定价权,最终会落在谁手上?作者 | 姚赟来源 | 盒饭财经(ID:daxiongfan)头图及封面来源 | 网络及即梦制作4.69万亿Token,是什么概念?根据澎湃新闻报道,Seedance 2.0生成一条720p、15秒的标准视频,大约消耗 30.888万Token。4.69万亿Token除以30.888万,约等于1520万条15秒短视频。1520万条15秒视频,总时长约2.28亿秒,也就是大
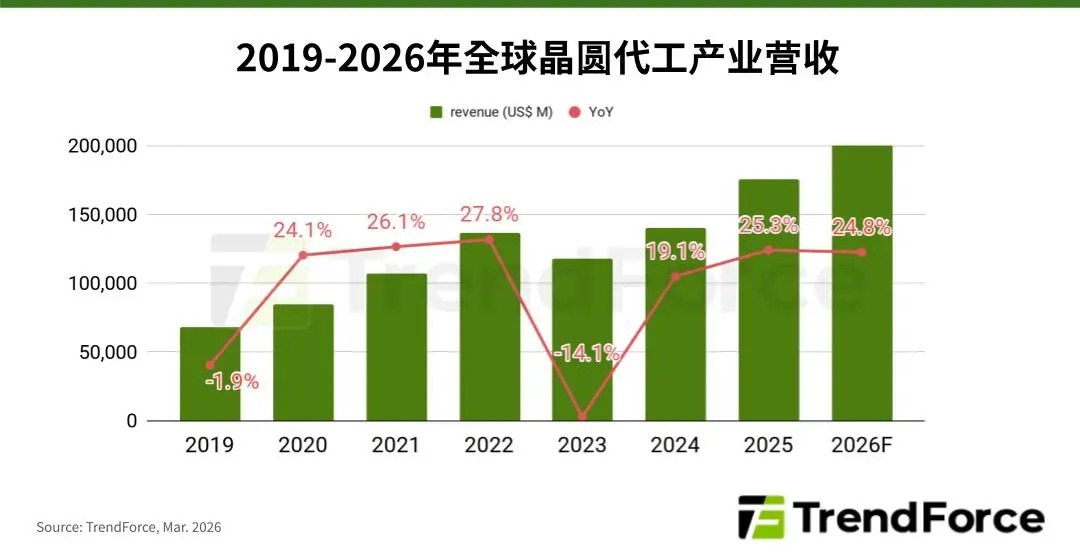
本周,半导体行业的关键词无疑是“涨价”。但与以往周期性波动不同,本轮涨价呈现出鲜明的“结构性”特征——AI需求成为绝对的主导力量,将产业链推入了一个前所未有的紧平衡状态。01、晶圆代工:先进制程满产,成熟制程跟涨3月18日,TrendForce集邦咨询发布的最新报告指出,在北美CSP(云服务提供商)和AI新创公司的持续投入下,2026年全球晶圆代工产值有望年增近25%,达到约2188亿美元。其中,
免责声明:本号内容仅作交流学习,非商用,侵权可联系15150147049微信删除,未经允许禁止转载,违者将依法追究相关责任。近日杭州市滨江区人民法院发布破产审查公告,正式受理对杭州泰昕微电子有限公司的破产审查申请,案号为(2026)浙0108破申25号。这意味着这家曾专注于IGBT、SiC功率模块研发的国产芯片企业,已陷入司法程序中的困境,成为国内功率半导体行业整合洗牌期的又一代表性案例。公开信息
“芯”闻摘要美光18亿美元收购案完成2026年晶圆代工产值预测国内半导体厂商大动作!2大半导体巨头官宣合作铠侠宣布停产消息俄罗斯光刻机研发传新进展1美光18亿美元收购案完成当地时间3月16日,存储大厂美光科技宣布已完成对力积电(PSMC)位于中国台湾地区苗栗县铜锣P5厂区的收购案。该交易的完成,标志着双方正式落实了于2026年1月17日宣布的收购协议。铜锣厂拥有约30万平方英尺的300mm独立无尘
在长三角产业协同发展的浪潮中,合肥凭借前瞻的战略布局、独特的“国资+产业+资本”联动模式,从曾经的“缺芯少屏”困境,成长为中国半导体产业的核心城市之一,被誉为“中国IC之都”。如今,这座坐拥国家综合性科学中心资源的城市,已构建起从芯片设计、晶圆制造、封装测试到设备材料的完整产业链,形成了以存储芯片、显示驱动芯片为两大支柱,功率半导体、汽车电子芯片协同发展的产业格局,成为推动国内半导体产业自主可控、
作为我国西部地区集成电路产业的核心增长极,西安正以全产业链布局、头部企业集聚、创新生态完善的强劲态势,跻身全国半导体产业第一梯队,成为支撑国产芯片自主可控、保障产业链供应链安全的关键战略支点。依托深厚的科教底蕴、完备的工业基础与政策精准赋能,西安已构建起覆盖集成电路设计、晶圆制造、封装测试、功率器件、存储芯片、通信芯片、航天电子、光芯片、第三代半导体的完整产业生态,打破了区域产业链环节缺失的瓶颈,
2026年,全球半导体产业站在了“后全球化”时代的分水岭。AI算力的狂热需求与地缘政治的冷峻现实激烈对撞,成熟制程的“长尾效应”与先进封装的“乐高革命”正在重塑产业链价值。在这样的大背景下,中国IC设计产业的攀峰之路,下一步该迈向何方?3 月 31 日 - 4 月 1 日上海浦东丽思卡尔顿酒店,这场半导体产业盛会不仅打造了2 大主峰会 + 4 大垂直技术论坛的硬核议程,更设置了全产业链特色展区,汇
会议推荐2026年第二届玻璃基板与光电融合技术峰会——从TGV工艺到CPO集成主 办 单 位:半导体在线时间和地点:4月9-10日(8日签到)东莞 扫码报名参会 过去几年,摩尔定律已经转向先进封装技术,但这种方法的局限性现在才逐渐显现出来。人工智能和高性能计算的设计规模越来越大,结构越来越复杂,这使得封装力学和工艺控制不再仅仅成为衡量互连密度的瓶颈,而是成为下一个挑战。随着结构变得更薄、更大、更异
