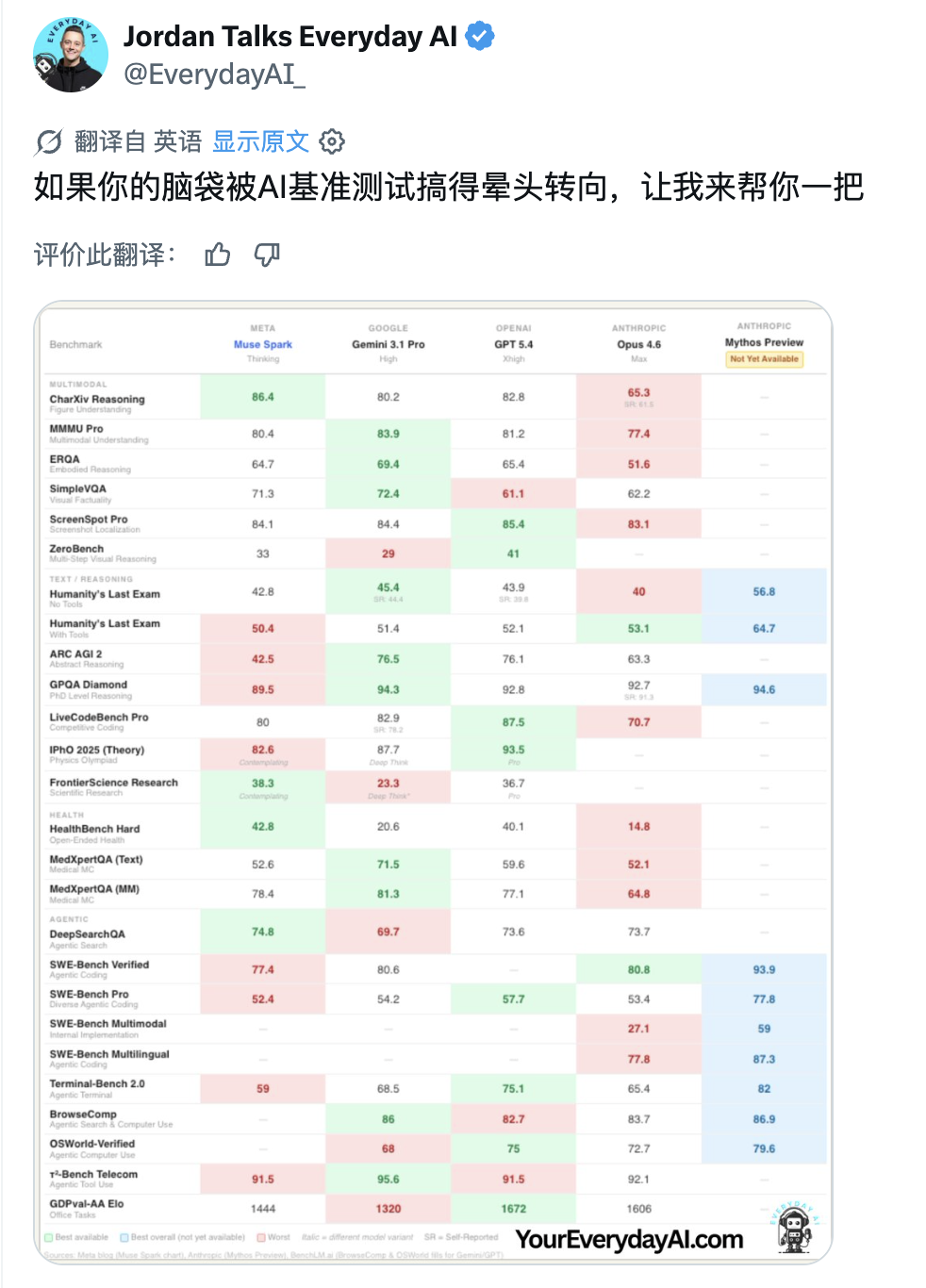
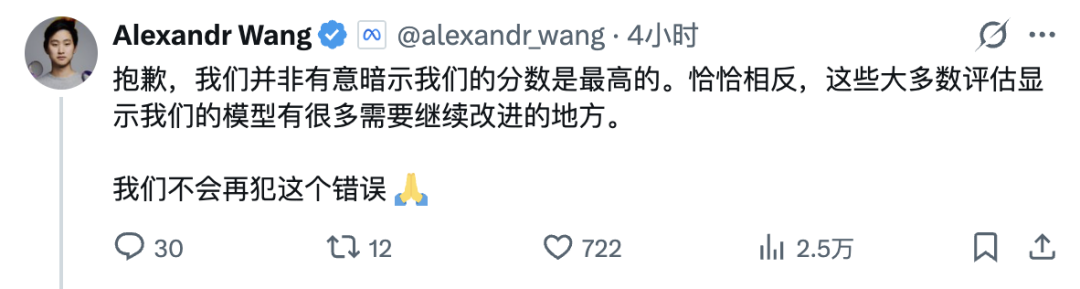
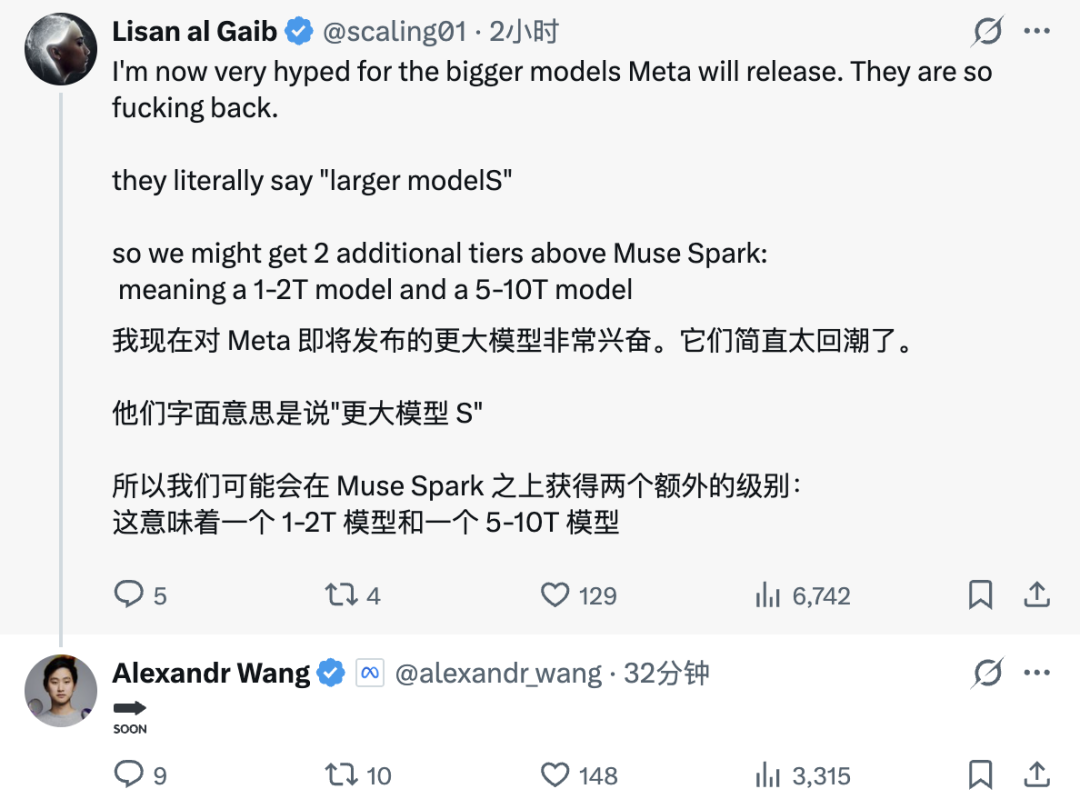
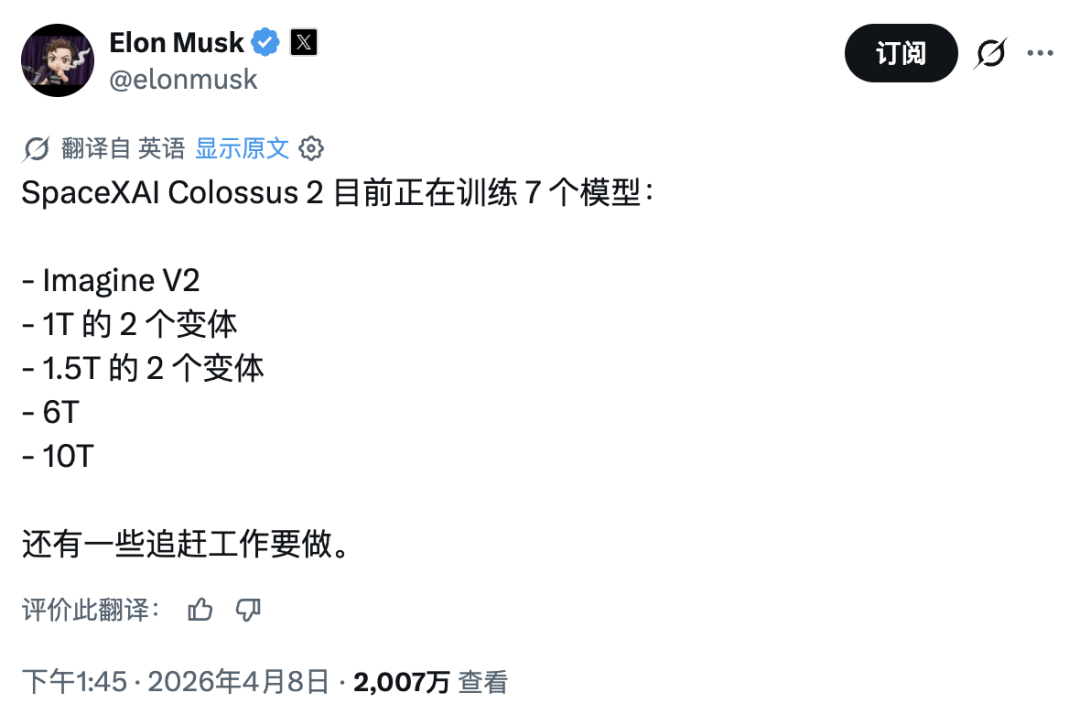
九个月前,如果你问 AI 圈里谁最焦虑,答案大概率是 Meta CEO 扎克伯格。Llama 4 的发布堪称教科书级翻车。核心研究员陆续出走,技术社区的口碑几乎在一夜之间崩掉,于是扎克伯格选择推倒重来。Meta Superintelligence Labs 挂牌成立,接着小扎开出堪比 NBA 职业球星的签约金,从 OpenAI、Google、Anthropic 撬走七十多名顶尖研究员,并在六个月内完成了四次组织架构调整。就在刚刚,这场 AI 豪赌终于亮出了它的第一张牌:Muse Spark。近千亿美元的支出给了扎克伯格一张 AI 顶级玩家的入场券,但入场从来只是开始,能不能在这张桌子上赢下去,还要看今天这张牌打得怎么样。号称「个人超级智能」第一步,Muse Spark 登场作为 Meta Superintelligence Labs 推出的 Muse 系列首款模型,Muse Spark 从架构层面原生支持图像、音频、视频与文本的联合理解,内置工具调用、可视化思维链与多智能体协调能力。Meta 将其定位为迈向「个人超级智能」的第一步。从评测数据看,Muse Spark 的能力分布相当不均匀。多模态方向上,它在 CharXiv Reasoning 图表理解项目上得分 86.4,超过 GPT 5.4 的 82.8 和 Gemini 3.1 Pro 的 80.2,SimpleVQA 视觉事实题同样领先竞争对手。但在 MMMU Pro 多模态理解项目上,Muse Spark 得分 80.4,低于 Gemini 3.1 Pro 的 83.9。文本推理方向,它在 GPQA Diamond 博士级推理题上得分 89.5,LiveCodeBench Pro 竞争编程测试得分 80.0,后者超过 Opus 4.6。