 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库报道了几年 AI,我越来越觉得自己是个骗子……
太疯狂了,这大概是 APPSO 报道 AI 以来经历过更新最为密集的一个月。
在给大家介绍完一众新模型后,今天这篇文章,想和你聊聊对AI 行业的发布周期所产生的「超现实」现象。
在车轮滚滚的周期中,AI 媒体们,包括 APPSO 自己,也成为了「共谋」。归根结底,在其位谋其事,潮水的方向难以抵抗。但我们发现越来越多人都有类似的感受,所以本文也算是一种自省。
事情要从 Opus 4.7 说起。
只看大部分单项基准测试分数的话,你会以为 Anthropic 再次抬高了大模型的上限。但是在发布之后,真正用上 Opus 4.7 的用户感觉并非如此。Token 耗费变得比前代更加夸张,上下文能力和编码场景下的工具调用能力都有所倒退。
在使用了一段时间后,一些开发者切回了 Opus 4.6。Pragmatic Engineer 作者 Gergely Orosz 表示这个新模型「像是在跟我作对」。「Opus 4.7 是一次严重的倒退,而非升级。」很多开发者都表示了类似的观点。Business Insider 报道,吐槽 Opus 4.7 的推文获得了数万次点赞。
基准测试的结果,是对 Opus 4.7 的描述;用户实感,同样是对 Opus 4.7 的描述。然而两者之间,有着天壤之别。
这种区别,指向了一个笼罩在整个 AI 行业的文化现象,也即:
AI 行业,特别是以 Anthropic、OpenAI 为代表的公司,它们尽力维持着一种模型/AI 产品发布周期 (launch cycles),每隔几个月甚至几周就有大版本发布,每天都有新功能推出。
然而,这种车轮滚滚的发布周期,有如左脚踩右脚一般,已然形成了一种自我维系的新经济模式。「发布」这件事本身,以及围绕这些发布所撰写的营销物料和媒体报道,足以塑造、固化人们对于 AI 进步的认知,并且引发真实的财务后果(关联公司的股价涨跌)。
也就是说,AI 在认知意义上的进步,已经先于真实体验上的进步,甚至在很大程度上完全替代了后者。
发布取代了体验,炒作成为了现实。

鲍德里亚与 AI 行业的超现实
在《黑客帝国》的主要角色进组开拍之前,主创沃卓斯基姐妹曾经强制要求他们阅读法国哲学家让·鲍德里亚的《拟象与模拟》(Simulacres et Simulation) 一书。
文化评论界普遍认为,《黑客帝国》是流行文化作品对鲍德里亚的思维框架的绝佳演绎:大部分人接受了虚构的幻象,只有少数人「人间清醒」。在 Cypher 这个角色的身上,你会看到有人更偏好美好的幻象,而非艰难的现实。
