Stanford researchers have introduced OpenJarvis, an open-source framework for building personal AI agents that run entirely on-device. The project comes from Stanford’s Scaling Intelligence Lab and is
Most LLM agents work well for short tool-calling loops but start to break down when the task becomes multi-step, stateful, and artifact-heavy. LangChain’s Deep Agents is designed for that gap. The pro
Why Document OCR Still Remains a Hard Engineering Problem? What does it take to make OCR useful for real documents instead of clean demo images? And can a compact multimodal model handle parsing, tabl
The gap between proprietary frontier models and highly transparent open-source models is closing faster than ever. NVIDIA has officially pulled the curtain back on Nemotron 3 Super, a staggering 120 b
In this tutorial, we build a workflow using Outlines to generate structured and type-safe outputs from language models. We work with typed constraints like Literal, int, and bool, and design prompt te
In this tutorial, we implement a Colab-ready version of the AutoResearch framework originally proposed by Andrej Karpathy. We build an automated experimentation pipeline that clones the AutoResearch r
IBM has released Granite 4.0 1B Speech, a compact speech-language model designed for multilingual automatic speech recognition (ASR) and bidirectional automatic speech translation (AST). The release t
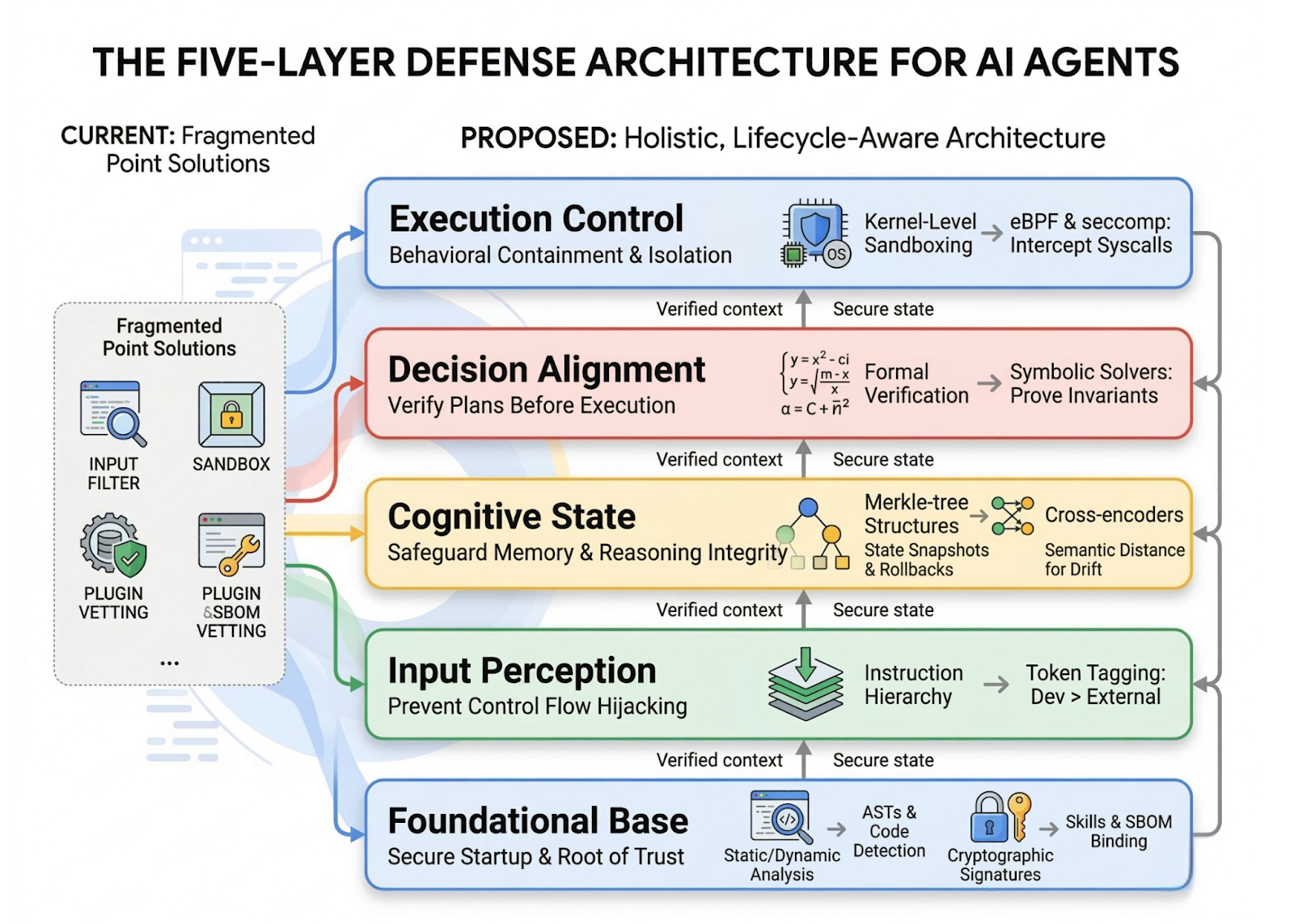
Autonomous LLM agents like OpenClaw are shifting the paradigm from passive assistants to proactive entities capable of executing complex, long-horizon tasks through high-privilege system access. Howev
The Baidu Qianfan Team introduced Qianfan-OCR, a 4B-parameter end-to-end model designed to unify document parsing, layout analysis, and document understanding within a single vision-language architect
Mistral AI has released Mistral Small 4, a new model in the Mistral Small family designed to consolidate several previously separate capabilities into a single deployment target. Mistral team describe
When you type a query into a search engine, something has to decide which documents are actually relevant — and how to rank them. BM25 (Best Matching 25), the algorithm powering search engines like El
The transition from a raw dataset to a fine-tuned Large Language Model (LLM) traditionally involves significant infrastructure overhead, including CUDA environment management and high VRAM requirement
Speech technology still has a data distribution problem. Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) systems have improved rapidly for high-resource languages, but many African languag
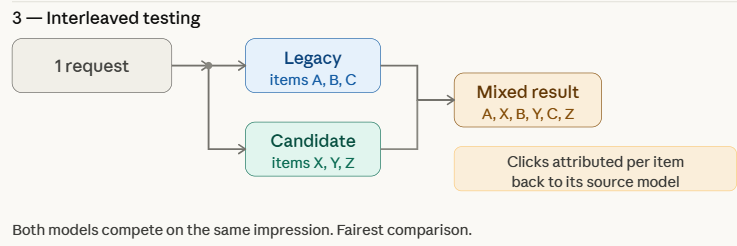
Deploying a new machine learning model to production is one of the most critical stages of the ML lifecycle. Even if a model performs well on validation and test datasets, directly replacing the exist
In this tutorial, we explore how to use NVIDIA Warp to build high-performance GPU and CPU simulations directly from Python. We begin by setting up a Colab-compatible environment and initializing Warp
AI报告
电话咨询
在线咨询
 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库