然而 ARC AGI 2 抽象推理谜题上仅得 42.5,远落后于 Gemini 3.1 Pro 的 76.5 和 GPT 5.4 的 76.1,差距颇为明显。HealthBench Hard 开放式健康问答中,Muse Spark 得分 42.8,远超 GPT 5.4 的 40.1、Gemini 3.1 Pro 的 20.6 和 Opus 4.6 的 14.8。MedXpertQA 多模态医疗题得分 78.4,Meta 与超过 1000 名医生合作标注训练数据,这一投入在评测榜单上得到了直接回报,也是少见的、钱花到了刀刃上的地方。编码与智能体任务则是另一面。Muse Spark 在 DeepSearchQA 智能体搜索项目上得分 74.8,优于 Gemini 3.1 Pro 的 69.7,但在 Terminal-Bench 2.0 终端编码任务上仅得 59.0,落后于 GPT 5.4 的 75.1 和 Gemini 3.1 Pro 的 68.5。基准测试之外,社区的实战对比更为直观:有用户同时让 Muse Spark 和 GPT-5.4 完成「制作一个 Flappy Bird 克隆版」的任务,从游戏逻辑到交互细节,GPT-5.4 轻松胜出。在经典的六边形小球测试中,对比昨天 DeepSeek 专家模式的表现,Muse Spark 再次败下阵来。只能说,编码与长链路智能体任务,仍是 Meta 明确承认、尚在补强的方向。与标准推理模式并行,Meta 同步推出了 Contemplating 模式,通过并行调度多个 AI 智能体协作处理复杂问题。该模式在「人类最后的考试」(Humanity’s Last Exam)无工具版本中得分 50.2,超过 Gemini 3.1 Deep Think 的 48.4 和 GPT 5.4 Pro 的 43.9,FrontierScience Research 科学研究任务中得分 38.3。但在物理奥赛 IPhO 2025 理论题上得分 82.6,仍落后于 GPT 5.4 Pro 的 93.5。支撑上述能力的,是 MSL 过去九个月彻底重建的技术栈。