而《黑客帝国》三部曲的主角们,选择的是红药丸,是无论战胜母体的可能性有多么的渺茫,都要回到并且重新掌握自己的现实,掌控自己的主体性。
讽刺的是,在 2003 年,法国杂志《新观察家》采访了鲍德里亚本人对《黑客帝国》的看法,他是这么说的:
《黑客帝国》绝对是「母体」本身会制作出来的那种关于「母体」的电影。
翻译一下鲍德里亚的这句话,他其实是在吐槽《黑客帝国》流于「战胜强敌,重掌自我」的流行文化俗套。他并不认为《黑客帝国》领悟了自己提出的理念的精髓。
正相反,鲍德里亚认为,「现象」的扭曲力场已经如此之强,以至于现象与现实已经不存在实质性的区别——现象早已取代了现实。

一家饭馆的菜单,成为了饭馆的具象代表,然而你仅从菜单上是品尝不出这家餐馆的口味的;人们从一张平面的世界地图中形成对于不同国家疆域大小的认知,但当二维的比例尺切换到真实世界中却并不精确,甚至差之千里。
现实当然是存在的,只是在现象先行的时代,它逐渐变得无足轻重了。
回到本文的主题:AI 模型和产品的发布周期,你会发现一切正是按照鲍德里亚所预言的「超现实」(hyperreality) 那样,正在发生。
环绕在最新的 AI 模型周围的配套体系,已然发展地如此迅猛,变得无比庞大和厚重,具备了强大而难以撼动的自我维持能力,以至于新闻稿、基准测试分数、媒体报道……等等的「外围」,已经变成了 AI 本身,足以塑造人们对于 AI 的认知;用户对于模型/产品的真实体验,反而变成了无足轻重的次要因素。
今时今日,AI 新品的发布,并没有真的揭晓产品。而是发布的行为本身塑造了某种叙事,造成了某种现象。而这些叙事、现象,取代了真实体验 (lived experience)。
发布本身,就是「产品」。

Opus 4.7、Gemini、Sora
在 Opus 4.7 发布的同一周,Figma 的股价一共暴跌了三次。
按照时间倒序:最后一次是 Claude Design 发布;中间是 Opus 4.7 发布;而第一次,是在 4 月 14 日,Opus 4.7 发布的两天前。
当天,The Information 独家报道了 Anthropic 准备在当周发布 Opus 4.7 模型以及设计工具的消息。

在 4 月 14 日哪一天,股价下跌的不止 Figma:Adobe、Wix、GoDaddy 等一众公司都有损伤——数十亿美元的市值蒸发,仅因为一家权威媒体报道了一个对于外界并不真正存在的、无法被切实感知到的产品。
如果说当今的 AI 行业已经完全沦为一个现象领先于现实的「超现实」,The Information 这篇报道所引发的股票抛售恐慌就是绝佳的例证。
随后,Opus 4.7 正式发布。Anthropic 宣称它是有史以来最强大的 Opus 模型,并提供了一系列基准测试分数来作证:SWE-bench Verified 从 80.8% 提升到 87.6%,CursorBench 从 58% 到 70%。