3月21日消息,在刚刚结束的华为中国合作伙伴大会2026上,华为重磅发布并展出了搭载全新昇腾950PR(Ascend 950PR)处理器的AI训练推理加速卡Atlas 350,并宣布该加速卡正式上市。△Atlas 350加速卡(图片来源:上海证券报)根据华为此前公布的资料显示,昇腾950PR芯片于今年一季度推出,基于SIMD架构,算力达到1PFLOPS(FP8)/ 2PFLOPS(FP4),支持F
当地时间3月21日晚间,特斯拉、SpaceX、xAI CEO埃隆·马斯克(Elon Musk)正式公布了此前已经预告的“TeraFab”晶圆厂项目。据介绍,这座被称为“全球最大2nm先进芯片工厂”的超级设施,将落户美国德克萨斯州奥斯汀,将成为人类算力史上的新里程碑。根据马斯克此前公布的信息,这座TeraFab将采用2nm顶尖工艺制程,将芯片设计、制造、封装全流程整合在同一园区,该工厂的目标是每月生
在高性能计算与信号处理领域,浮点运算能力是衡量硬件加速效率的核心指标。AMD UltraScale+架构凭借其增强的DSP Slice设计,为浮点运算优化提供了突破性解决方案。本文将深入解析该架构如何通过硬件架构创新与软件协同设计,实现浮点运算性能的显著提升。 DSP Slice的硬件进化 UltraScale+架构中的DSP48E2 Slice是浮点运算的核心引擎。相较于前代架构,其关键升级体现
在物联网设备智能化浪潮中,将深度学习模型部署到NXP i.MX RT系列等资源受限的嵌入式平台,已成为推动边缘计算发展的关键技术。本文以PyTorch模型为例,详细阐述从量化优化到移植落地的完整技术路径。 一、模型量化:精度与效率的平衡艺术 PyTorch提供动态量化、静态量化、量化感知训练三种主流方案。以动态量化为例,其核心优势在于无需校准数据即可实现模型压缩: python import to
在物联网设备开发中,电池续航能力直接影响产品竞争力。通过RTC(实时时钟)唤醒与电源门控技术的协同应用,可让设备在大部分时间处于"深度睡眠"状态,将功耗降低至微安级别。本文以STM32L4系列为例,详细阐述实现路径。 一、RTC唤醒机制实现 RTC模块可在设备休眠时持续运行,通过配置闹钟中断实现周期性唤醒。关键步骤如下: c // RTC初始化配置(以STM32L4为例) void RTC_Ini
在工业4.0的浪潮中,数字孪生技术正重塑硬件开发流程。传统的电路仿真往往依赖庞大的本地软件,不仅安装繁琐,且难以实现远程协作。如今,借助WebAssembly(WASM)的高性能特性,将SPICE类仿真引擎直接搬入浏览器,已成为构建轻量级数字孪生前端的bi然选择。这种架构让工程师只需打开网页即可进行电路设计与验证,真正实现了“随处仿真”。 架构革新:从原生到Web的跨越 浏览器端仿真的核心挑战在于
在硬件加速的星辰大海中,FPGA(现场可编程门阵列)宛如一颗璀璨的明珠,以其无与伦比的并行计算能力和灵活性,成为打破摩尔定律瓶颈的“破局者”。然而,昂贵的硬件成本与漫长的开发周期曾让无数开发者望而却步。如今,AWS F1实例的出现,将这颗明珠镶嵌在了云端,让硬件加速变成了一种即开即用的“水电煤”资源。这不仅是技术的进步,更是计算范式的深刻变革。 云端启航:从AMI到AFI的奇幻漂流 一切始于AWS
AI报告
电话咨询
在线咨询
 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库