Codebase Perplexity 测试图表显示,Muse Spark 在相同性能水平下,比 Llama 4 Maverick Base 节省 10.3 倍算力,比 DeepSeek-V3.1 Base 节省 8.2 倍,比 Kimi-K2 Base 节省 3.3 倍。强化学习阶段同样表现稳定,pass@1 从约 46% 持续爬升至超 60%,pass@16 从 近 68% 升至近 80%,在未见过的评测集上泛化趋势同样平稳。博主 Yuchen Jin 评价称,基础设施才是 AI 实验室真正的护城河,好的基础设施让研究人员能以更快速度训练模型、用更短周期验证更多想法。AI 评测机构 Artificial Analysis 在早期测试后表示,Muse Spark 在其综合智能指数中得分 52,位列全球前五。Muse Spark 现已上线 及 Meta AI 应用,并向部分用户开放 API 内测,用户须以 Facebook 或 Instagram 账号登录方可使用。与此前开源 Llama 系列的路线不同,Meta 这次选择闭源发布。Meta 未明确说明是否会使用社交账号中的个人信息训练模型,但鉴于 Meta 的一贯做法,这一可能性不低,其中健康数据的采集更是值得特别关注。2025 年 4 月,Llama 4 以令人失望的表现触发了 Meta 的人事地震。下定决心从头来过的扎克伯格,成立了 Meta Superintelligence Labs,以 143 亿美元将 Scale AI 创始人 Alexandr Wang 引入担任首席 AI 官,前 GitHub CEO Nat Friedman 负责产品,前 OpenAI 研究员 Shengjia Zhao(赵晟佳)出任首席科学家。紧接着是四大团队的重组、以及从 OpenAI、DeepMind、Anthropic 等对手处累计引进逾 70 名顶尖研究人员,单人签约奖金最高达 1 亿美元。代价是沉重的,图灵奖得主 Yann LeCun 离职、600 个岗位被裁、内部薪酬不公引发大规模士气危机,六个月内四次架构调整更是让团队方向感严重缺失。