在发布的那一瞬间,人们无比兴奋,因为这个有史以来最强大的 Opus 模型,不仅看起来是毫无争议的进步,而且居然加量不加价,仍然是 $5/25 每百万输入/输出 token。
过了一段时间,真实用户体验如潮水般涌来,一切都变了。
用户们发现,Opus 4.7 在很多特定任务上「降智」情况显著。比如开发者和博主 Theo Browne 发现,即便在 Anthropic 官方推出的 Claude 桌面端中,使用 Anthropic 官方的 harness 来编排 Opus 4.7 执行代码类任务,它仍然会表现地很蠢,例如找不到 Node.js 的最新版、无视官方的系统提示词等等。
再比如,Opus 4.7 在多轮上下文寻回基准测试 (MCMR) 中的分数,连前代 Opus 4.6 的一半水平都达不到。这个基准测试所对应的上下文寻回能力,对于 Anthropic 主打的核心行业用户,包括法律、金融等等行业来说可能会有显著影响,他们真的需要在百万级的超长上下文窗口下工作。
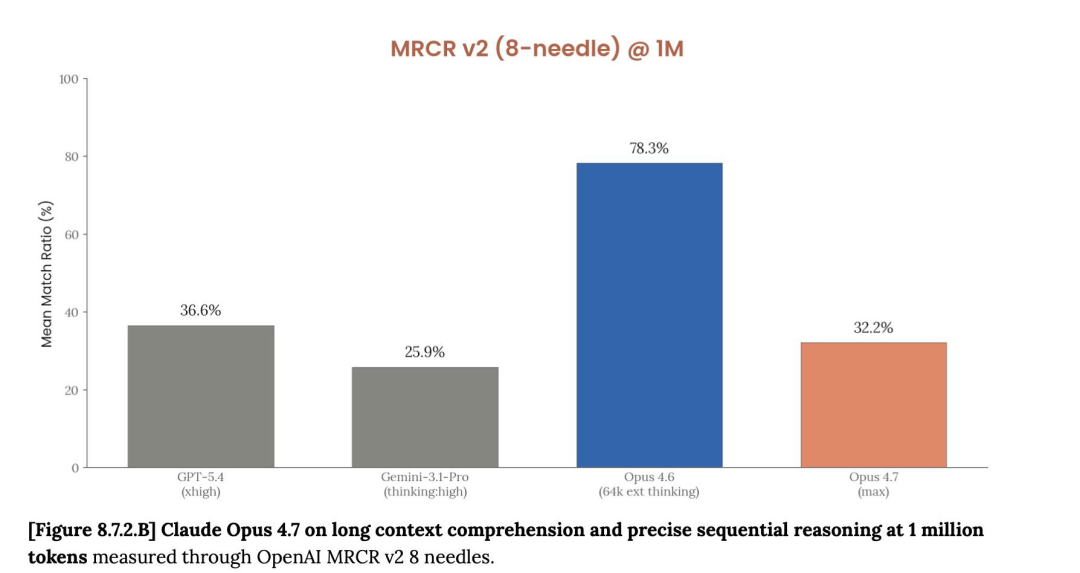
Claude Code 主创 Boris Cherny 亲自下场,宣称 MCMR 是一个糟糕、过气的基准测试,以后都会用 GraphWalk 来作为上下文测试的基准。
Cherny 的解释并没多少说服力。他说 MCMR 没有现实意义,但人们同样可以说 GraphWalk,一个通过十六进制哈希值来评价图遍历性能的测试,跟 MCMR 没有区别,都没什么现实意义,都是「海底捞针」式的测试任务。

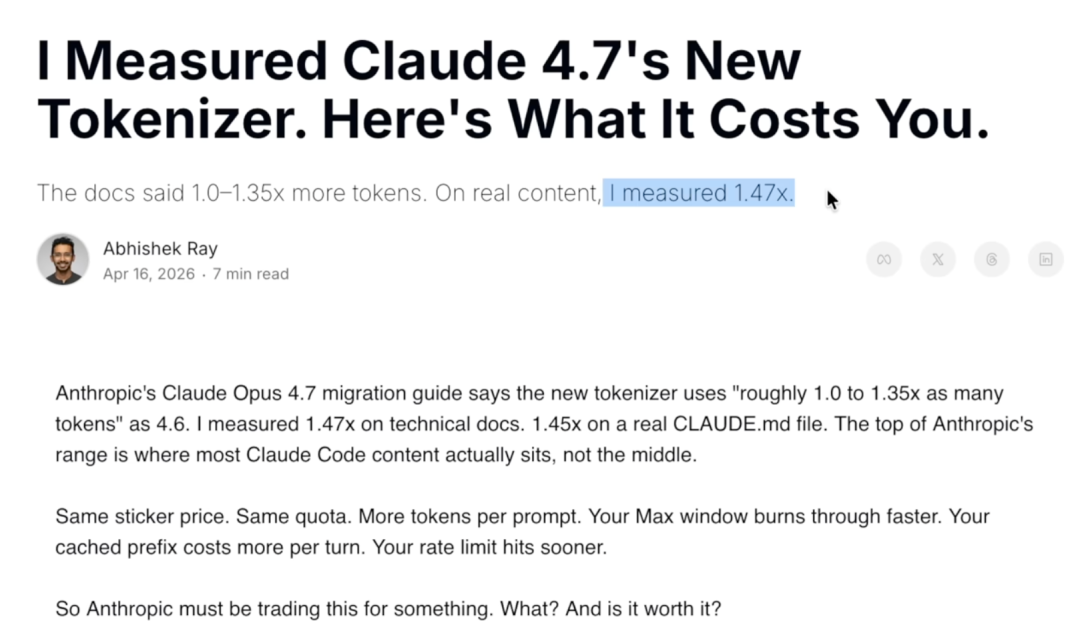
Opus 4.7 采用的新分词器也带来了新的负提升,可能导致输入、输出前的思考过程的额外消耗,提升最高 35%。在新模型发布后的一天内,有企业用户反映在此前相同的任务上使用 Opus 4.7 在 Claude 上运行任务,比 4.6 提前 30%-80% 达到 5 小时限额。
开发者 Abhishek Ray 对 Opus 4.7 的新分词器做了深入测试,发现在阅读文档(比如 CLAUDE.md)的消耗能够达到 4.6 的 1.45-1.47 倍。
而 Anthropic 官方说的 0 到35% token 增加,会让你以为真实场景会在这个区间内浮动——然而实际上,在真实场景里,额外的耗费比 Anthropic 的「上限」还要高。
Anthropic 的应对策略是什么呢?还是派出了 Boris Cherney,去 X 上口头宣布:我们为所有用户提高了限额!
