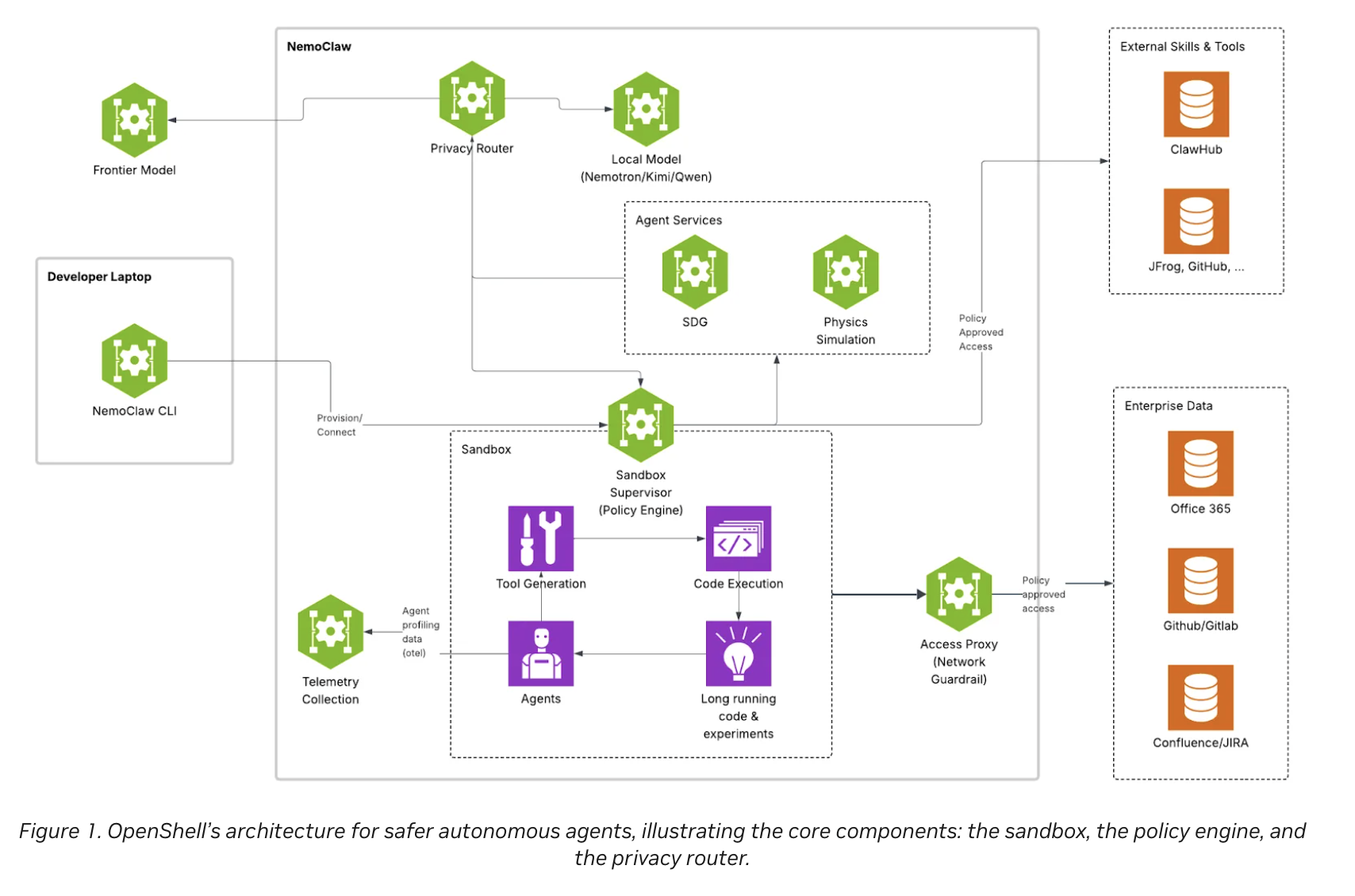
Large language models (LLMs) are transitioning from conversational to autonomous agents capable of executing complex professional workflows. However, their deployment in enterprise environments remain
The deployment of autonomous AI agents—systems capable of using tools and executing code—presents a unique security challenge. While standard LLM applications are restricted to text-based interactions
Google has officially released the Colab MCP Server, an implementation of the Model Context Protocol (MCP) that enables AI agents to interact directly with the Google Colab environment. This integrati
NVIDIA has announced the release of Nemotron-Cascade 2, an open-weight 30B Mixture-of-Experts (MoE) model with 3B activated parameters. The model focuses on maximizing ‘intelligence density,’ deliveri
In this tutorial, we explore how to solve differential equations and build neural differential equation models using the Diffrax library. We begin by setting up a clean computational environment and i
The dream of recursive self-improvement in AI—where a system doesn’t just get better at a task, but gets better at learning—has long been the ‘holy grail’ of the field. While theoretical models like t
In this tutorial, we explore the capabilities of the pymatgen library for computational materials science using Python. We begin by constructing crystal structures such as silicon, sodium chloride, an
The current state of AI agent development is characterized by significant architectural fragmentation. Software devs building autonomous systems must generally commit to one of several competing ecosy
The scaling of inference-time compute has become a primary driver for Large Language Model (LLM) performance, shifting architectural focus toward inference efficiency alongside model quality. While Tr
In the field of generative AI media, the industry is transitioning from purely probabilistic pixel synthesis toward models capable of structural reasoning. Luma Labs has just released Uni-1, a foundat
In this tutorial, we build an uncertainty-aware large language model system that not only generates answers but also estimates the confidence in those answers. We implement a three-stage reasoning pip
In the current landscape of Retrieval-Augmented Generation (RAG), the primary bottleneck for developers is no longer the large language model (LLM) itself, but the data ingestion pipeline. For softwar
When running LLMs at scale, the real limitation is GPU memory rather than compute, mainly because each request requires a KV cache to store token-level data. In traditional setups, a large fixed memor
Over the past year, AI agents have evolved from merely answering questions to attempting to get real tasks done. However, a significant bottleneck has emerged: while most agents may appear intelligent
Google has released Gemini 3.1 Flash Live in preview for developers through the Gemini Live API in Google AI Studio. This model targets low-latency, more natural, and more reliable real-time voice int
AI报告
电话咨询
在线咨询
 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库