结果显而易见,九个月重建、数百亿投入,Muse Spark 交出的这份答卷,称得上合格,却还远远谈不上亮眼。有一个有趣的细节是,Meta 在评测图表中,通过给自家模型基准测试成绩高亮的操作,试图制造出全面领先的视觉观感,随即引发外界批评。网友 Armen Aghajanyan 直接定性为「图表犯罪」,Alexandr Wang 随后公开致歉,承认大多数评估恰恰显示模型有很多需要改进的地方。事实上,Meta 新模型在健康领域的垂直优势足够亮眼,算力效率的提升也确有真实价值,但 ARC AGI 2 上的断崖式落差、编码任务上被 GPT-5.4 轻松超越,以及「图表犯罪」风波所折射出的叙事焦虑,共同勾勒出一个仍在追赶、而非遥遥领先的 Meta AI。更关键的是,这是一份闭源答卷。Meta 曾以开源 Llama 系列树立起差异化形象,如今转向闭源商业化路线,意味着它放弃了社区生态这张最重要的底牌,却尚未证明自己能在闭源赛道上与 OpenAI 和 Anthropic 正面掰手腕。如官方博客和 Alex 回应所说,别问,问就是「大的要来了」甚至就在 Muse Spark 发布的同一天,马斯克在社交媒体上晒出 xAI Colossus 2 的训练进度,七个模型同时在训,参数规模从 1T 横跨至 10T,并附上一句意味深长的「还有些追赶要做」。同期,Claude Mythos 预览版、DeepSeek 新一轮更新也已经发布,包括阿里即将推出 Qwen-3.6 系列旗舰 Qwen-3.6-Max,腾讯混元 3.0 同样蓄势待发。对手们不会等 Meta 考完再出题,并且投资者的耐心本来就是有限度的。四月,依旧是最残酷的一个月。名为 AGI 的这场考试,目前还看不到阅卷结束的那一天。
✉️ 邮件标题「姓名+岗位名称」(请随简历附上项目/作品或相关链接)
转载说明:本文系转载内容,版权归原作者及原出处所有。转载目的在于传递更多行业信息,文章观点仅代表原作者本人,与本平台立场无关。若涉及作品版权问题,请原作者或相关权利人及时与本平台联系,我们将在第一时间核实后移除相关内容。
 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库