当事实跟叙事对不上的时候,Anthropic 会忽略事实、改变叙事。这就好比一个封建领主打仗失了地,他不想着争回来,反而把地图给改了,然后告诉你「我的王国从来都是这么大」。
在 Opus 4.7 的官方基准跑分表上,还有另一行数字属于 Mythos 模型:SWE-Bench Verified 高达 93.9%,GPQA Diamond 高达 94.6,CyberGYM 高达 83.1%——几乎全方位超越 Opus 4.7。
Mythos 是在 Opus 4.7 之前「发布」的,然而这次「发布」远比 Anthropic 做过的任何一次发布都更加匪夷所思:
普通用户是没有办法在发布的同一天用上 Mythos 的,A 社只是宣布了有这个史无前例版强大的模型的存在,只有不超过 50 个公司认可的合作伙伴可以第一时间用上。A 社还说,没有在近期将 Mythos 公开放出的计划。
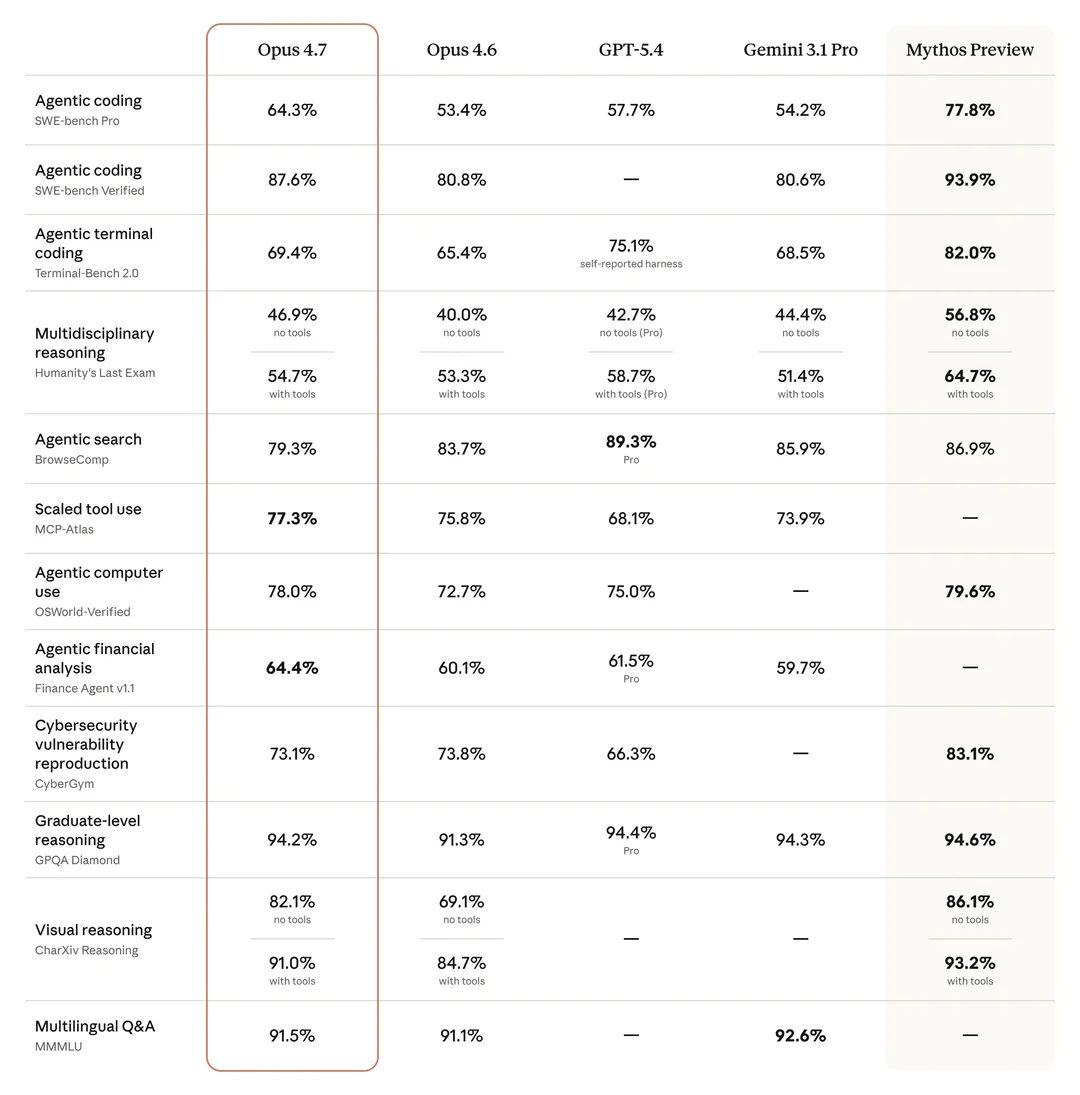
Mythos 存在吗?存在,也不存在,它只存在于 Anthropic 官方的服务器上,存在于这些被 A 社官方认证的「合作伙伴」的体验当中。
但是这并不妨碍网红博主和 AI 媒体们对其发表各种溢美之词:一个将会彻底革命千行百业的大模型,一个秒杀一切其它模型的「最后的大模型」……
Mythos 是那个号称强大到以至于世界上 99.999% 的人都不配使用的模型。
然而对于普通人来说,它迄今为止唯一的真实意义,就是塑造 Anthropic 乃至于整个 AI 行业将会彻底重塑这个世界的认知。
但 Anthropic 并不是第一家这么做的公司。
2023 年底,Google 发布了一条展示 Gemini 多模态的宣传视频。在这条视频里,Gemini 能够对摄像头拍到的画面进行实时的视觉理解,它能看懂用户手绘涂鸦的内容,能在用户玩游戏的时候进行实时解说,甚至能猜中用户在玩的「空壳游戏」(几个杯子一个球,猜球藏在哪个杯子里)。它的语音效果温暖而富有人味——在 2023 年的时候惊为天人。
Google CEO Sundar Pichai 也转发了这条视频,在 YouTube 上的播放量一天内破了百万。科技媒体纷纷撰写了报道,盛赞 AI 的进步已然突破了文本对话本身,在获得多模态能力后真正进入真实世界并带来深远影响。

这个被营造出来的认知,在仅仅 2 天后就轰然塌房。
在彭博社和 TechCrunch 的记者逼问下,Google 交代了实情:视频中 Gemini 所谓的实时对话,其实是静态图片和提示词一条一条喂进去后生成的回应。不仅 Gemini 产品在当时做不到实时对话,就连 Google DeepMind 团队自己都无法在内部实现。这个 demo 本身就是假的。
真相曝光后,Google 仍在嘴硬。一位公司公关表示,这条视频是「Gemini 可能性的演绎」。但我们都明白潜台词是什么意思,就像《盗梦空间》里的「植梦」那样,科技行业通过这样的营销行为,在用户的心智中种下种子,让它生根发芽,枝繁叶茂,开花结果。
当然,在今天,低延迟的对话功能和多模态识别能力早已被 Gemini 们实现。但事件发生的顺序仍然重要:Google 先结了果,才去种的因。
这条视频后来被 Google 删除了。但在被证伪之前,已经有上百万人看过了视频,参与了这场倒果为因的表演——有多少人今天还记得当时 Gemini 团队做了这件事?真相是什么,已经不重要了。
类似的事情也发生在早期的 Sora 身上。
2024 年 2 月,OpenAI 展示了这个当时还在训练中的视频生成模型,赛博朋克都市里的迷醉霓虹,以假乱真的猛犸象穿越雪原,纸鸢如鸟群一般翱翔在天空。
直到 24 年底,带着彼此「穿模」的物体、满是六根手指的手、走样到无法辨认的人脸,Sora 模型真的来了。用户期待着能像年初的预告视频里那样随意生成绚丽而真实的画面,得到的却是需要大量抽卡才勉强能用一个抽象短视频生成器。
有一说一,OpenAI 的确在 24 年这视频的一开头就明确表示,当时的 Sora 还只是一个研究项目。但这条视频所营造出的「现象」,所塑造的认知,直到去年 Sora 2 正式上线才算勉强兑现。
后来的事情大家都知道了:如今 Sora 项目已经彻底关闭,标志着 OpenAI 暂时退出了视频生成模型的赛道。
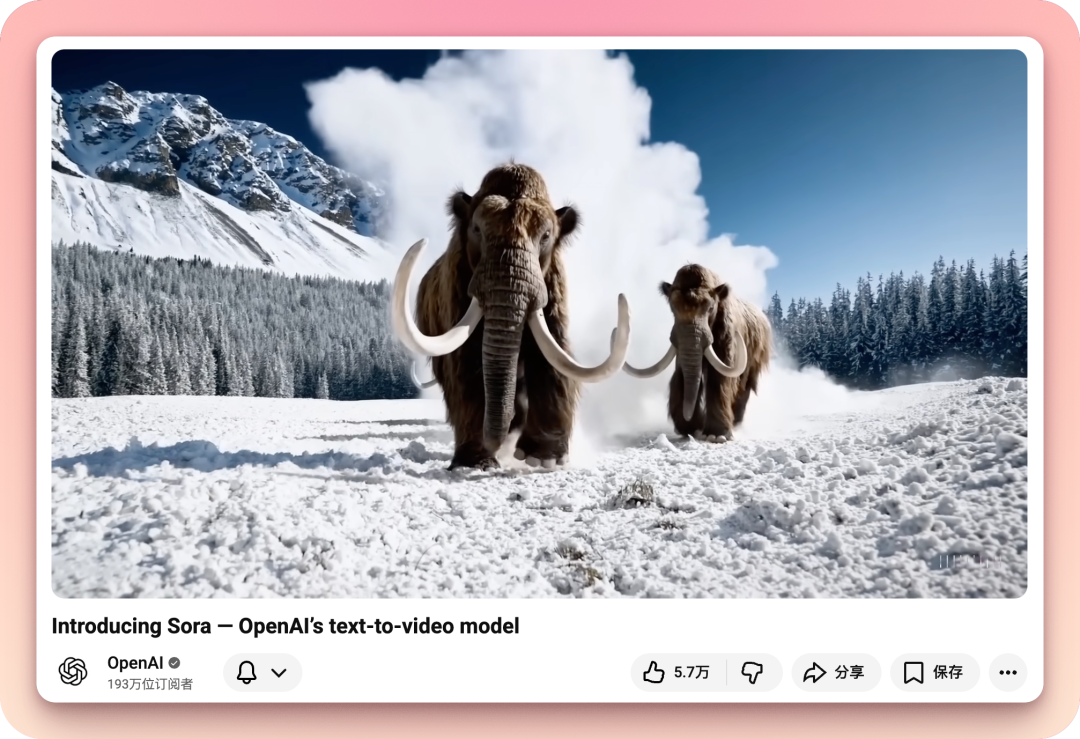
Sora 走完了属于它的生命周期。但它所验证的「现象领先现实」这一顽疾,却仍然肆虐着整个 AI 行业。
没有一片雪花是无辜的
当下这种情况,并不是凭空出现的,不同角度的行业人士参与到其中,而每个参与者都有自己的目的——最终形成共谋。
AI 公司的产品经理、市场营销与公关撰写新闻稿,在种种基准测试中找到最有说服力的数字。这些公司的创始人和高管,更是极为擅长通过演讲、播客、推文去营造 FOMO(错失焦虑),让失业的恐慌(无论是否真实)笼罩在舆论的头顶。
然后,媒体和自媒体网红们,通过一条又一条的文章、推文、视频、播客,将上述所有信息进行咀嚼、吞咽、反刍、排出。
行业常说模型即产品。但在更高的维度上,你会发现产品早已不是模型本身,而是环绕在模型周边的「外围系统」。
是一代更比一代高的基准测试分数,更是一篇又一篇以「地震」「海啸」「雪崩」为标题,宣告着「AGI 奇点到来」,令人「头皮发麻」「大出血」「冷汗直流」「吓出癫痫」的 AI 网红帖文和媒体报道文章。
模型不再是产品,现象才是产品。现实不再构成现象的要件,现象变成了新的现实。

延伸阅读:AI圈炒作圣经震撼首发 by 葬 AI
作为一个 AI 媒体的典型作者,我会在使用一个模型不到短短一天(大部分时候可能几个小时就够了)后给它打上「最强模型」的标签;当 GPT 的版本号从 4 进化到 5 的时候,我敢于不假思索就宣称新模型比 GPT-4 实现了这样或那样的进步。「碾压」「颠覆」「炸裂」在我的词汇表里,早已通货膨胀到不值一文。
合上电脑的时候,我经常陷入自我怀疑:今天写的文章在多大程度上经得住回头的事实考验?我有没有真正准确、负责任地描述这个 AI 模型或产品的创新性和实用意义?
究其根本,我们每天报道这个新模型,那个新产品,这样或那样的新技术变革,早已不再单纯因为它们有多少,甚至压根有没有创新性和实用意义了。
实际上,我们每天做这些报道,往往单纯是因为产品发布即将发生,而 AI 科技媒体如果不报道这些产品发布,如果不用这些词汇去写报道,报道就无法被推荐、点击、阅读、分享,就将落后于他人。
在今天,在这个 AI 营销模式下,没有哪个从业者可以不用随波逐流。是的,即便是 APPSO 也无法幸免。每一家媒体,每一个 AI 网红博主,都在为这个「无限进步」的循环贡献着自己或大或小的推力。
我们写了 Opus 4.7 是最强模型;转头我们又写了Opus 4.7 降智。这些观点看似相互矛盾,可它们都来自于事实——但它们又绝非全部和唯一的事实。时间长了你就习惯这种左右脑互搏了。
在每一个时间点上,这些观点都击中了舆论的某种偏好或审美,符合当下的「时代精神」,所以自然会有前仆后继的媒体和博主去不断发表、增幅这些观点,引发争议,获取流量。
作为读者,你不应该期待今天看完这篇文章之后,明天不再看到它所批评的那种文章发表在 APPSO 上。甚至这篇讽刺的文章,本身也成了它所讽刺的对象。如果不是因为 Opus 4.7 的发布,和看到了后续的争议,我不会写这篇文章。
我们能最终逃离这个循环吗?
也不是完全没有希望。
Claude、GPT 这样的模型,关注度足够高,用户足够多。在发布之后的第一时间里(通常在一两个小时内), 我们能够看到一些真实用户的评测体验,特别是那些站在营销话术的对立面的真实报告。可以说,情况还是有转机的。
令我印象最深的其实是 GPT-4o 下线和 GPT-5 的发布。
人们对新的 GPT 大版本期待已久,山姆·奥特曼本人对模型做出「专家级别的智能」这一评价,以及那条经典的「死星」推文居功甚伟。
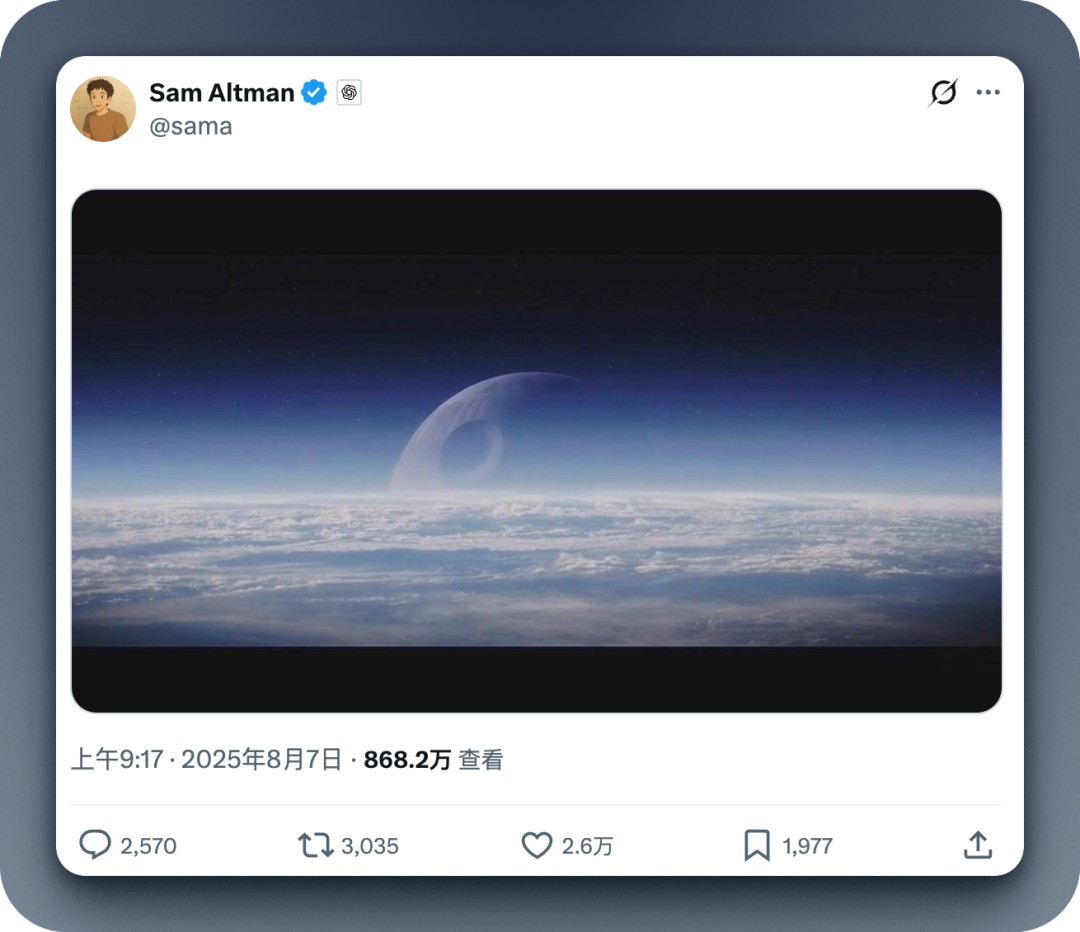
紧接着,GPT-5 真的来了,却在 X、Reddit 等平台上引发了排山倒海的反向舆论。「降智」「不如 4o」「还我 4o」的声音此起彼伏。预测市场 Polymarket 上当时有一个预测标题是「哪家公司到 8 月底能拿出最强模型」,OpenAI 在里面的比例在 GPT-5 发布后的短短一个小时内从百分之七十多降低到了十几。
顶不住压力的 OpenAI,不得不把下线的 4o 又给搬回来。
然而这个循环还是没能破灭:GPT-5 的小版本接二连三地推出,发布和更新的周期从年逐渐加速到以月为计。 4o 限时返场后最终还是下线,成为了滚滚向前的车轮压过的一粒石子。
考虑到 Opus 4.7 赚足了眼球,而 OpenAI 已经好长时间(在今天的周期里简直是度日如年)没有上线新模型了,传闻中的「Spud」,以及即将在今年内发布的 GPT-6,都将在它们各自专属的时段内成为「最强模型」,这件事已成定局。
上轮反省还没结束,新的周期已然开始。
当你读完这篇文章,关掉页面,刷新了一下朋友圈、公众号列表或者 X,会看到又一篇讲述新模型的文章发表了,可能是 DeepSeek V4、Kimi 2.6、Hunyuan 3 或者 GPT 5.5,甚至可能是真正到来的 Mythos。
这些文章的标题,会有同样的炸裂词汇。你在正文里,将看到「最强模型」的各种分数一而再、再而三地被刷新。
你以为这个新模型将会是绝杀,成为 the last model to end all models……
但那又怎样?在北京的知春路,在杭州的汇金国际,在旧金山的 Mission Bay 和 Market St.,比最新的周期还要更新的一轮,早已转动起来。
文|杜晨







